서버 가상화
- 하나의 물리적 서버 리소스에 여러 개의 서버 환경을 할당
• 각각의 환경에 OS와 애플리케이션을 실행할 수 있도록 함 - 물리 서버의 수가 줄어들기에 공간 절약과 비용 절감 효과
- 가상 서버 중 하나가 위협에 노출되더라도 다른 가상 서버에게 영향을 미치지 않음

- Intrusion Tolerance (악의적인 공격으로부터 정보 시스템을 방어하기 위한 설계 접근 방식)
서버 가상화 기술
종류
- Type-1 Hypervisor
• 하드웨어 위에 바로 Hypervisor 가 동작
• Native 또는 Bare-metal Hypervisor 라고도 함
• 호스트 운영체제가 없기 때문에 리소스 관리가 유연
• 자체적인 물리 머신 관리 기능이 제한적임
컴퓨터에 VirtualBox를 깔거나 Hypervisor를 깔고 돌리면 이미 Host OS가 리소스를 많이 사용하기 때문에 Host OS를 없애고 가벼운 마이크로 커널과 하이퍼바이저를 두면 자원을 효율적으로 사용이 가능
- Type-2 Hypervisor
• 호스트 운영체제 위에 Hypervisor가 동작
• '호스트 운영체제 – Hypervisor – 가상 머신' 간 HW Emulating 과정으로
오버헤드가 많이 발생
• 하지만 Type-1에 비해 관리가 용이
HW Emulating: 실제 물리적인 하드웨어의 기능이나 동작을 소프트웨어적으로 재현하는 것
가상머신이 실제 물리 디바이스(CPU, 메모리) 등을 쓸때 하드웨어에 대한 에뮬레이팅을 해줘야 하는데 (실제 접근 불가하니) 여기서 오버헤드가 많이 발생한다.
운영체제의 관점에서 하이퍼바이저를 어떻게 동작할까? => 이부분을 이해하기위해 OS를 알아야 할 필요가 있다.
운영체제의 역할
1. 여러 개의 사용자 애플리케이션에게 하드웨어 가상화를 제공
2. 사용자가 하드웨어를 쉽게 사용하기 위한 추상화 및 API 제공
- Process, Memory Space, File System, System Calls
3. 제한된 하드웨어 자원에 대한 원활한 공유
- Scheduling, Process State
4. 접근 제어 및 권한을 활용한 하드웨어 자원 보호
- Privilege, Permission
5. 사용자 애플리케이션 간의 격리 (Isolation)
- Protection Domain, Context Switch
사용자가 하드웨어를 쉽게 사용하기 위한 추상화 및 API 제공
운영체제 추상화
- 프로세스, 스레드 -> cpu execution
초기의 운영 체제는 프로세스 레벨에서 스케줄링을 수행했다. 여기서 프로세스란 '실행 중인 프로그램'의 인스턴스를 의미한다. 프로세스 각각은 독립된 메모리 영역(주소 공간)을 가지고 있으며, 운영 체제의 스케줄러는 이러한 프로세스들 사이에서 CPU 시간을 할당한다. 초기에는 프로세스가 실행의 기본 단위였기 때문에, 스케줄링도 이러한 프로세스 단위로 이루어졌다.
시간이 지나면서, 프로그램을 보다 효율적으로 실행하기 위한 방법으로 멀티스레딩이 등장했다. 스레드는 '프로세스 내에서 실행되는 여러 실행 흐름 중 하나'로, 같은 프로세스 내의 스레드들은 메모리와 자원을 공유한다. 스레드 레벨 스케줄링은 운영 체제가 프로세스 내의 개별 스레드를 스케줄링하는 것을 의미한다. 이로 인해 프로그램은 병렬로 여러 작업을 동시에 수행할 수 있게 되어 효율성이 증가했다.
즉, 모든 실행이 프로세스로 추상화가 되었고 좀더 세분화되어 스레드 형태로 추상화가 되었다.
- Address Space (Virtual memory) -> Memory (DRAM)

피지컬 메모리에 직접적인 접근 대신에 각각의 어플리케이션들의 프로세스마다 별도의 virtual memory를 가지고 작업을 한다. 즉, 프로세스들 우리가 만든 프로그램들은 virtual memory 에서 동작을 하고
virtual memory에서 동작하는 것들이 실제로 OS가 주소 변환을 해줘서 피지컬 메모리로 가는것이다.
- Files & File System -> Storage (HDD, SSD)

파일시스템은 데이터를 파일로 조직화한다. 각 파일은 데이터의 논리적 컨테이너 역할을 하며, 파일들은 디렉토리(폴더)에 그룹화될 수 있다. 사용자와 응용 프로그램은 스토리지의 물리적인 복잡성과 구현 세부 사항을 신경 쓰지 않고 파일을 쉽게 저장하고 접근 가능하다.
x86에서의 프로그램 실행
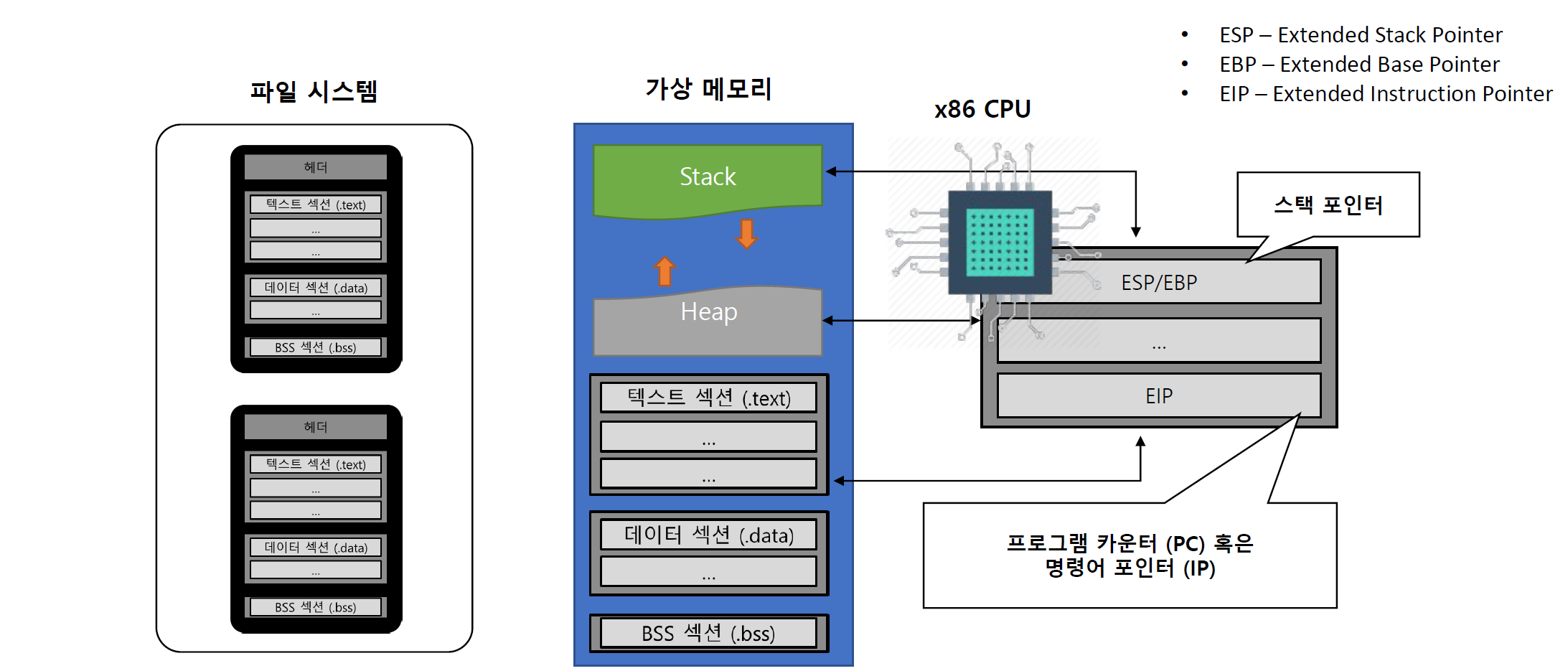
펀더멘탈 아키텍쳐(어떤 구조의 기본적이고 근본적인 설계를 의미)기반으로 쓰기 때문에 파일 시스템에서 프로그램을 가상메모리에 가져오고나서 cpu에 레지스터들을 사용하여 잘 실행이 되는것 이런 과정들이 OS가 추상화를 잘 해줘서 레지스터도 쓰게 하고 명령어도 실행하고 메모리도 사용하고 할 수 있는것이다. 이러한 모든 과정이 나중에 하이퍼바이저가 에뮬레이팅 해야 되는 과정이 된다.
사용자가 하드웨어를 쉽게 사용하기 위한 추상화 및 API 제공
추상화 #1 - 프로세스 (Process)

- 프로세스
• 실행 중인 프로그램
• 프로그램과 달리, 메모리에 주소 공간을 갖는 능동적 개체 - 프로세스가 제공하는 Abstraction
• 자신만의 Address Space
• Virtual CPU
• 해당 프로세스에 대응되는 프로그램 파일 - 프로세스 제어 블록 (Process Control Block: PCB)
• 프로세스 관리를 위해 유지되는 메타데이터
• CPU에서 Context Switch가 발생할 때 PCB 정보를 활용
- Executed Application을 OS에서는 Process라는 Abstract을 통해 정의
• 프로세스 별 고유의 가상 메모리 영역(Memory Segment)를 사용
• Thread 별로 Context(e.g., stack)를 관리하여 원활한 Suspend/Restart를 수행
• OS는 PCB라는 Data Structure를 통해 여러 개의 프로세스를 원활히 관리
OS가 실행중인 어플리케이션을 프로세스라는 추상적인 개념을 통해 관리하고 정의한다는 뜻이고
OS가 스레드의 상태를 저장하고 관리하여 스레드를 중단/재시작 작업을 원할하게 수행한다.
