Packet Flow in Kernel

- L2 (Layer 2): 패킷이 네트워크 인터페이스를 통해 처음 받아들여지는 레이어, 주로 물리적 주소인 MAC 주소를 사용
- Ingress: 패킷이 커널 내부로 들어오는 지점
- L3 (Layer 3): 네트워크 레이어, 주로 IP 주소를 사용하여 패킷의 라우팅을 결정, 여기서 패킷은 다음 목적지를 향해 이동하도록 설정
- Proto Handler: 패킷이 어떤 프로토콜을 사용하고 있는지 확인하고, 그에 맞는 프로토콜 핸들러로 패킷을 전달
- Routing: 패킷이 최종 목적지로 라우팅되는 방식을 결정, 패킷이 내부 라우팅 테이블에 따라 적절한 인터페이스로 전송되거나 다른 라우터로 전달
- Forwarding: 패킷이 최종 목적지를 향해 전달되는 단계, 라우팅 테이블의 정보를 사용하여 패킷을 전송
- NEIGH (Neighbor): 패킷이 전송될 때 인접한 네트워크 노드(예: 다른 호스트, 라우터 등)의 정보를 확인하고 사용
- Egress: 패킷이 네트워크 인터페이스를 통해 외부로 전송되는 단계
- Input: 패킷이 어플리케이션 레이어의 프로토콜로 처리되며, 필요한 경우 추가적인 정보나 데이터 처리
- Upper Layer에서 Routing: 다시 커널의 네트워크 스택으로 내려와서 라우팅, 패킷이 외부로 전송되기 전에 적절한 목적지로 라우팅되어야 할 필요가 있을 때 발생
- Output: 외부로 전송 준비, 패킷이 최종적으로 네트워크 인터페이스를 통해 송출되기 전에 마지막 확인이나 조정
- Upper Layer: OSI 모델의 상위 레이어, INPUT 및 OUTPUT 과정에서 데이터의 최종 처리
Ingress 와 Egress 사이를 Traffic Control 이라하는데 리눅스 명령어에 TC가 이것이다. 트래픽 컨트롤은 제어를 하기 위한 명령어만 존재한다. 즉, 트래픽 컨트롤의 Ingress로 들어오는거고 Egress로 나가는것
Packet Receiving Path In Kernel
패킷 수신 경로: 네트워크 패킷은 커널 내부에서 효율적으로 관리되고, 적절한 목적지로 라우팅되어 처리
Device Driver (L2) → Ingress → Proto Handler → Routing → Input → Upper Layer (L4)
Packet Sending Path In Kernel
패킷 전송 경로: 데이터는 네트워크를 통해 목적지로 효율적이고 신뢰성 있게 전송
Upper Layer (L4) → Routing → Output → Neigh → Egress → Device Driver (L2)
Packet Forwading Path In Kernel
패킷 전달 경로: vNIC나 vSwitch를 만들다보면 어플리케이션으로 안가고 패키지에 들어왔다가 다시 나가는 패킷도 생김
Device Driver (L2) → Ingress → Proto Handler → Routing → Forwarding → Neigh → Egrss → Device Driver (L2)
Open vSwitch
- 리눅스 기반의 가상 소프트웨어 스위치
- 네트워크를 추상화하여 동적으로 자원을 제어할 수 있음
- 터널링 프로토콜 지원 (GRE, VXLAN, Ipsec 등)
- 모니터링 기능 지원 (NetFlow, sFlow, IPFIX, SPAN, RSPAN 등)
- 분산 가상 스위치 기능 제공
• 다른 물리 서버에 위치한 가상 서버(VM)를 서로 연결
리눅스 브릿지는 내부를 위한 것인데 내부 버추얼 인터페이스를 가지고서 컨테이너나 VM들을 동작시키는데는 무리가 없지만 다른 거랑 연결하고 싶을때 문제가 생긴다. 근데 오픈 v스위치(ovs) 같은 경우는 내부적으로 GRE나 VXLAN 같은 터널링을 만들 수 있게 소프트웨어가 제공해준다. 그래서 편하게 ovs를 통해서 네트워크 연결이 가능하다.
일반적인 쿠버네티스 같은 환경에서는 ovs를 잘 쓰진 않음 보통 CNI가 컨테이너 네트워크 인터페이스 안에서 소프트웨어적으로 터널링을 제공하기 있기 때문
전통적인 네트워크 → SDN 배경
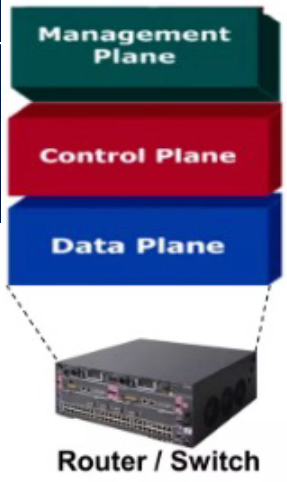
전통적인 네트워크 장비는 3개 계층으로 구성
• Management Plane – 설정, 정책, 등등
• Control Plane – 라우팅 결정
• Data Plane – 실제 패킷 포워딩
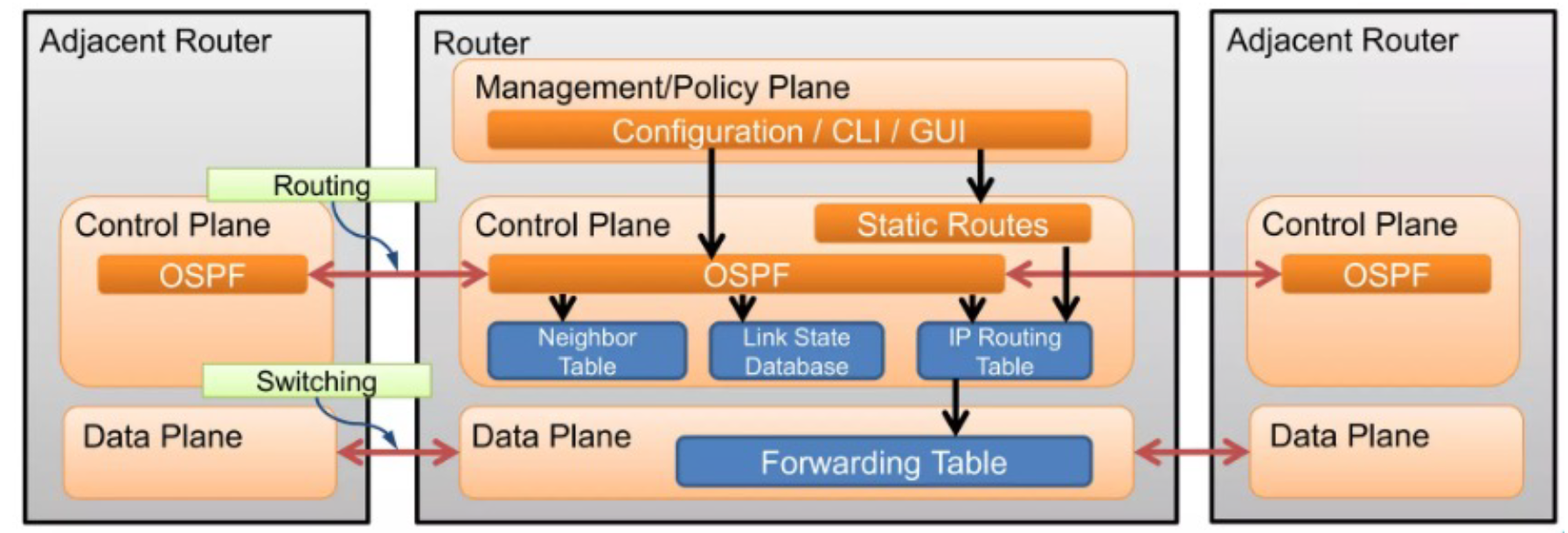
클라우드와 SDN은 뗄수 없는 관계가 되었는데 예전에는 VM들이 몇개 되지 않았었다. 그래서 리눅스 브릿지 가지고 VXLAN을 통해 터널 만들고 쓸 수 있었는데 데이터센터가 생기고 대형 메탈 머신들 자체의 개수가 엄청 늘어나고 대형 메탈 안의 VM 개수들이 엄청 많아졌다. 그래서 이 많은 VM들을 통합적으로 관리할 수 있을까? 라는 개념이 나오게 되었다.