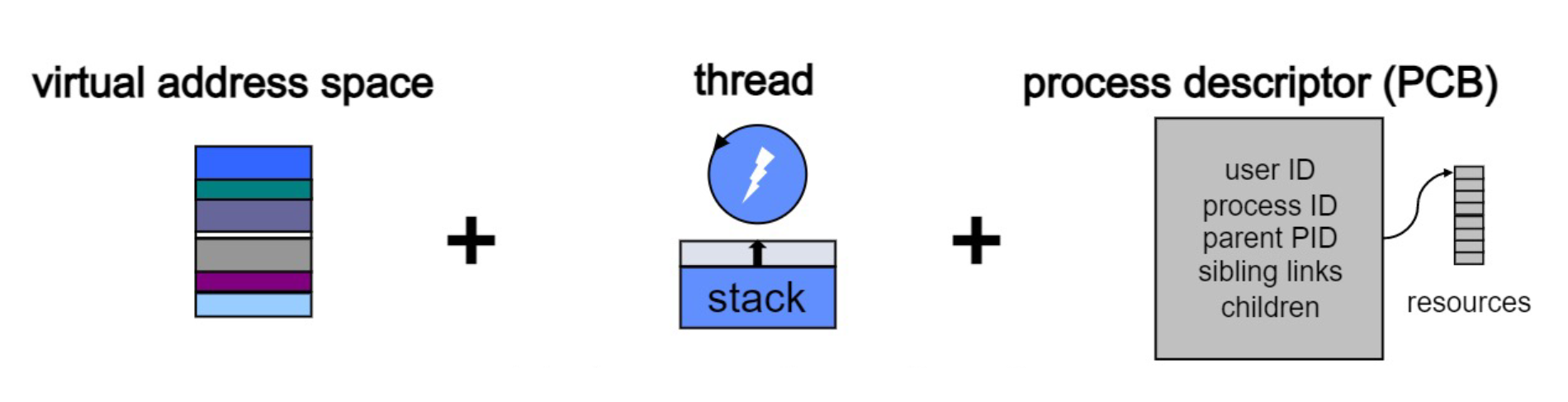
프로세스는 프로그램의 실행을 나타내는 주요 단위이다. 운영 체제는 프로그램의 코드, 데이터, 그리고 실행 상태를 포함하는 독립적인 실행 흐름으로서 프로세스를 추상화한다.
프로세스는 고유한 가상 주소 공간을 가진다. 프로세스가 실제 물리 메모리의 위치나 다른 프로세스의 메모리 할당을 걱정하지 않고 독립적으로 작동할 수 있게 해준다.
프로세스는 운영 체제로부터 CPU 시간, 메모리 공간, 파일 핸들, 네트워크 연결과 같은 시스템 자원을 할당받는다. 운영 체제는 이러한 자원들을 관리하고 각 프로세스에 공정하게 분배하여, 각 프로세스가 필요한 자원을 사용할 수 있도록 한다.
추상화 #2 - 메모리 주소 공간 (Address Space)
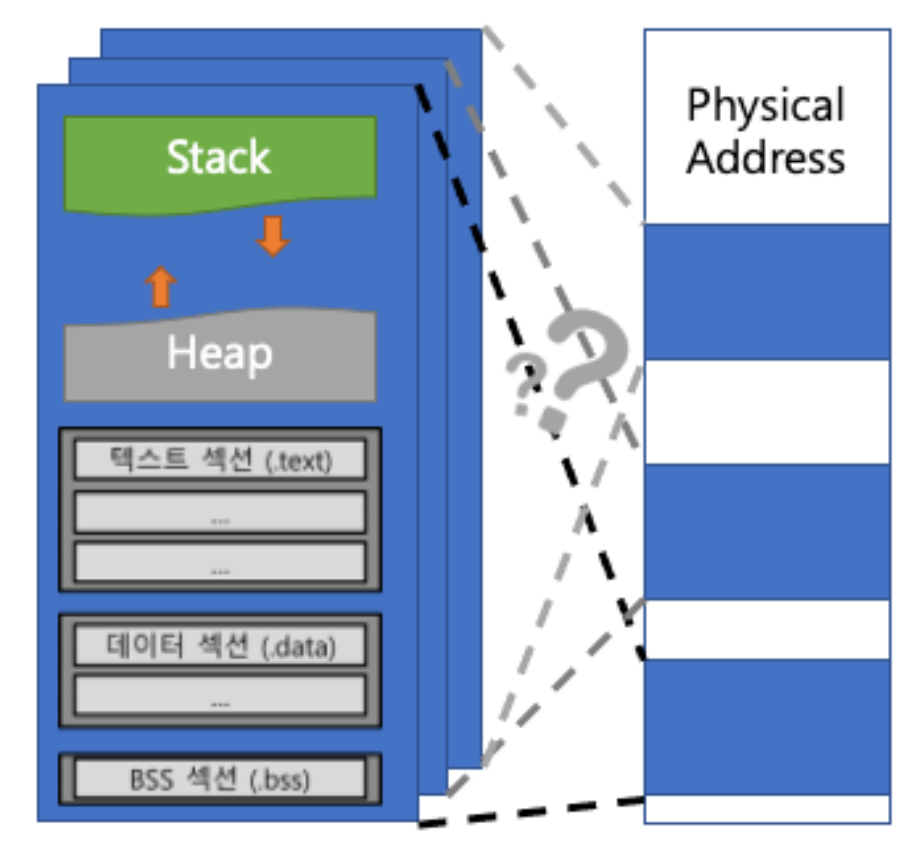
- (Process) Address Space
• 프로세스 별로 할당된 가상 주소 공간 - 제한된 물리 메모리에 어떻게 매핑?
• Address Translation (with MMU)
• Swap - 어떻게 효율적으로 매핑 관리?
• TLB, Paging
제한된 물리 메모리 매핑
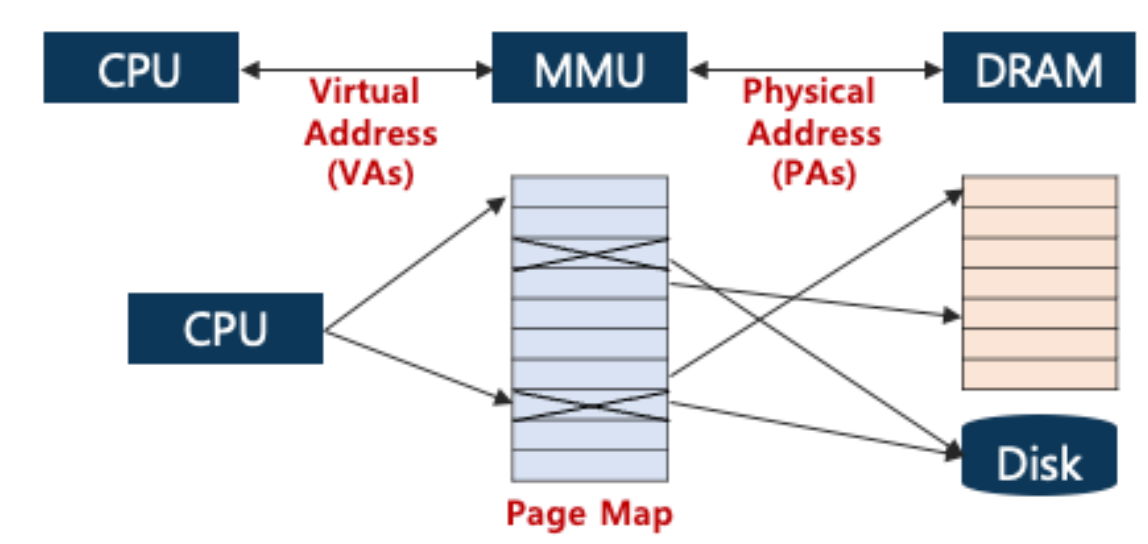
1. Address Translation(주소 변환) with MMU
CPU가 생성하는 주소(가상 주소)를 실제 물리 메모리 주소로 변환하는 과정 -> 이변환을 주로 MMU(메모리 관리 유닛)에 의해 수행된다.
2. Swap
물리 메모리가 부족할 때, 운영체제는 사용되지 않는 메모리 페이지(데이터의 블록)를 스왑 영역(하드 드라이브 또는 SSD의 일부분)으로 이동시킨다. (요즘은 잘 사용x)
효율적 매핑 관리
1. TLB (Translation Lookaside Buffer)
TLB는 CPU 근처에 위치한 작은, 빠른 캐시 메모리 -> 가장 최근에 참조된 페이지 테이블 항목의 복사본을 저장한다.
TLB의 목적은 메모리 주소 변환 과정을 가속화하는 것
2. Paging
물리 메모리를 고정된 크기의 블록(페이지)으로 나누고, 가상 메모리도 동일한 크기의 페이지로 나누는 메모리 관리 기법
가상 머신 자체가 이미 가상 메모리 안에서 동작을 하는데 Host os 안에 Guest os가 있고 그 안에 프로그램이 돌아간다. 여기서 우리가 physical memory 를 가지고있는데 Host os도 virtual memory space를 가지고 있고
Guest os도 virtual memory space를 가진다.
즉, 실질적인 접근을 하려면 memory space가 여러번 바뀌어야 한다. (Guest os 입장에서 Host os의 virtual memory space가 physical Memory Space 인셈)
Q: Guest os가 Host os를 physical memory 로 인식하면 그사이에 페이징이나 이런걸 다 진행하나?