즉, 기존에는 실제 스위치나 라우터들도 매뉴얼로 접속하여 모든것들을 사용자가 세팅을 해야했다. 하지만 관리 해야하는 수가 너무 늘어나서 소프트웨어적으로 관리한다는 개념이 SDN (Software Defined Networking)
소프트웨어 정의 네트워킹 (SDN)
- 서버 가상화와 클라우드의 급속한 발달
• 시스템의 통합 관리 및 운영 자동화 발전 - 네트워크는? 현실은?
• 기존과 같은 방식으로 하드웨어별로 운영/관리
• 네트워크의 유연한 증설과 변경, 운영의 자동화가 큰 과제! - 해결책: Software Defined Networking (SDN)
• 네트워크를 가상화하고 네트워크 구성과 기능 설정 등을 소프트웨어로 프로그래밍할 수 있도록 해 줌!
Key Points
- Orchestration: 수천대의 장비를 어떻게 제어하고 관리?
- Programmability: 즉석에서 행동을 바꾸는 방법?
- Dynamic Scaling: 사이즈, 수량, 용량 어떻게 변경?
- Automation: 어떻게 자동화?
- Visibility: 리소스와 연결성을 어떻게 모니터링?
- Performance: 네트워크 장치 활용도를 어떻게 최적화?
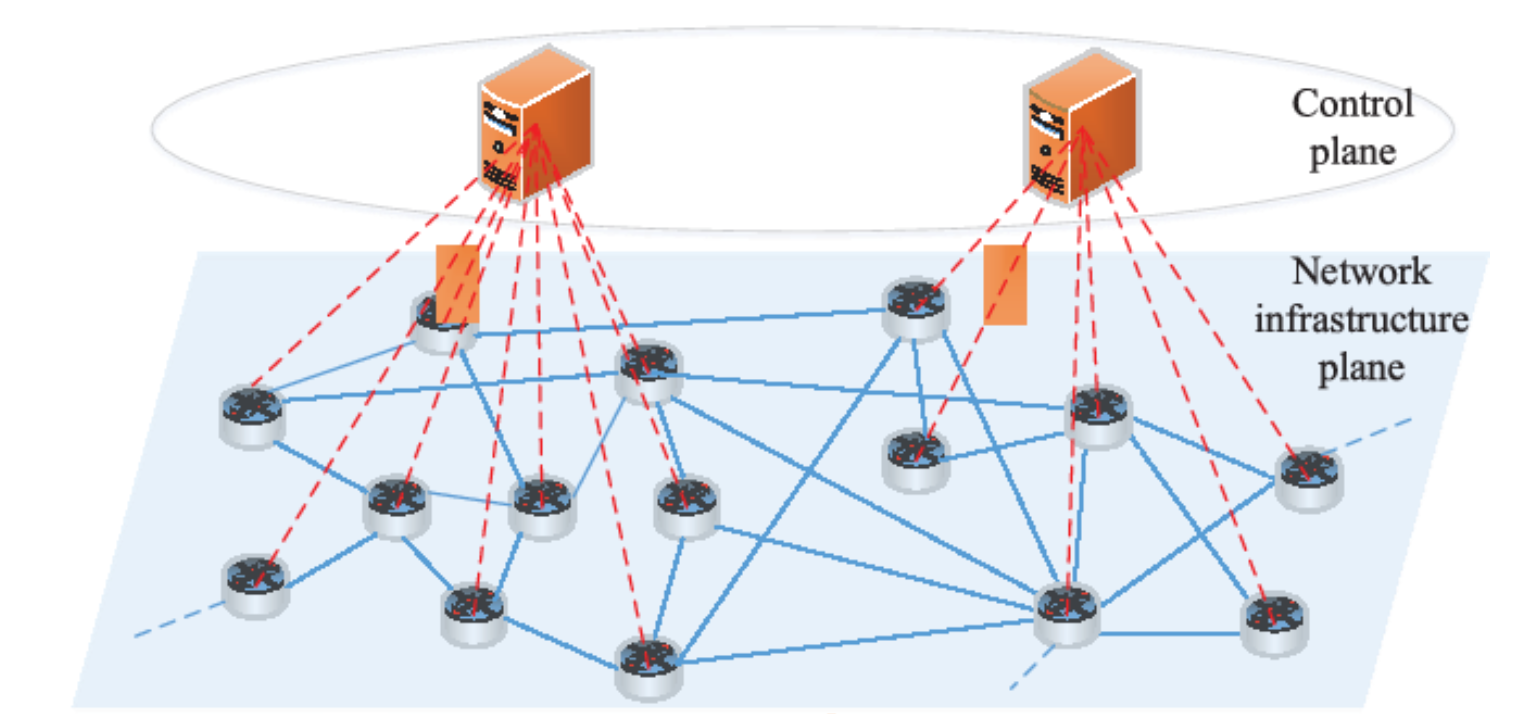
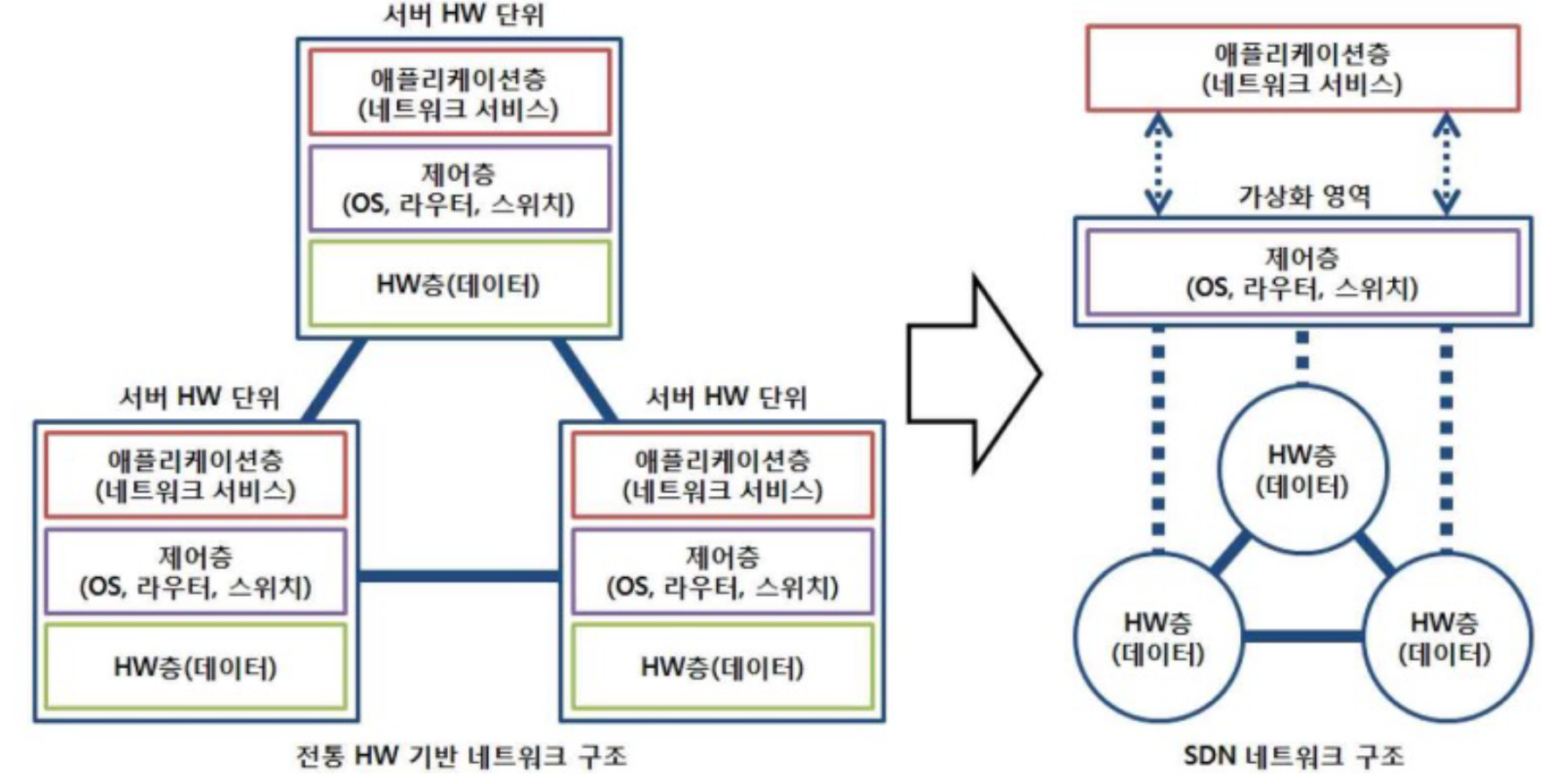
• 제어 평면과 데이터 평면의 분리
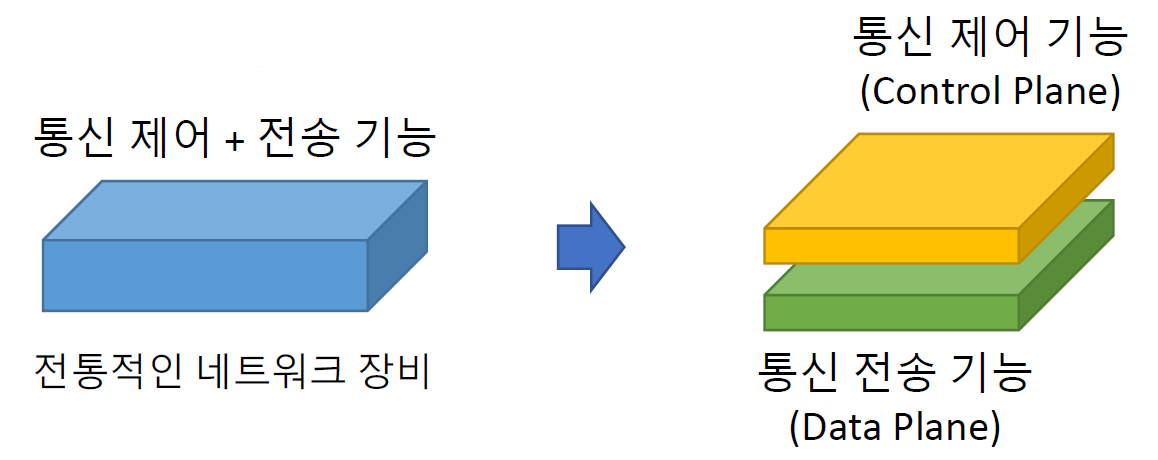
• 중앙집중형 제어
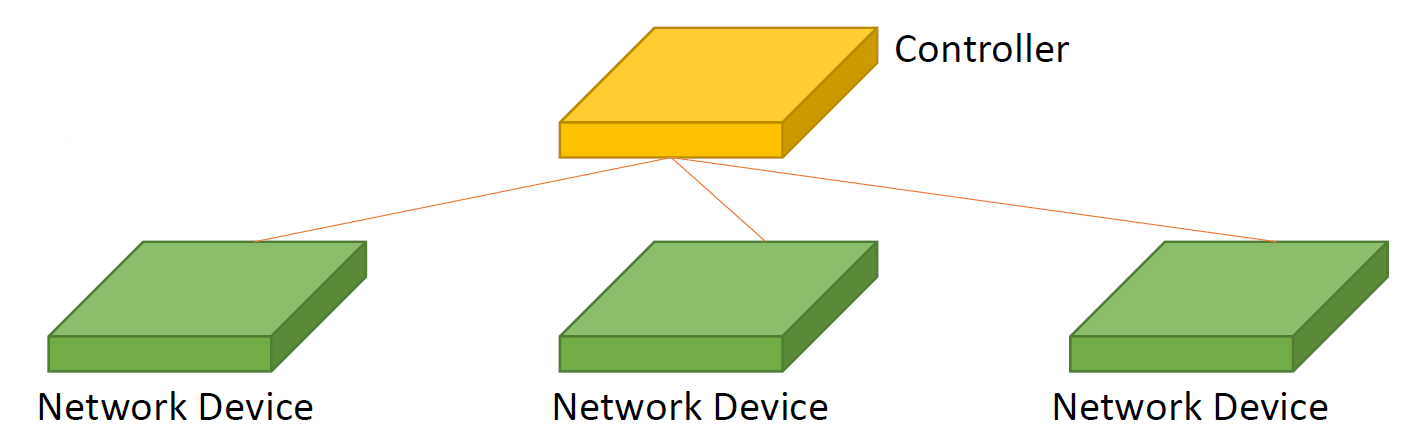
• 물리적 네트워크의 가상화