A: 다 한다. Guest os도 os니까 Host os와 하이퍼바이저(또는 가상 머신 모니터)는 physical memory를 관리한다. 이들은 Guest os가 사용하는 virtual memory를 호스트 머신의 실제 물리적 메모리에 매핑한다.(with MMU) 이 과정에는 여러 가지 메모리 관리 기법이 포함될 수 있으며, 이 중 하나가 페이지 매핑
추상화 #3 - 파일 시스템 (File System)
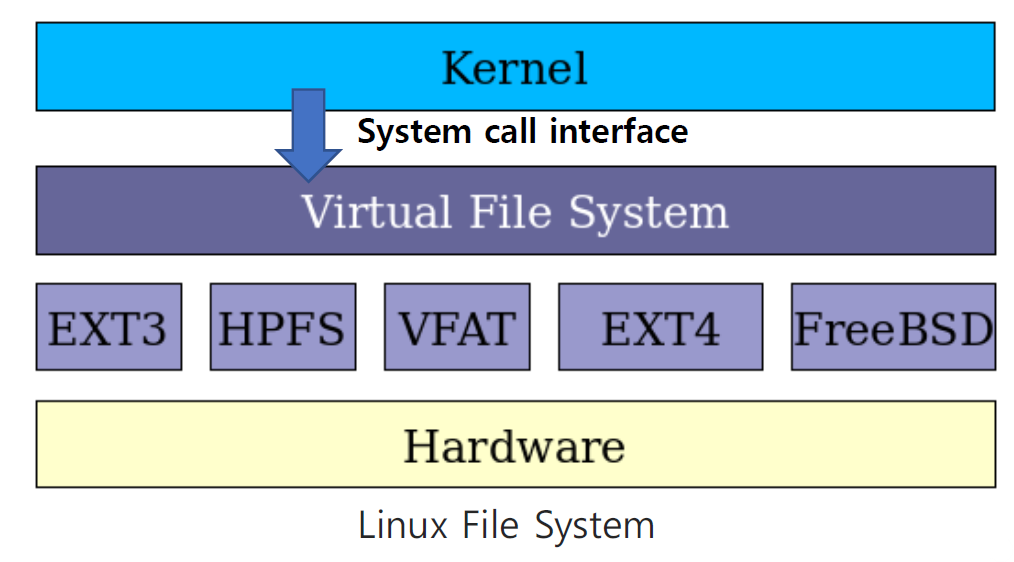
- File System을 통해 Secondary Storage를 추상화
- OS의 파일 시스템이 파일을 Physical Hardware와 매핑
- 파일을 Block이라는 단위로 구분하여 관리하고, Physical Block에 대한 매핑을 관리
- 파일의 Raw Data와 Metadata(소유자, 권한, 크기 등)를 함께 저장/관리
Raw Data는 i node에 포함된 포인터를 통해 접근
Metadata는 i node에서 관리
VFAT (Virtual File Allocation Table): 파일 시스템의 확장 버전, 주로 Microsoft Windows 운영 체제에서 사용
EXT4 (Fourth Extended File System): 리눅스 운영 체제에서 널리 사용되는 파일 시스템
FreeBSD:유닉스 계열의 운영 체제 중 하나
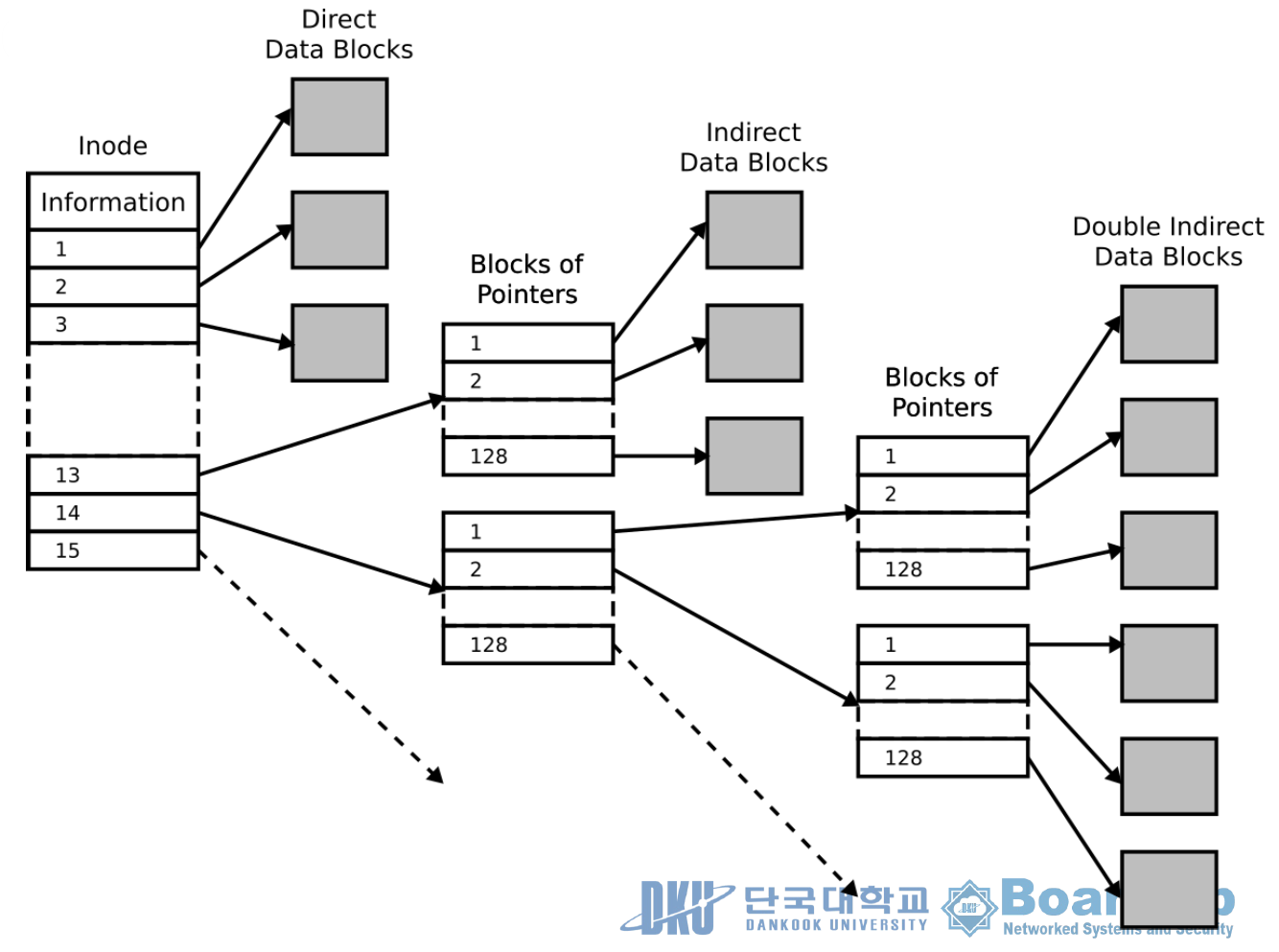
- 리눅스의 i-node : Index File Structure
- 저장할 때
• 순차 파일 구조로 저장 - 접근할 때
• 인덱스 테이블을 보고
원하는 파일에 직접 접근
제한된 하드웨어 자원에 대한 원활한 공유
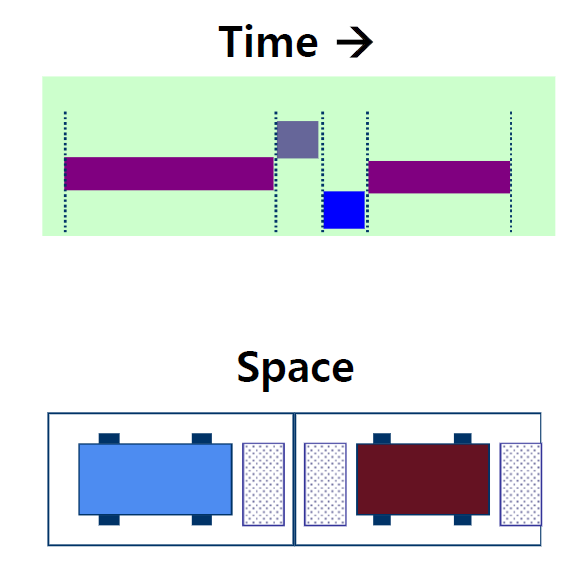
- 공유 자원의 종류
- Time sharing for executing instruction
- 제한된 CPU 코어 수를 공유
- Solution: Process State, Scheduling
- Space sharing for accessing code and data
- 제한된 메모리 영역을 공유
- Solution: Page Replacement, Swap
타임 쉐어링 시스템에 사용되는 주요 기법 및 알고리즘
- 라운드 로빈(Round Robin) :각 프로세스에 동일한 크기의 시간 할당량(타임 슬라이스 또는 타임 쿼럼)을 부여하고, 이 순서대로 CPU 시간을 순환적으로 할당
- Shortest Job First (SJF): 가장 짧은 실행 시간을 가진 작업(프로세스)부터 먼저 처리하는 방식
- 비선점형(non-preemptive sjf) , 선점형(preemptive sjf), 최소 잔여시간우선(srtf)으로 나뉨
- 우선순위 스케줄링(Priority Scheduling): 프로세스마다 우선순위를 할당하고, 높은 우선순위를 가진 프로세스부터 CPU 시간을 할당
- 타임 슬라이스(Time Slice) 조정: 시스템의 부하와 요구에 따라 각 프로세스의 타임 슬라이스 크기를 조정할 수 있다. 이를 통해 시스템의 응답성과 처리량을 최적화가능
스페이스 쉐어링 시스템 메모리 관리기법
- 페이징(Paging): 가상 메모리를 일정 크기의 페이지로 나누어 관리하는 기술, 실제 물리적 메모리 역시 페이지와 같은 크기의 프레임으로 나뉜다.
- 세그멘테이션(Segmentation): 메모리를 세그먼트(예: 코드, 데이터, 스택)로 나누어 관리하는 기법
- 페이징과는 다르게, 메모리를 논리적으로 구분하여 관리
- 페이지 교체 알고리즘(Page Replacement Algorithms): 메모리가 부족할 때, 어떤 페이지를 메모리에서 제거할지를 결정하는 데 사용되는 알고리즘
- LRU(Least Recently Used), FIFO(First In First Out), OPT(Optimal Page Replacement) 등등
Process Scheduling
- 운영체제 내 Scheduler가 어떠한 프로세스가 CPU를 점유할 것인지 결정
• 프로세스에 대한 State Machine을 설계
• State Transition을 통해 프로세스들을 관리
• Multi-thread Support를 위해 Thread Scheduling 수행
• Round Robin, Shortest Job First, Linux의 Completely Fair Scheduler -> 실제적으로쓰는 것
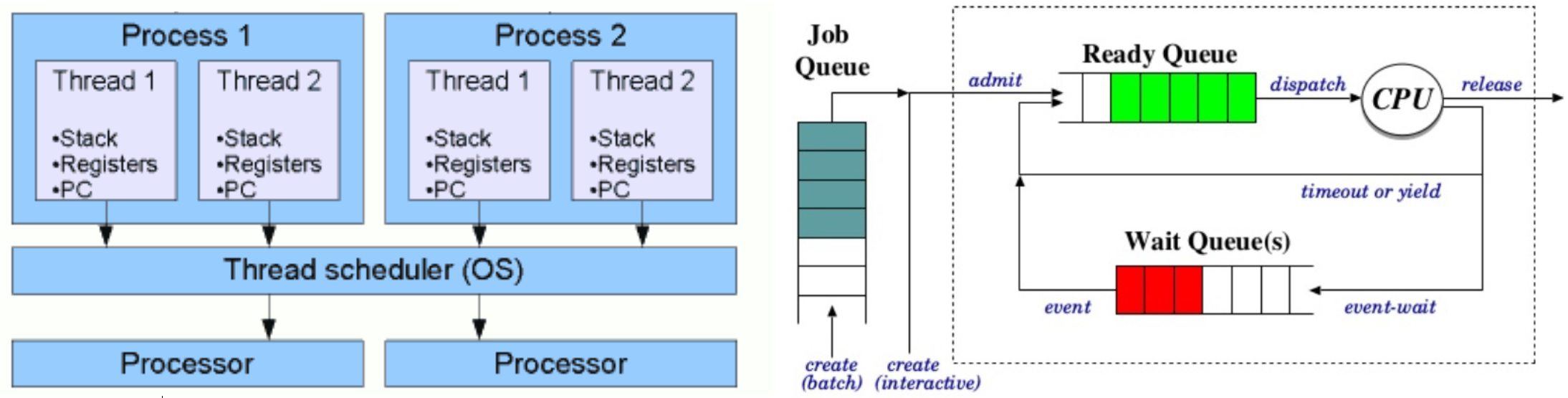
- 프로세스 생성: 사용자 또는 시스템에 의해 새로운 작업(프로그램 실행 등)이 요청되면, 운영 체제는 새로운 프로세스를 생성한다. 이때 프로세스는 초기 상태('new' 상태)가 되고, 필요한 리소스(메모리, 파일 핸들 등)를 할당받습니다.
- Job Queue: 생성된 프로세스는 일단 시스템의 Job Queue에 들어간다. 여기서 Job Queue는 시스템에 들어온 모든 프로세스를 관리하는 대기열
- Ready Queue: 프로세스가 시스템 리소스(예: 메모리)를 할당받고 실행을 준비하면, 'ready' 상태가 되어 CPU를 기다리는 Ready Queue로 이동한다.
- CPU 스케줄링: 운영 체제의 스케줄러는 Ready Queue에 있는 프로세스 중 하나를 선택하여 CPU를 할당합니다. 이 선택은 스케줄링 알고리즘(예: Round-Robin, Shortest Job First 등)에 따라 달라집니다.
- 스레드 스케줄링: 프로세스 안에는 하나 이상의 스레드가 있을 수 있다. 프로세스가 CPU를 할당받으면, 그 내부의 스레드들은 프로세스 내부 또는 운영 체제에 의한 스레드 스케줄러에 의해 스케줄링된다. 이때 각 스레드는 CPU에서 실행될 수 있도록 자신의 타임 슬라이스를 할당받게 된다.
- 실행과 스위칭: 할당된 시간 동안 스레드(또는 프로세스)는 CPU에서 실행된다. 실행 시간이 끝나거나 입출력 작업 등으로 인해 대기해야 하는 경우, 스케줄러는 다시 Ready Queue에서 다음 프로세스 또는 스레드를 선택하여 CPU를 할당한다.
Process State Transition
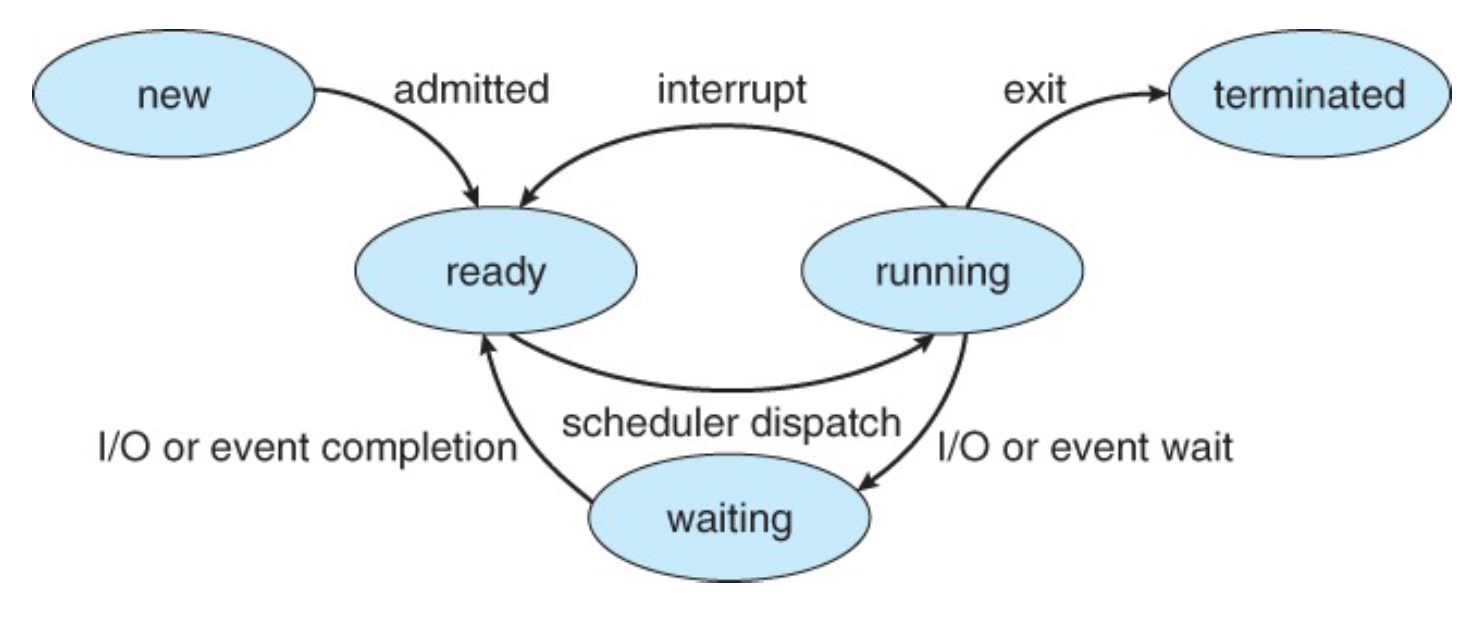
- New (신규): 프로세스가 생성되고 초기화되지만 아직 준비 상태 큐에 삽입되지 않은 상태
- Ready (준비): 프로세스가 CPU에서 실행될 준비가 되어 있으며, 실행을 위해 준비 상태 큐에 있는 상태
- Running (실행 중): 프로세스가 CPU를 할당받아 명령어를 실행하고 있는 상태
- Waiting (대기): 프로세스가 이벤트(예: 입출력 작업의 완료)를 기다리고 있는 상태, 이 상태의 프로세스는 실행을 계속할 수 없으며, 대기 상태 큐에 위치한다.
- Terminated (종료): 프로세스가 실행을 완료하고 시스템에서 제거된 상태
Context Switching
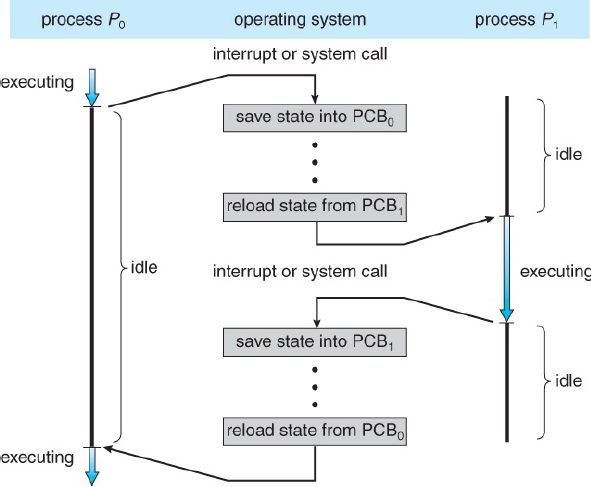
운영 체제가 한 프로세스(또는 스레드)의 실행을 중단하고 다른 프로세스(또는 스레드)를 실행하기 위해 수행하는 과정
- 현재 상태의 저장: 실행 중인 프로세스의 현재 상태(컨텍스트)를 저장한다. 이 컨텍스트에는 프로그램 카운터, CPU 레지스터 값, 메모리 관리 정보 등이 포함한다. 이 정보는 나중에 해당 프로세스가 다시 실행될 때 이전 상태를 복원하는 데 사용
- 다음 프로세스의 상태 복원: 다음에 실행할 프로세스의 컨텍스트를 복원한다. 이는 해당 프로세스가 이전에 중단된 지점부터 실행을 계속할 수 있도록 한다.
- 실행 전환: CPU의 제어권이 새로운 프로세스로 전환된다. 이때, 운영 체제의 스케줄러가 다음 실행할 프로세스를 결정하고, CPU는 이 프로세스의 명령을 실행하기 시작
컨텍스트 스위칭은 필요한 작업이지만, 오버헤드를 발생시킴
Page Replacement
- Page Eviction + Swap을 통해 제한된 메모리 영역을 효율적으로 활용
• 사용자는 실제 메모리의 크기 + 스왑 영역의 크기 = 전체 메모리로 인식
• 메모리 관리: Least Recently Used (LRU), Least Frequently Used (LFU)
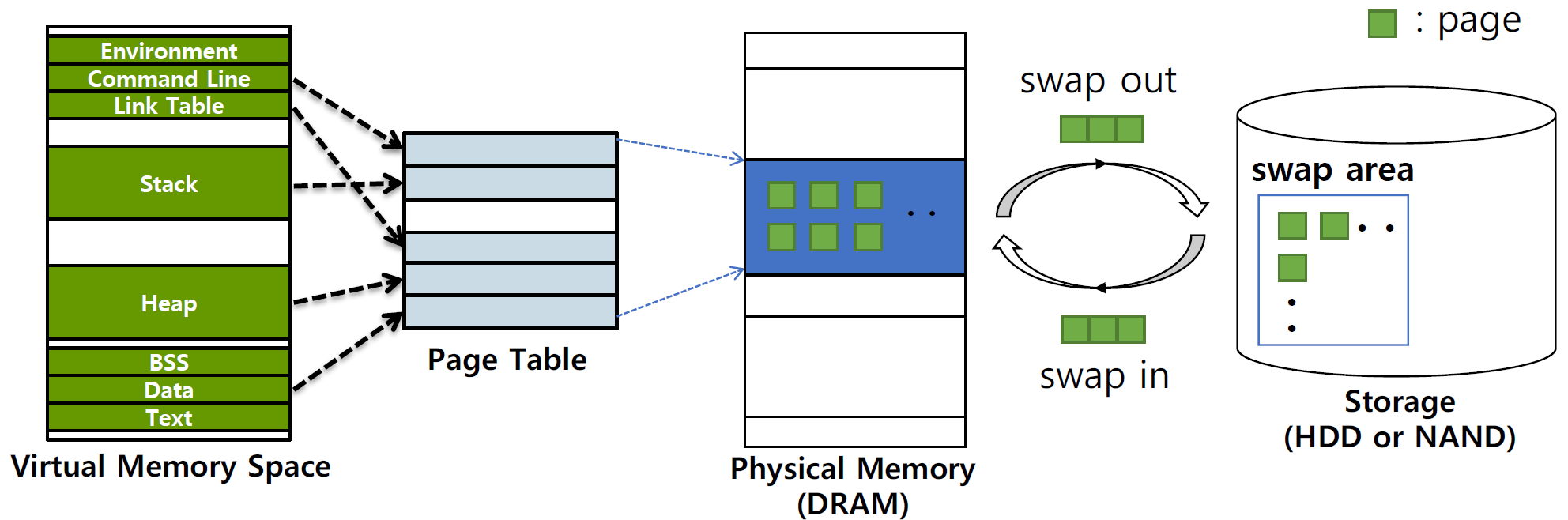
컴퓨터의 물리적 메모리(즉, RAM)는 제한되어 있기 때문에, 모든 프로그램의 모든 데이터와 코드를 동시에 메모리에 유지할 수 없다. 가상 메모리 시스템은 이 문제를 해결하기 위해 하드 드라이브의 일부를 메모리처럼 사용함 (swap은 잘안씀)
접근 제어 및 권한을 활용한 하드웨어 자원 보호
Strawman Design
- Privilege의 개념 없이 Software Stack과 Hardware만으로 구분
Problem1: Application이 다른 Application의 실행을 방해/종료 가능
- 원인: 모든 Application이 같은 Domain에서 실행됨
- 해결책: Introducing Protection Domain (Isolation)
Problem2: Application이 OS Subsystem을 Crash 가능
- 원인: 같은 권한 계층에서 OS와 Application이 실행
- Privilege Separation (ring 0 – ring 3 in Linux kernel)
Protection과 Isolation
- Protection Boundary의 선정 기준은 미리 정의한 Abstraction인 Process!