• 하나의 물리적 네트워크 위에 컨트롤러 별로 여러 개의 가상 네트워크
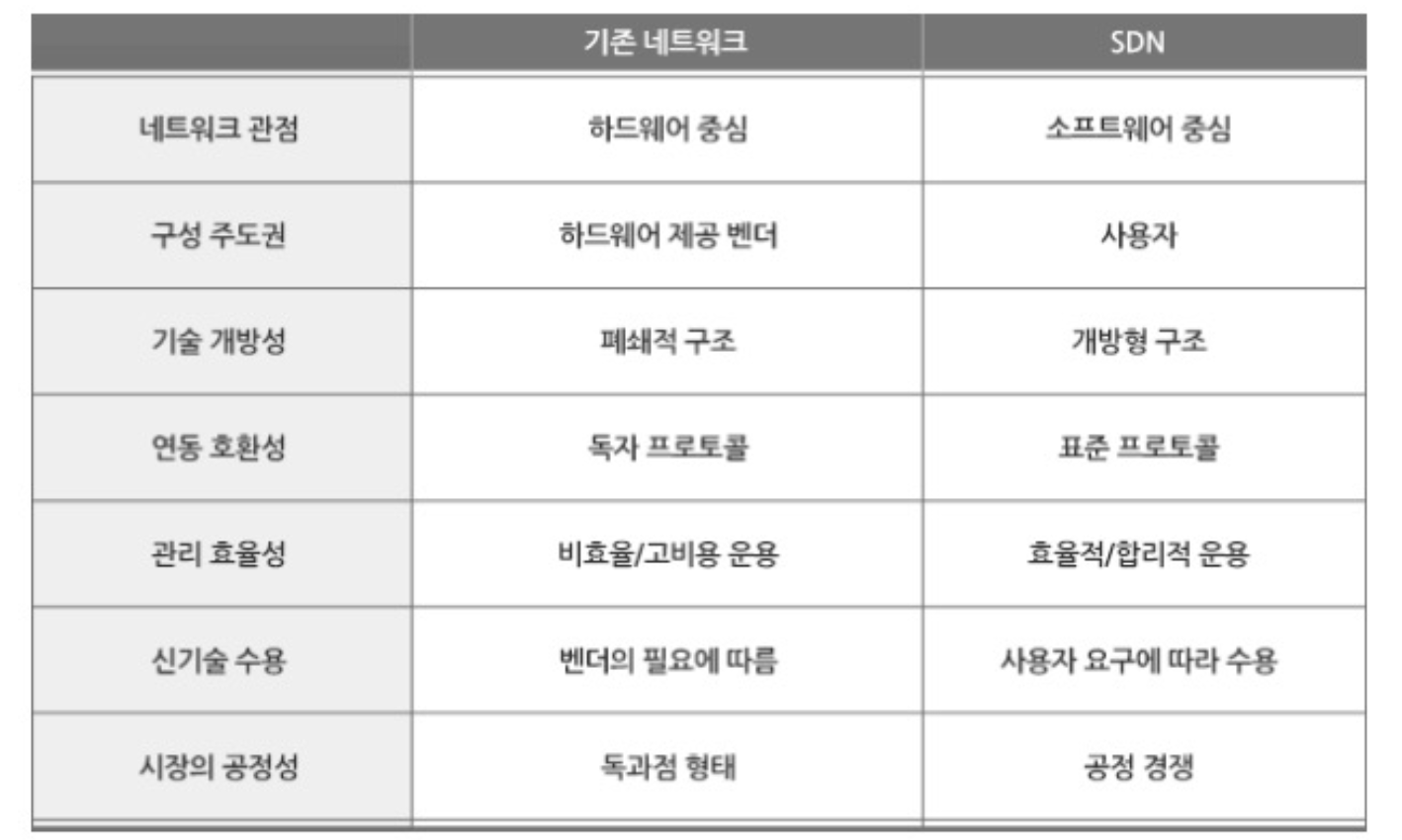
기존 네트워크 vs SDN
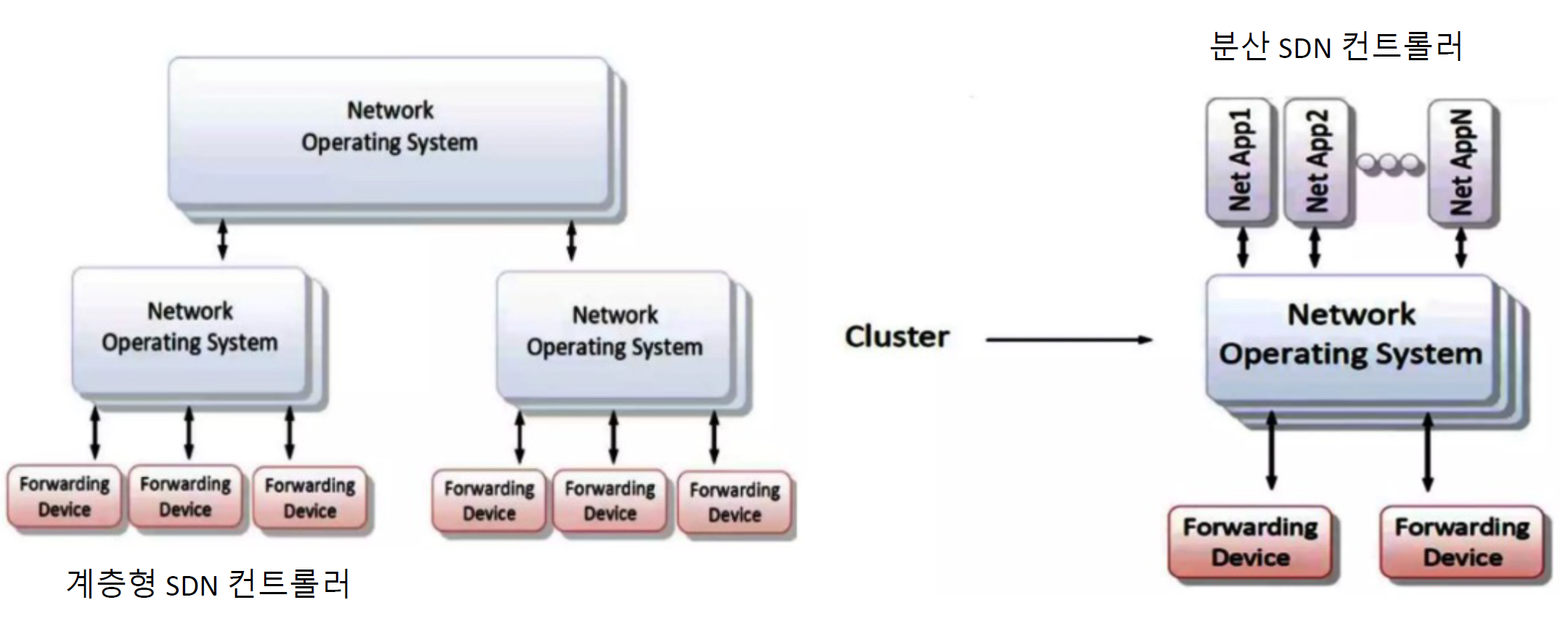
SDN 아키텍처
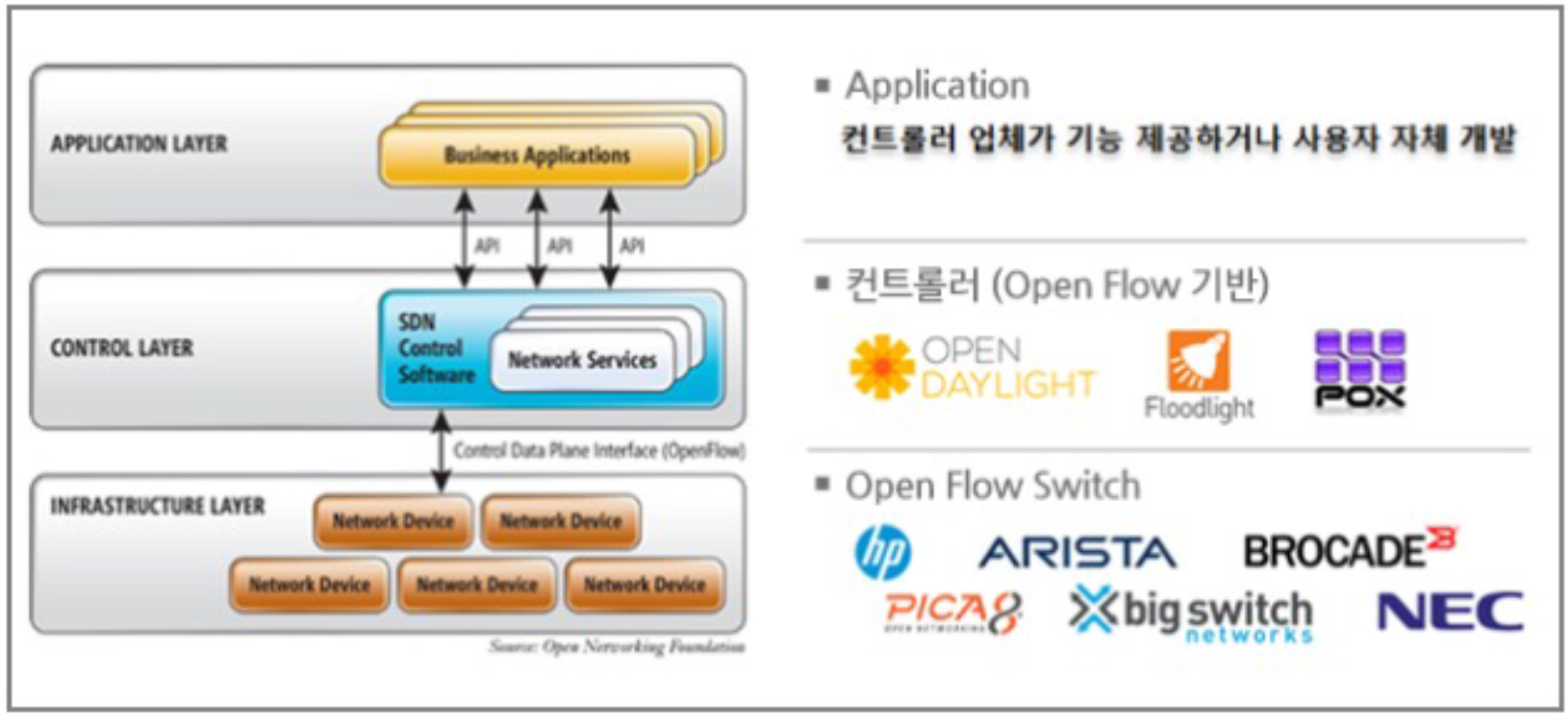
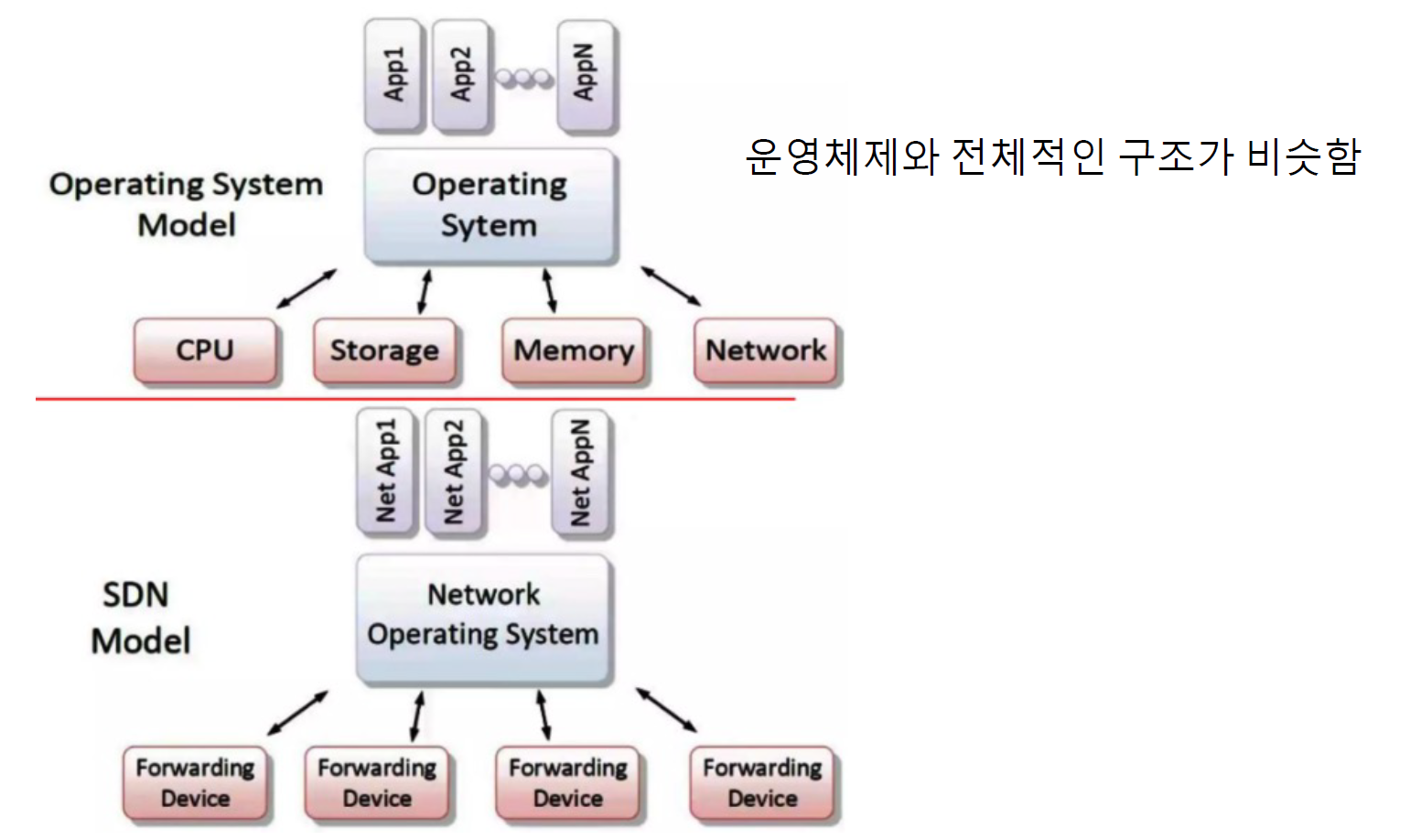
- 네트워크 애플리케이션
- 애플리케이션 인터페이스