- Process의 메모리에 대한 Protection
• Virtual Address가 각 Process 별로 Private하게 만듦
• Context Switch 시 Virtual Address Space 또한 Switch - Process의 파일에 대한 Protection
• Permission System을 도입하여 파일들에 대한 접근을 보호
Privilege Separation
- 운영체제만이 Privileged Instruction을 실행할 수 있도록 권한 분리
- x86 Architecture Segment Descriptor의 Descriptor Privilege Level (DPL) bits

State-of-the-art Design = (Traditional Model (without Hypervisor))
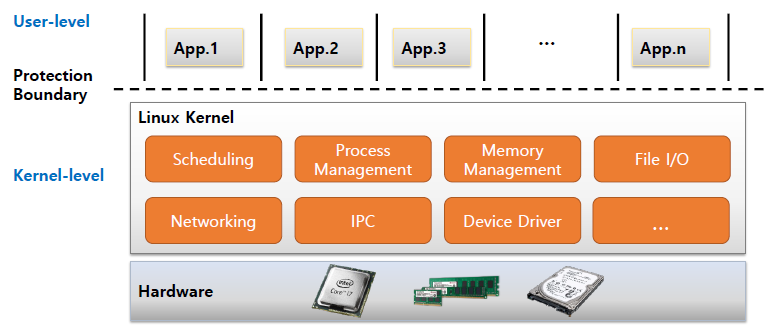
각자의 도메인이 생김 -> 경계가 생김(isolation 환경)
Procection Boundary -> 권한, 보호 등 세팅
서버 가상화 기술
하이퍼바이저의 역할
- 여러 개의 운영체제들에게 하드웨어 가상화를 제공
- 운영체제 내에서 다른 운영체제가 구동될 수 있게 하는 것
- 하나의 Physical Hardware에서 여러 개의 운영체제가 구동될 수 있게 하는 것
- 실행되는 각각의 Process에서 Hardware-like View를 제공하는 것
- 즉, Physical Machine을 Software로 Emulate 해준다 는 의미
- 운영체제에서의 가상화
• CPU -> Process
• Memory -> Virtual Address Space
• Disk -> Files
• Network Interface Card (NIC) -> TCP/UDP Sockets
- 하이퍼바이저(VMM)에서의 가상화• Physical Machine -> Virtual Machine
• CPU -> vCPU
• Disk -> Virtual Disk
• NIC -> vNIC
Virtualized Model (with Hypervisor)
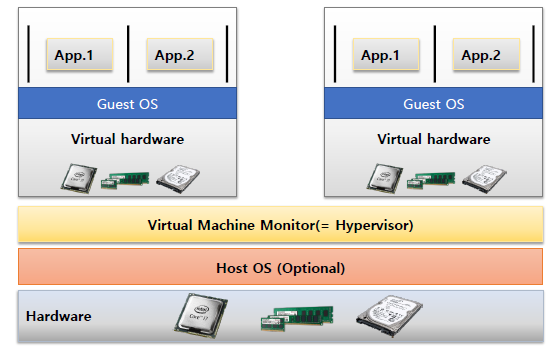
애플리케이션 부분이 사실상 VM으로 바뀌고 이를 관리하기 위해 하이퍼바이저를 두는 형태
Virtual Machine의 등장 배경
- 1960년대, Application의 호환성(Compatibility) 문제 해결을 위해 개발
- 초기 운영체제는 Hardware Vendor Specific, 운영체제 종류도 다양
- Application 또한 특정 운영체제에서만 동작할 수 있음
- 2000년대, 다양한 서버 가상화 솔루션들이 등장 => 물리적인 장비를 공유하기위해 가상머신 구축
- 2001년 VMware의 WorkStation, 2003년 Citrix의 Xen 등
- 2010년대 이후, 클라우드 컴퓨팅의 등장과 함께 재조명 => 원격으로 클라우드 접속후 사용
- Hardware Computing Power의 증가 -> Hardware 자원의 Under-Utilization
- 서버 운용을 위한 관리 비용의 증가 (Power, Cooling Cost 등)
가상화의 장점
1. Server Consolidation (서버 통합)
• 서버 가상화를 통해 독립적인 CPU, 메모리, 네트워크 및 운영체제를 갖는 여러 대의 가상머신들이
물리적인 서버의 자원을 분할해서 사용
• 이러한 Consolidation을 통해 Resource Utilization(자원사용) 을 Dramatic하게 향상
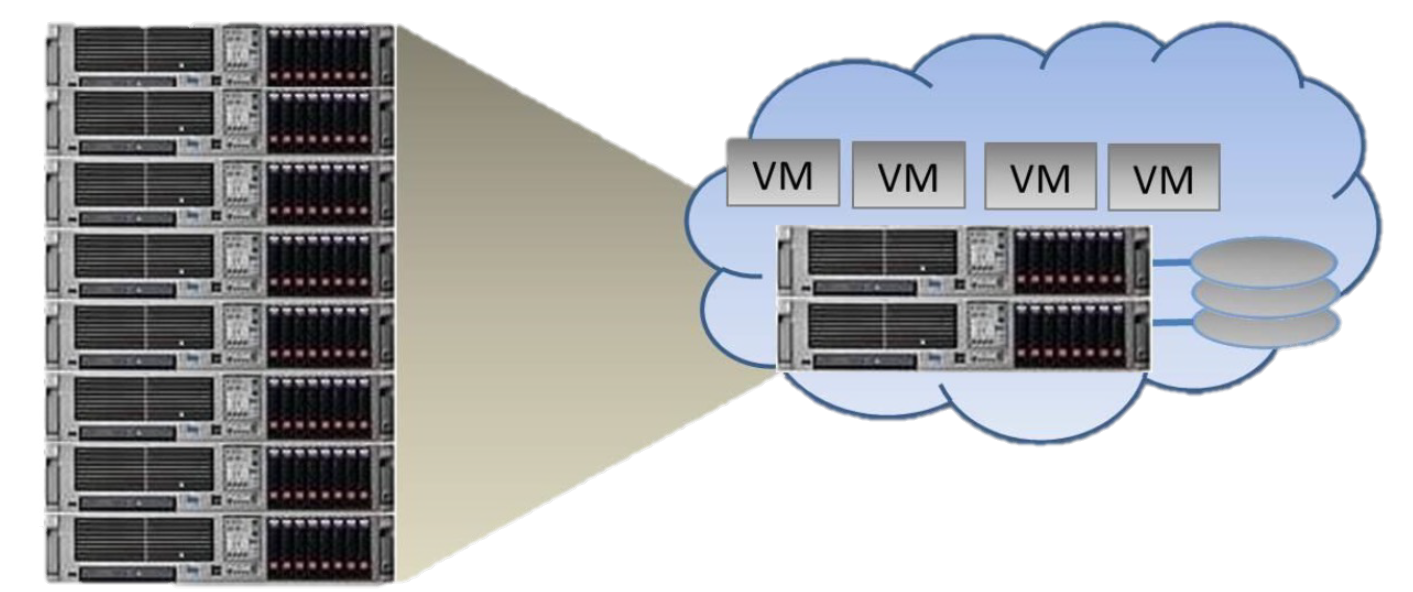
2. Encapsulation (캡슐화) => 하나의 VM = File
• 하나의 파일 형태로 저장되기 때문에 높은 이식성과 백업 등의 장점을 가짐
• Snapshotting / Checkpointing (복사본 / 체크포인트)
• Migration (reload on a different machine)
3. Fault Tolerance and High Availability (장애 허용/ 가용성)
• 대체할 수 있는 동일 VM을 생성하고 유지하여 가상 시스템에 대한 지속적인 가용성을 제공
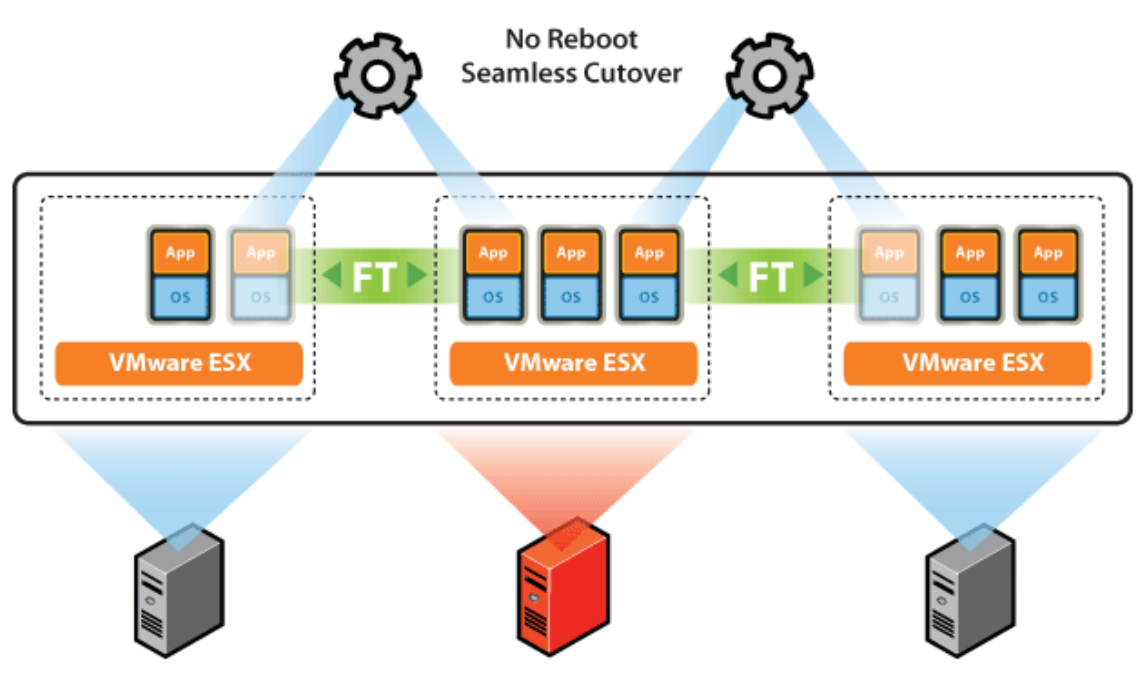
• 보조 가상머신들을 배치하고 Failover 모니터링을 통해 Fault Tolerance가 유지되도록 하는 것이 가능
=> Active & StandBy = Master & Slave
Failover 프로세스의 목적은 시스템의 다운타임을 최소화하고, 사용자나 애플리케이션의 중단 없이 서비스를 계속 제공
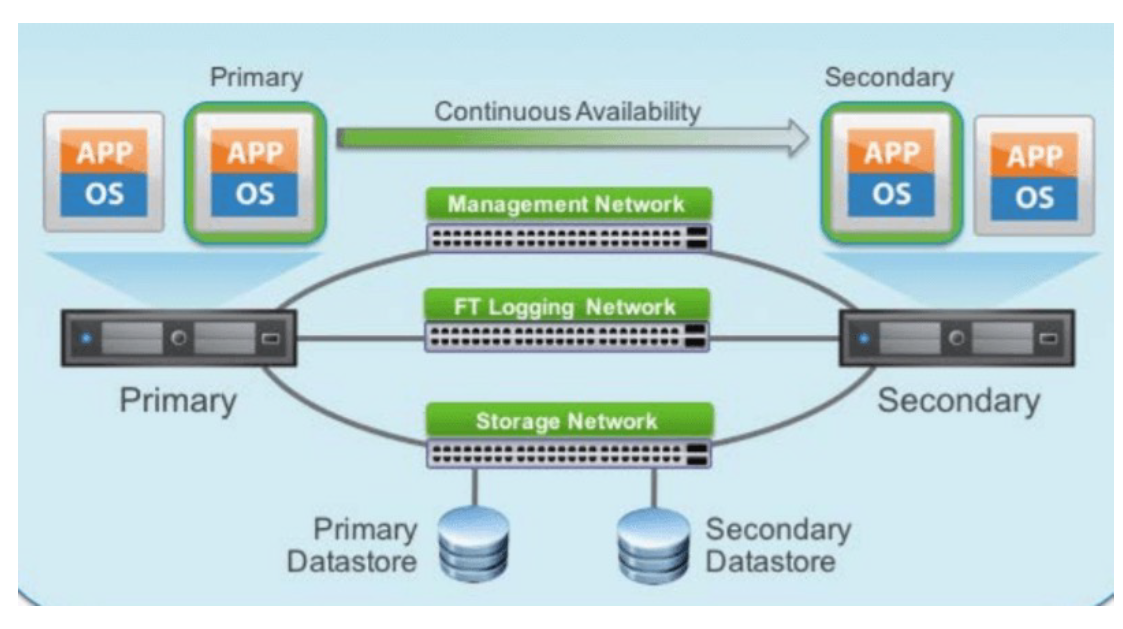
VM 뿐만 아니라 네트워크, 스토리지도 마찬가지다. 특히 5g나 LTE같은 코어망들은 다운되면 안되기 때문에 개별 라우터들이 Active & StandBy 형태로 묶여있다.