• Northbound (e.g., REST) - SDN 컨트롤러 (제어평면)
• 구조, 링크, 호스트, 통계 관리 - Southbound 인터페이스
• OpenFlow, OVSDB, NETCONF - 포워딩 장치(데이터 평면)
SDN 동작 시나리오
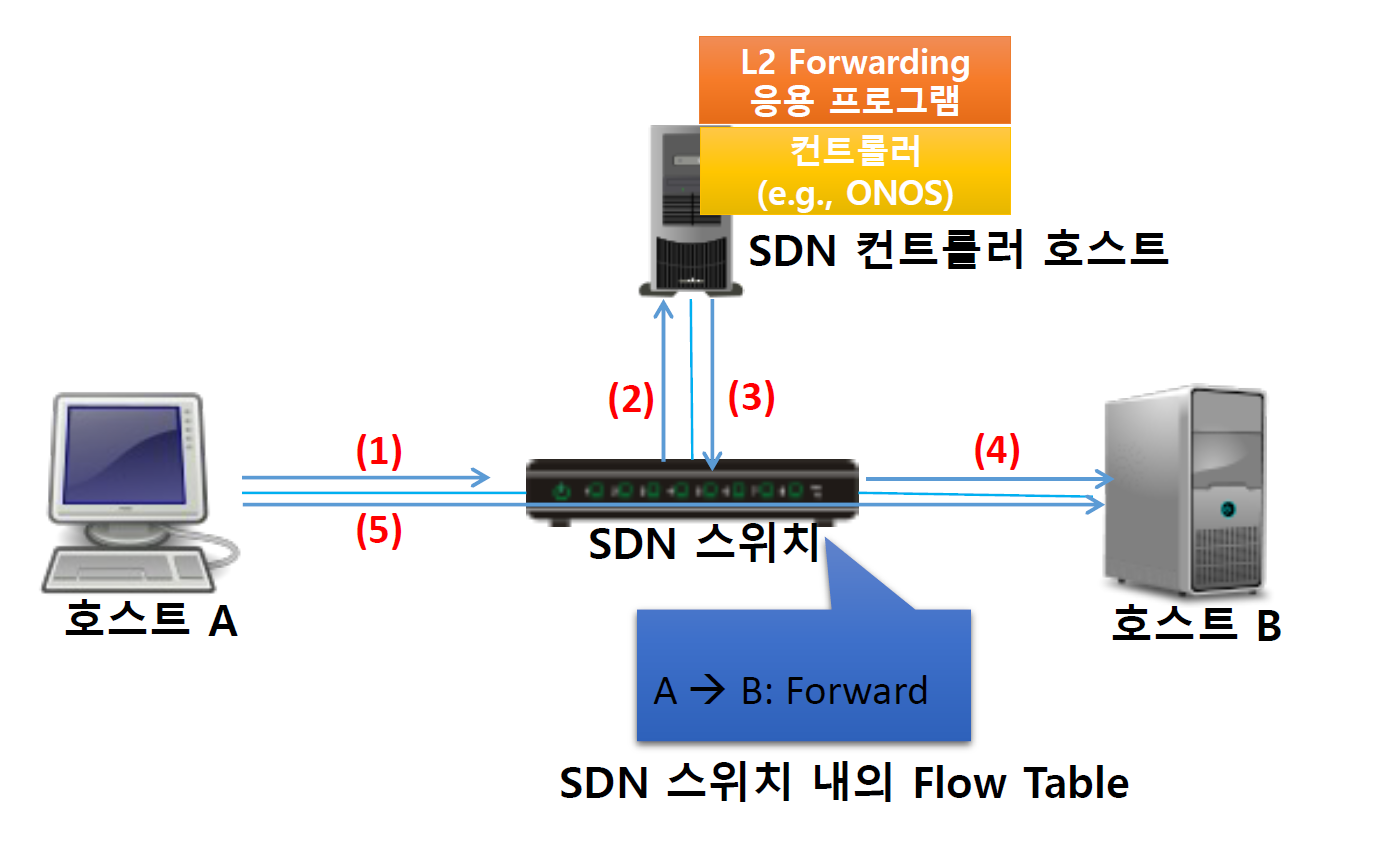
SDN은 네트워크의 제어면(control plane)과 데이터면(data plane)을 분리하여, 네트워크 관리를 유연하게 하고, 중앙에서 네트워크 전체를 조정할 수 있게 하는 기술이다.
- 패킷 송신(1): 호스트 A에서 호스트 B로 데이터 패킷을 보낸다. (네트워크의 시작 지점)
- SDN 스위치로 패킷 전달(2): 호스트 A에서 보낸 패킷이 SDN 스위치에 도착한다. SDN 스위치는 네트워크의 데이터 플로우를 실제로 처리하는 장치
- 컨트롤러 통신(3): SDN 스위치는 네트워크의 컨트롤러와 통신을 한다. 컨트롤러는 중앙에서 네트워크의 전반적인 흐름을 관리하며, 스위치에게 어떻게 패킷을 처리할지 지시한다. 여기서 컨트롤러는 ONOS, OpenDaylight 등의 SDN 컨트롤러 소프트웨어를 사용할 수 있다.
- 패킷 전송(4): 컨트롤러의 지시에 따라, SDN 스위치는 호스트 B로 패킷을 전달한다. (네트워크의 목적지)
- 데이터 플로우 테이블(5): SDN 스위치 내의 데이터 플로우 테이블에는 컨트롤러로부터 받은 패킷 처리 지시가 포함되어 있다. 이 테이블은 스위치가 각 패킷을 어떻게 처리할지 결정하는 데 사용된다.
네트워크 기능 가상화 (NFV)
- Network Function Virtualization (NFV)
• 네트워크 장비에서 하드웨어와 소프트웨어를 분리
• 표준 가상화 기술을 통해 네트워크 서비스를 제공
• 장비의 의존성을 없애고, 네트워크 운용 비용 절감, 서비스 민첩성 제공 - 등장 배경
• 트래픽 사용량의 증가로 네트워크 인프라 확장이 필요
• 기존 환경에서 새로운 서비스 확장은 높은 투자 비용 발생, 관리 어려움 - 목표
• 운영 효율성 향상, 범용 하드웨어로 네트워크 서비스 제공
• 네트워크 서비스를 소프트웨어로 제공해 유연성 향상
• 표준화 및 오픈 인터페이스를 제공해 벤더 의존성 감소
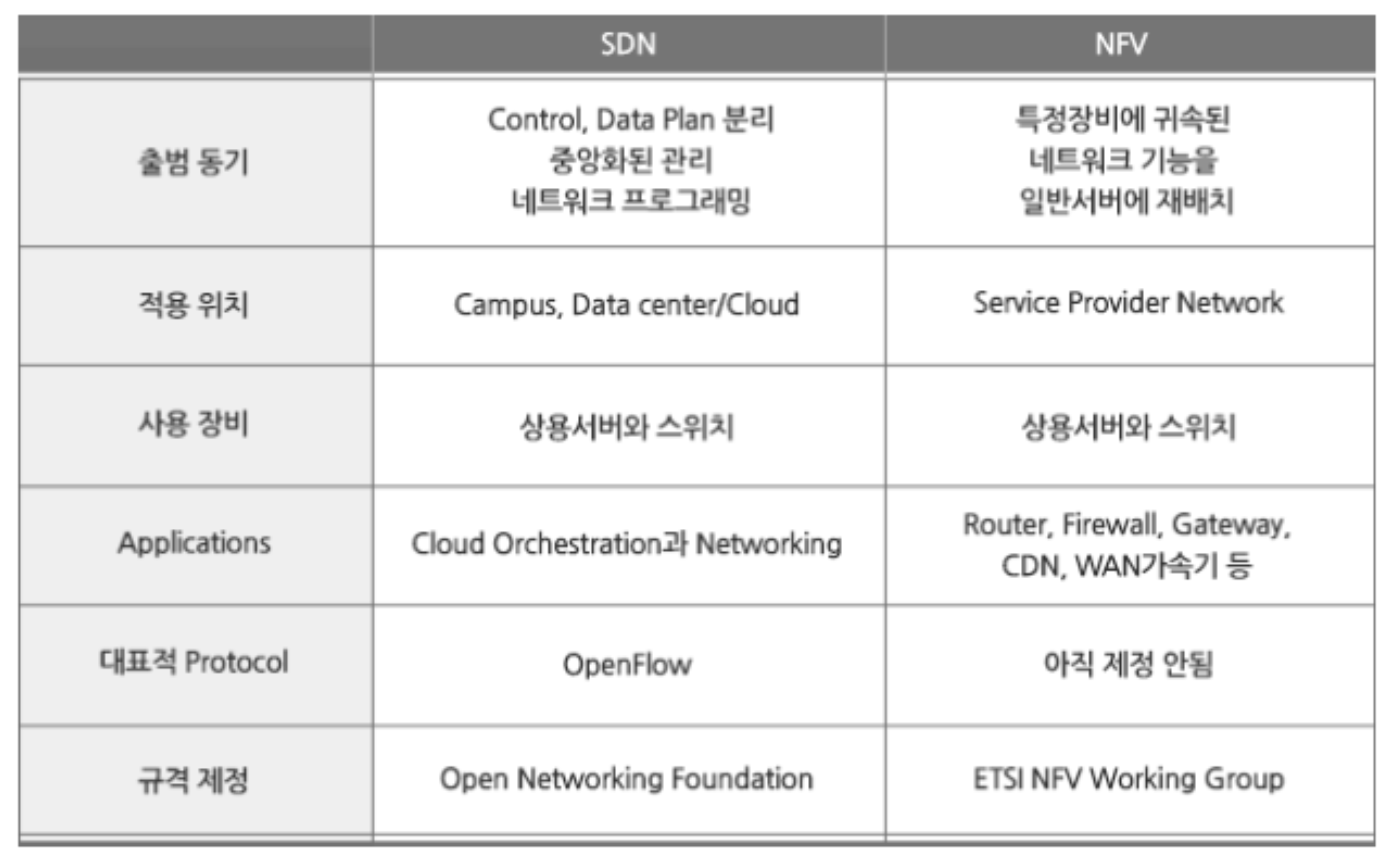
SDN vs NFV
NFV 개념