4. Complete Isolation
• 기능에 따라 가상머신을 구분하여 운용할 수 있음
• 특정 가상머신의 Guest OS에 문제가 생겨도, 다른 가상머신들이 영향을 받지 않음
애플리케이션이 죽는경우(=게스트 os 안에서 죽는경우) (=특정 프로세스들이 죽는경우)는 다른곳에 영향을 주지 않지만 VM이 죽을 경우(ex 하이퍼바이저 버그, 커널패닉 등등) 는 완벽한 Isolation이 안될 수도 있다. (특히 Type1 에서 발생)
5. Best of All Worlds
• Windows, Linux, MacOS 등의 운영체제를 동시에 구동 시킬 수 있음
• 다양한 Platform 환경에서 Debugging을 수행할 수 있음 (Application Developer 관점)
가상화의 목표
1. Fidelity (Equivalence)
• VMM 위에서 구동된 가상머신에서 실행되는 프로그램들은 Physical Machine에서 실행될 때와
근본적으로 차이가 없는 동작을 보여야 함
2. Efficiency (Performance)
• 대부분의 실행이 VMM의 Intervention(개입) 에 영향을 받지 않음 (큰 성능 차이 없이 실행)
3. Safety (Resource Control)
• VMM이 Virtualized된 모든 자원에 대한 완벽한 통제 및 관리를 수행하고, 각각의 Guest OS는 서로에게 영향을 끼칠 수 없음
서버 가상화 내부 구현
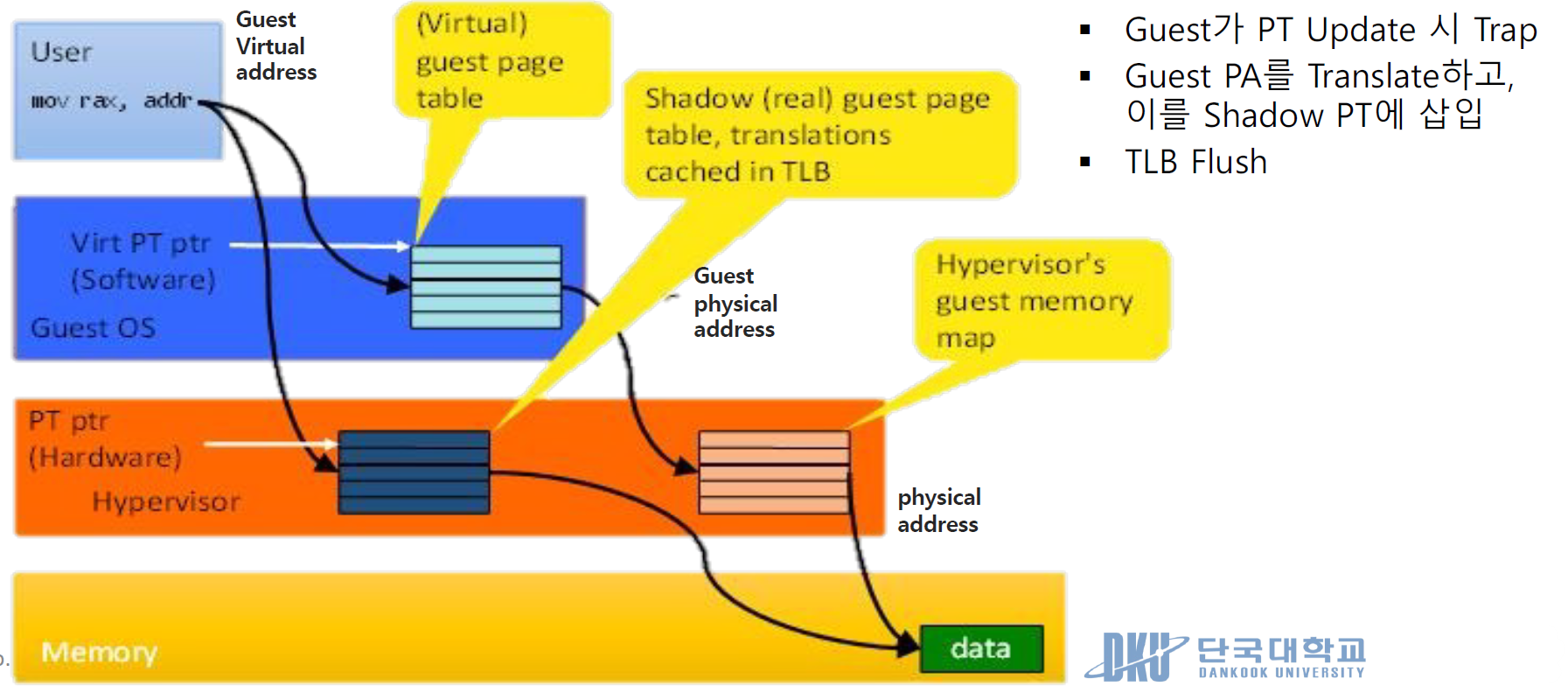
1. Trap and Emulate
• Key design => De-privilege OS, Shadow structure, Memory tracing
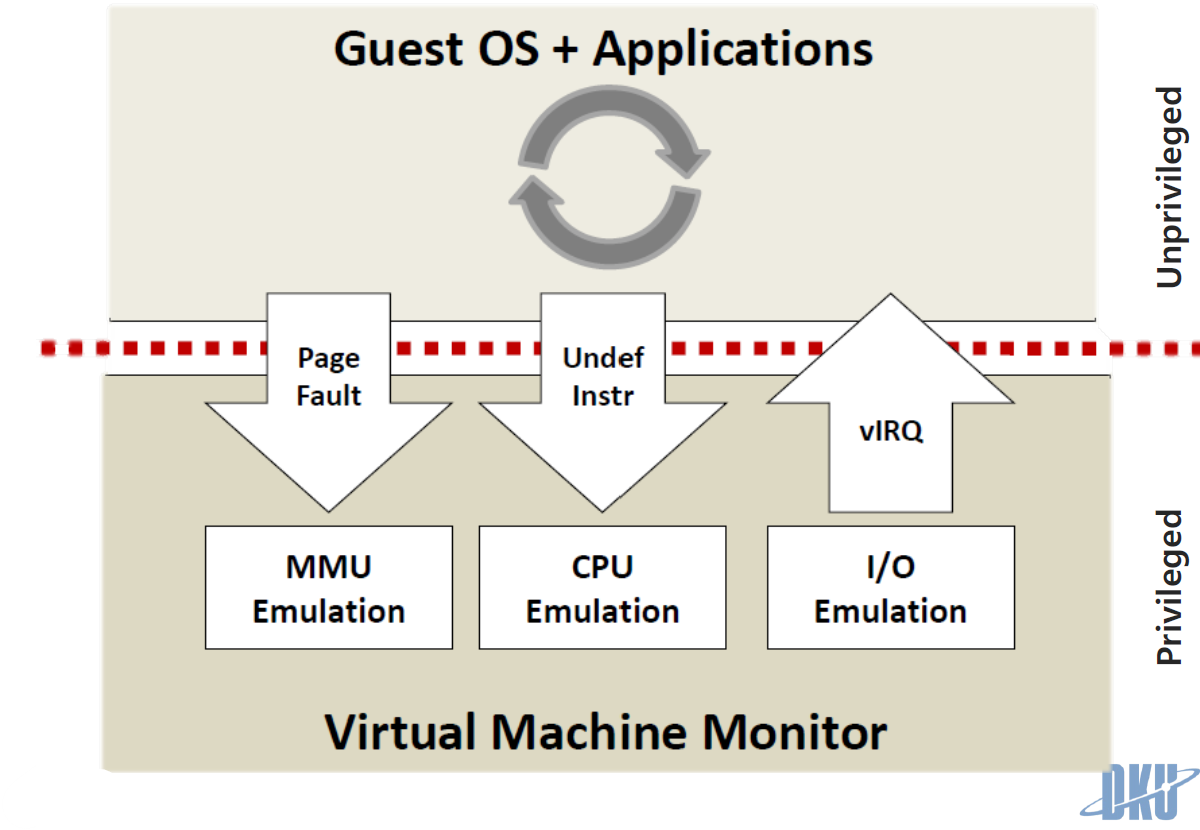
OS 배울때 인터럽트도 배우고 트랩도 사실 배운다. 주로 인터럽트같은 경우는 키보드같이 외부에서 들어오는 이벤트로 발생되는 경우를 얘기하고 트랩은 소프트웨어적인 부분들에서 발생되는 것을 얘기한다.
서버 가상화 내부 구현에서 우리는 호스트 OS 위에서 하이퍼바이저가 돌고 있다고 생각해보자
우리가 돌리고 있는 가상 머신들은 유저 스페이스에서 돌고있다. 근데 그 유저스페이스 안에서 게스트 OS가 돌고 이 게스트 OS는 인터럽트 같은 것을 만들어야 하는데 비슷한 기능이 있어야 동일하게 돌아갈 것이다. 그래서 유저 스페이스에서 이벤트를 발생 시키려면 트랩을 쓸 수밖에 없다. 따라서 가상 머신에서 이 트랩이라는 개념을 이용해서 이벤트를 만들어내는 것
즉, 페이지폴트, 페이지스와핑 같은 뭔가 업데이트를 한다던가 이런 이벤트들이 발생하는것을 게스트OS도 비슷한 역할을 해야하는데 유저 스페이스 안에 있으니까 인터럽트는 쓸수없고 트랩을 쓰는것
유저 스페이스에서 인터럽트를 쓸수없는 이유는 유저스페이스또는 유저 모드에서는 제한된 권한을 가지고 있어서 보안과 안정성의 이유로 인터럽트를 직접 사용할 수 없다. 따라서 유저 모드의 소프트웨어가 OS의 도움이 필요할 때는 트랩을 사용하여 커널모드로 전환을 요청한다.
De-privilege OS
운영 체제(OS)의 권한을 낮추거나 제한하는 개념을 의미한다.
일반적으로, 운영 체제는 컴퓨터 하드웨어와 소프트웨어 리소스를 관리하는데 필요한 높은 수준의 권한을 갖는다. 그러나, 보안을 강화하기 위해, 특히 가상화된 환경에서 운영 체제의 권한을 의도적으로 제한할 수 있다.
특히 가상화 기술에서 중요한 개념인데 전통적인 환경에서 운영 체제는 모든 시스템 리소스에 대한 전체적인 제어 권한을 가지고 있다. 그러나 가상화된 환경에서는, 하이퍼바이저(VMM)가 더 높은 수준의 권한을 가지고 있으며, 각각의 가상 머신 내부에서 실행되는 운영 체제(Guest Os) 는 'de-privileged' 상태, 즉 더 낮은 권한을 가진다.
운영 체제를 De-privilege 하는 주된 이유는 보안과 안정성을 향상시키기 위함
Shadow Structure
가상 머신(VM)의 상태나 구성과 관련된 메타데이터 또는 데이터 구조의 복사본을 의미한다. 가상화 환경에서 자주 언급되는 "Shadow Page Tables"가 대표적인 예
Memory tracing
프로그램이나 시스템에서 메모리 사용을 모니터링, 기록, 분석하는 과정을 말한다.
2. VM Workflow in a Hypervisor
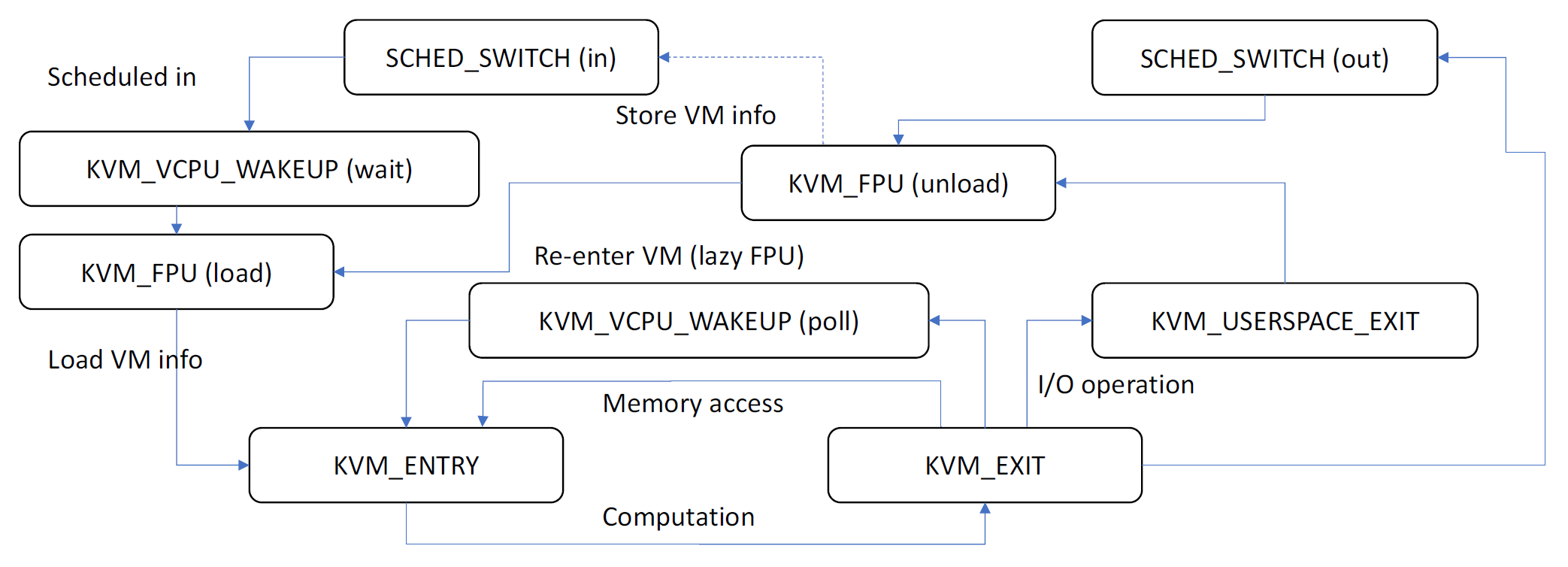
SCHED_SWITCH (in): Host OS의 스케줄러가 다른 프로세스나 스레드에서 가상 CPU(VCPU)로 컨텍스트를 전환
KVM_VCPU_WAKEUP (wait): 가상 CPU가 대기 상태에서 깨어나서 실행을 준비하는 상태, 가상 CPU가 실행을 시작할 준비가 되었음을 나타냄
KVM_FPU (load): 가상 CPU에 대한 부동 소수점 유닛(FPU) 상태가 로드됨, 이는 FPU 관련 작업을 가상 CPU가 처리하기 전에 필요한 설정 단계
KVM_ENTRY: 가상 머신이 실행을 시작하고 하이퍼바이저는 Guest OS 의 컨텍스트로 진입
KVM_EXIT: 가상 머신이 특정 이유(ex I/O 작업, 시스템 호출 등)로 실행을 중단하고 하이퍼바이저로 제어를 반환
KVM_VCPU_WAKEUP (poll) or KVM_USERSPACE_EXIT: 가상 CPU가 이벤트를 폴링하는 상태에 들어가거나, 가상 머신이 사용자 공간에서 작업을 마치고 커널 공간으로 돌아오는 단계
'poll' 상태는 일반적으로 리소스나 이벤트를 기다리는 상태를, 'userspace_exit'는 사용자 수준 작업의 종료를 의미
KVM_FPU (unload) or SCHED_SWITCH (out): 가상 CPU의 부동 소수점 작업이 완료되고 FPU 상태가 언로드되거나, 스케줄러가 VCPU의 작업을 마치고 다른 프로세스나 스레드로 전환하는 단계
'unload'는 FPU 사용이 끝났음을, 'sched_switch (out)'은 다른 작업으로의 컨텍스트 전환을 의미
이 순서는 KVM 하이퍼바이저를 사용하는 가상 환경에서 가상 CPU의 작업 순서와 상태 변화이고, 실제 환경에서의 구체적인 상황에 따라 변동이 있을 수 있다.
3. Memory Virtualization
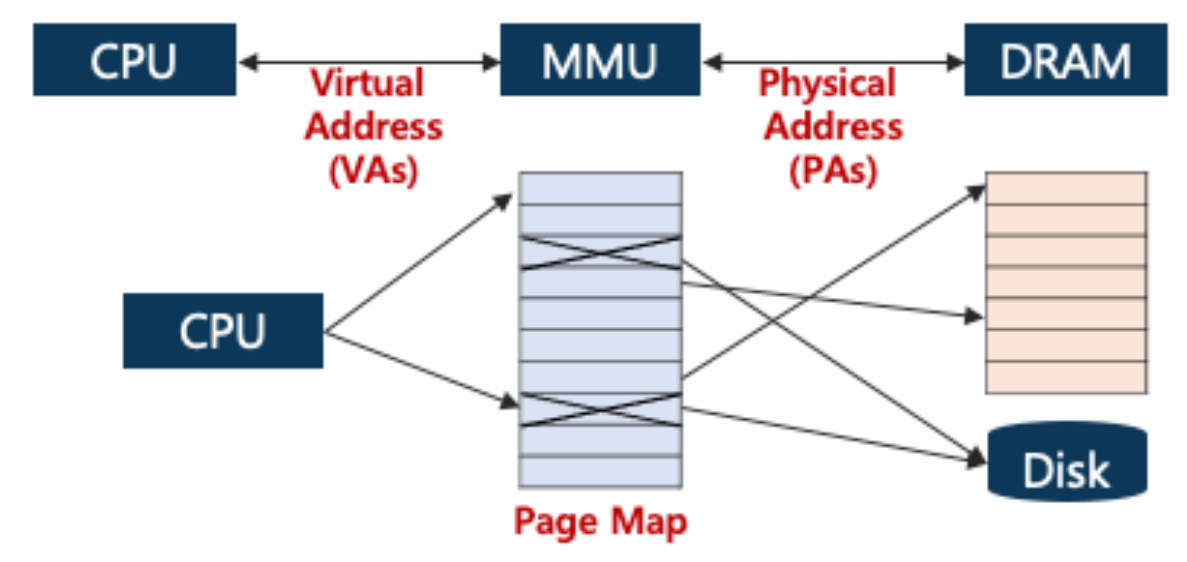
• 여기서, Virtualization이 추가되면 Two-level Translation이 필요
Guest VA (Virtual Address) => Guest PA (Physical Address) = Host VA => Host PA (Machine Address)
Guest OS 에서 발생되는 것들이 실제 피지컬 메모리까지 가기 위해서 기본적으로 두번의 Translation이 발생한다.
Shadow Page Table
• Guest PA와 Host PA 사이의 Mapping을 관리하는 Shadow Page Table 도입
• MMU를 Virtualize하는 기법이라고 생각하면 됨
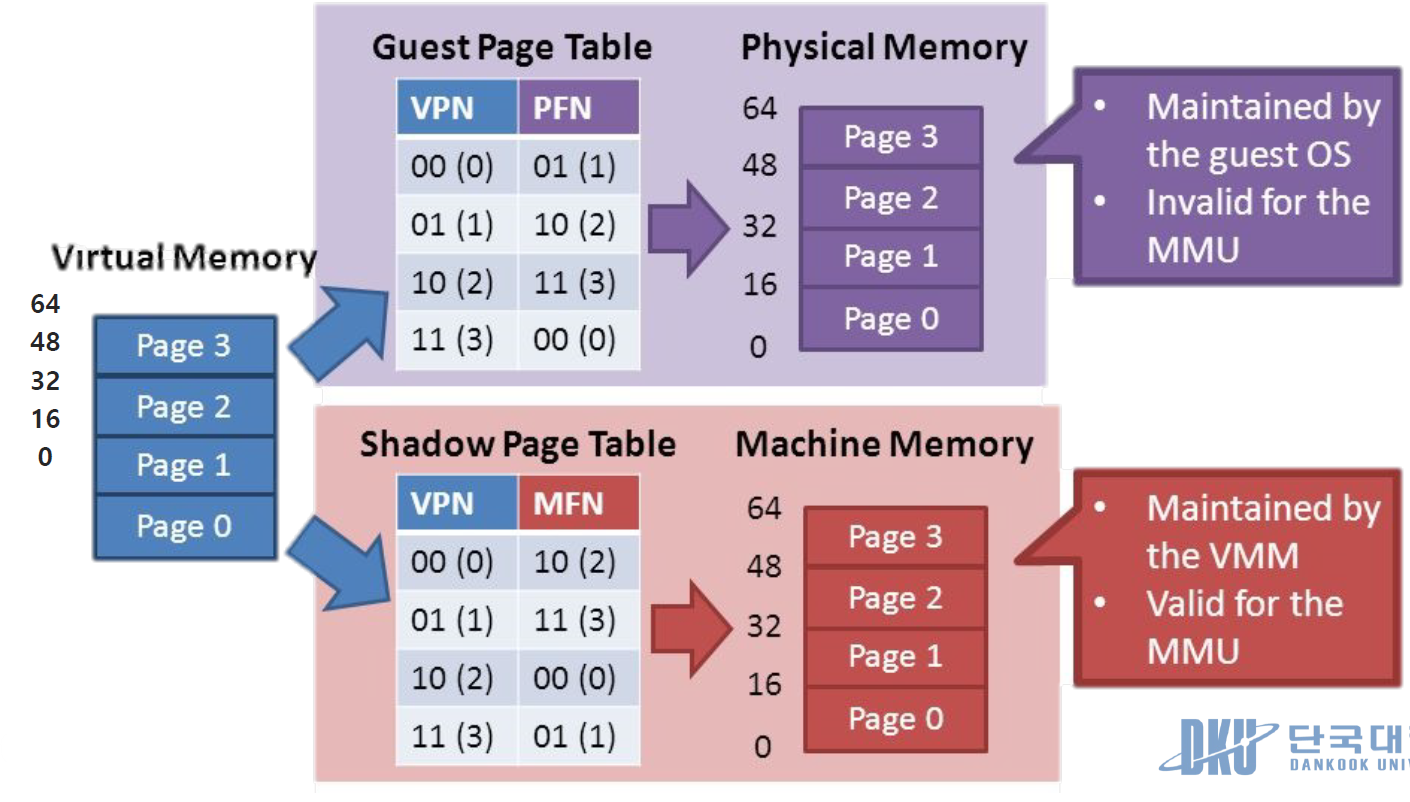
하이퍼바이저는 물리적 호스트 시스템 위에서 하나 이상의 가상 머신(VM)을 관리한다. 각각의 가상 머신은 자체 운영 체제와 가상 메모리를 가지고 있다. 가상 메모리 시스템에서, 페이지 테이블은 가상 주소(VA)를 물리적 주소(PA)로 매핑하는 데 사용된다. 그러나 가상화 환경에서는 이러한 매핑이 더 복잡해진다.
가상 머신의 가상 주소(VA)는 먼저 '게스트 물리 주소'(Guest PA)로 변환되고, 이어서 실제 호스트의 물리적 주소(Host PA) 로 다시 매핑된다.
Shadow Page Tables는 이 복잡한 주소 변환 과정을 관리하기 위해 하이퍼바이저에 의해 사용되는데 게스트 운영 체제 내부에서 사용되는 원본 페이지 테이블의 복사본을 의미한다. 하이퍼바이저는 이 Shadow Page Tables 을 사용하여 가상 머신의 가상 주소(Guest VA) 에서 호스트 시스템의 실제 물리적 주소(Host PA)로의 매핑을 관리한다. 이 과정은 가상화된 환경에서 메모리 접근과 자원 할당의 효율성과 안전성을 높이는 데 중요하다.
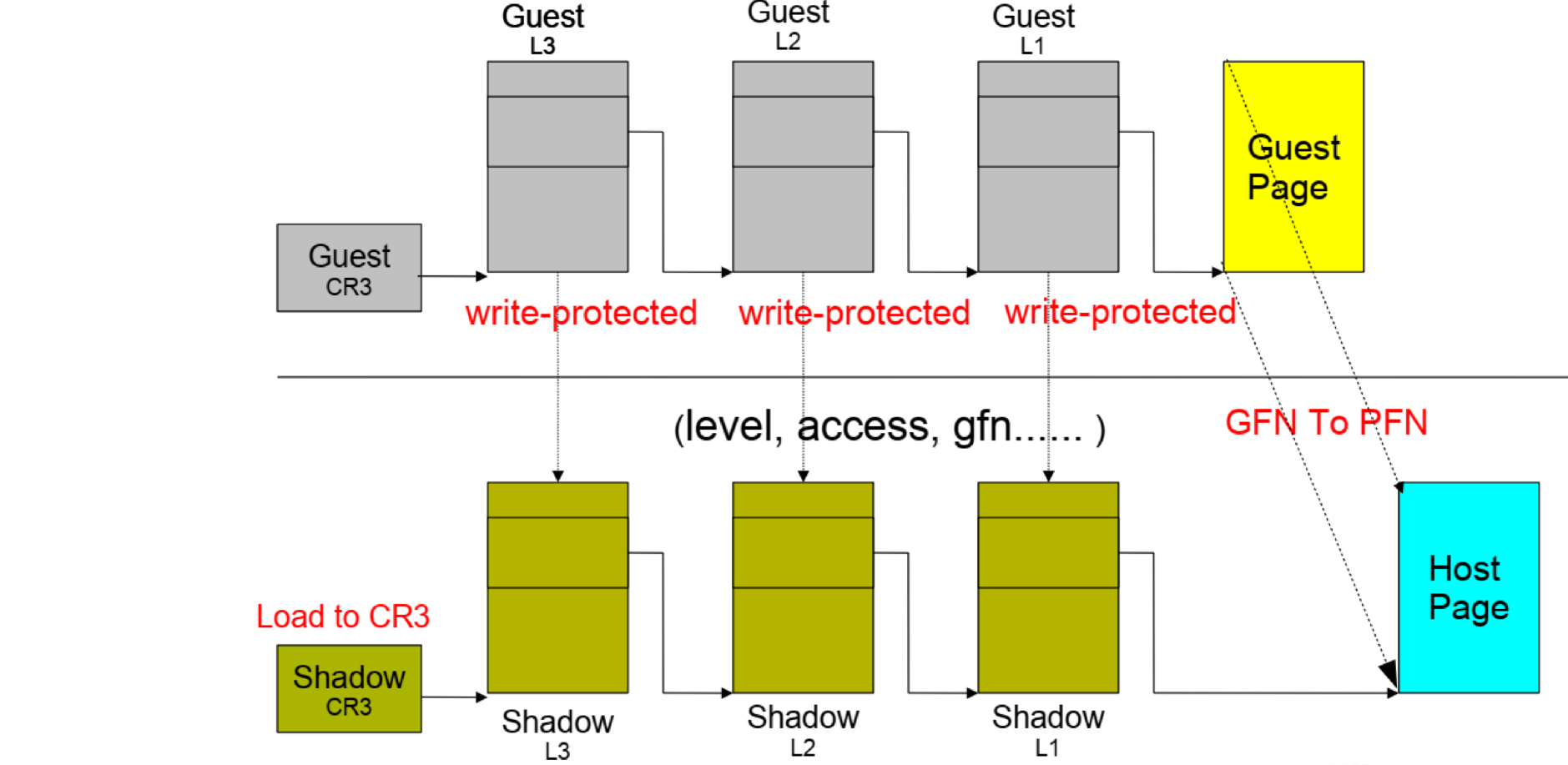
- Hypervisor는 Shadow Page Table을 일관성 있게 유지할 수 있어야 함
• Guest OS는 자신의 Page Table을 손쉽게 Modify할 수 있음 (Simple Memory Write)
• 단순 Memory Write를 VMM이 Trace 할 수 없음 (Privilege Instruction이 아니므로)
- Guest Table에 Mapping된 Hardware Page들을 Read-Only로 마킹
• Guest가 Table을 업데이트하려고 하면 예외가 발생하게 됨
• VMM은 이를 Catch하여 Shadow Table Update를 수행
내부적으로 Guest OS가 쓰는 영역들을 read-only로 마킹해서 누군가 write하려고 하면 트랩이 발생하고 에러가 난다. 그 트랩을 캐치해서 하이퍼바이저가 실질적으로 업데이트를 수행하는 것
만약 게스트 OS가 write 권한까지 가지면 하이퍼바이저 입장에서 모든걸 tracing할 수 없다. (하이퍼바이저가 Guest OS보다 더 많은 리소스를 쓰고 있다는 소리가 되니) 그렇게 할 수 없으니까 read-only를 통해 write하는 경우 트랩을 발생시키고 트랩을 핸들링 해주는 것을 하이퍼바이저가 캐치해서 실제 Shadow Page tables에 업데이트를 수행하게 되고 실제로 피지컬 메모리에도 업데이트가 이뤄지는 구조가 된다!
- Shadow Structure와 Memory Tracing
• Guest OS에서의 Page Table Entry 업데이트는 Trap을 야기
• Privilege Instruction - Hypervisor가 Trap을 인지하여 Shadow Page Table을 업데이트, 이는 Page 단위로 Memory Tracing을 발생 시킴
1. Guest OS가 Virtual Page를 Allocate하고 Guest Page Table에 Mapping
2. Hypervisor가 Machine Page를 Allocate한 뒤, Guest Physical to Machine Page Mapping을 설정
3. Hypervisor가 Shadow Page Table Mapping을 업데이트 (Guest Virtual to Machine)
- 모든 Guest Page Table 업데이트가 Trap을 발생시킴
• 빈번하고, 큰 Overhead 발생!
'CS > 클라우드 컴퓨팅' 카테고리의 다른 글
| [클라우드] 6. Kubernetes (쿠버네티스) (0) | 2024.04.17 |
|---|---|
| [클라우드] 5. 네크워크 가상화(Network Virtualization) (0) | 2024.04.04 |
| [클라우드] 4. Container (Docker) (0) | 2024.03.21 |
| [클라우드] 2. Cloud Services and Technologies (2) | 2024.03.21 |
| [클라우드] 1. Introduction to Cloud Computing (0) | 2024.03.21 |




댓글