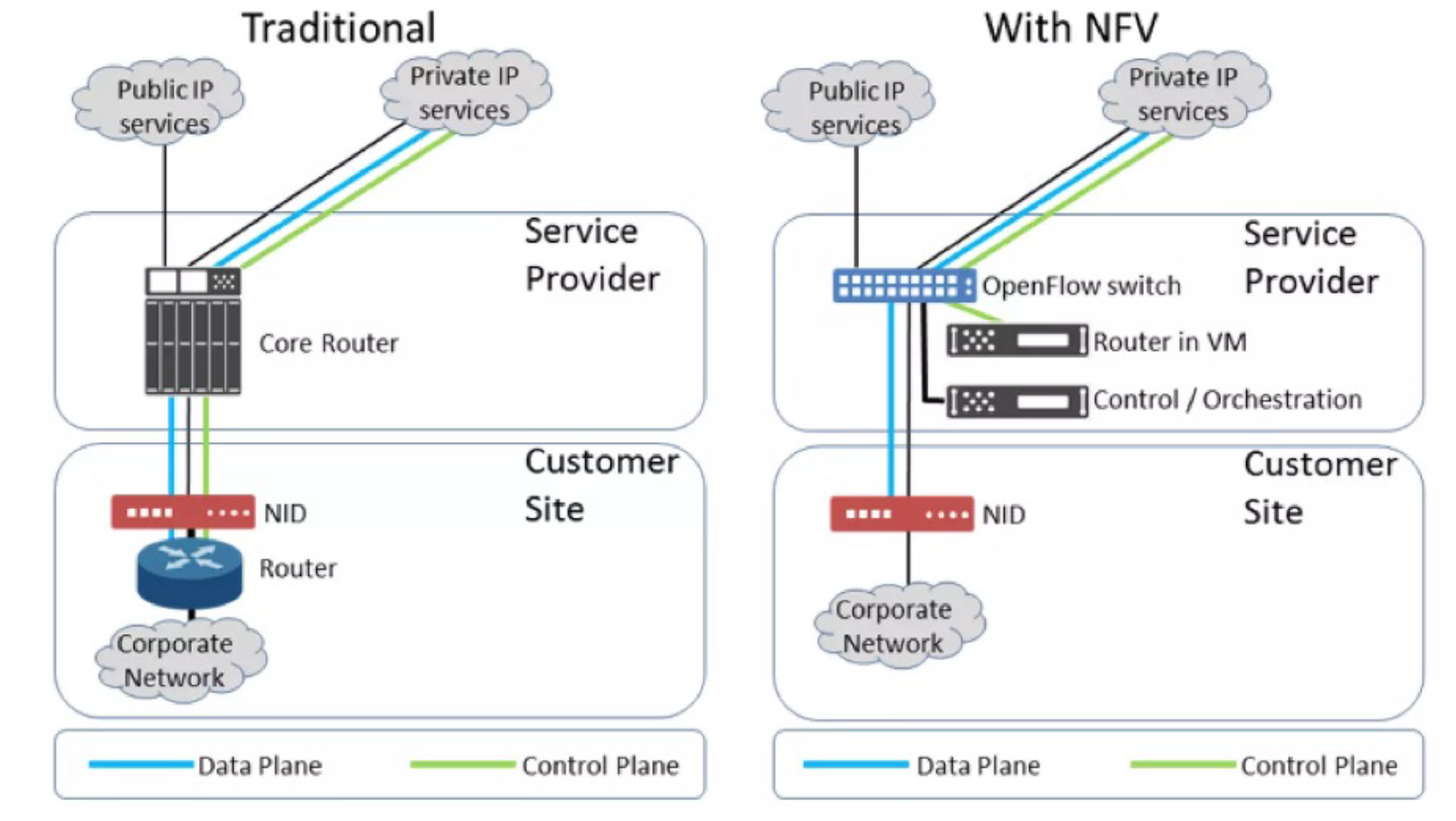
전통적인 구조 (Traditional)
- 서비스 제공자 (Service Provider): 핵심 라우터(Core Router)를 통해 퍼블릭 IP 서비스와 프라이빗 IP 서비스를 제공한다. 이 라우터는 높은 성능을 요구하는 물리적 장비로 구성되어 있다.
- Customer Site: 고객 측면에는 NID(Network Interface Device)와 기업 네트워크를 연결하는 라우터가 있다. 이 라우터는 외부 네트워크와 기업 내부 네트워크 간의 트래픽을 관리한다.
NFV를 사용한 구조 (With NFV)
- 서비스 제공자 (Service Provider): 가상화된 라우터(Router in VM)를 사용하고, OpenFlow 스위치와 같은 SDN(Software-Defined Networking) 요소를 통합하여 더 유연하고 확장 가능한 네트워크 관리를 제공한다. 이 구조에서는 또한 중앙 제어 및 오케스트레이션(Control / Orchestration) 기능을 통해 네트워크 자원을 더 효율적으로 관리할 수 있다.
- Customer Site: 고객 측면에는 여전히 NID를 통해 연결되며, 내부적으로는 NFV 기반의 가상화된 라우터를 사용할 수 있다. 이러한 변화는 기존 물리적 인프라에 비해 더 높은 유연성과 비용 효율성을 제공한다.
Data Plane과 Control Plane
- Data Plane (데이터 플레인): 네트워크 데이터 패킷이 실제로 전송되는 경로
- Control Plane (제어 플레인): 네트워크를 제어하고 관리하는 로직과 프로토콜이 작동하는 영역이다. NFV 환경에서는 이 제어 플레인이 가상화되고 중앙에서 관리될 수 있어, 더 빠르고 유연한 네트워크 변경이 가능하다.
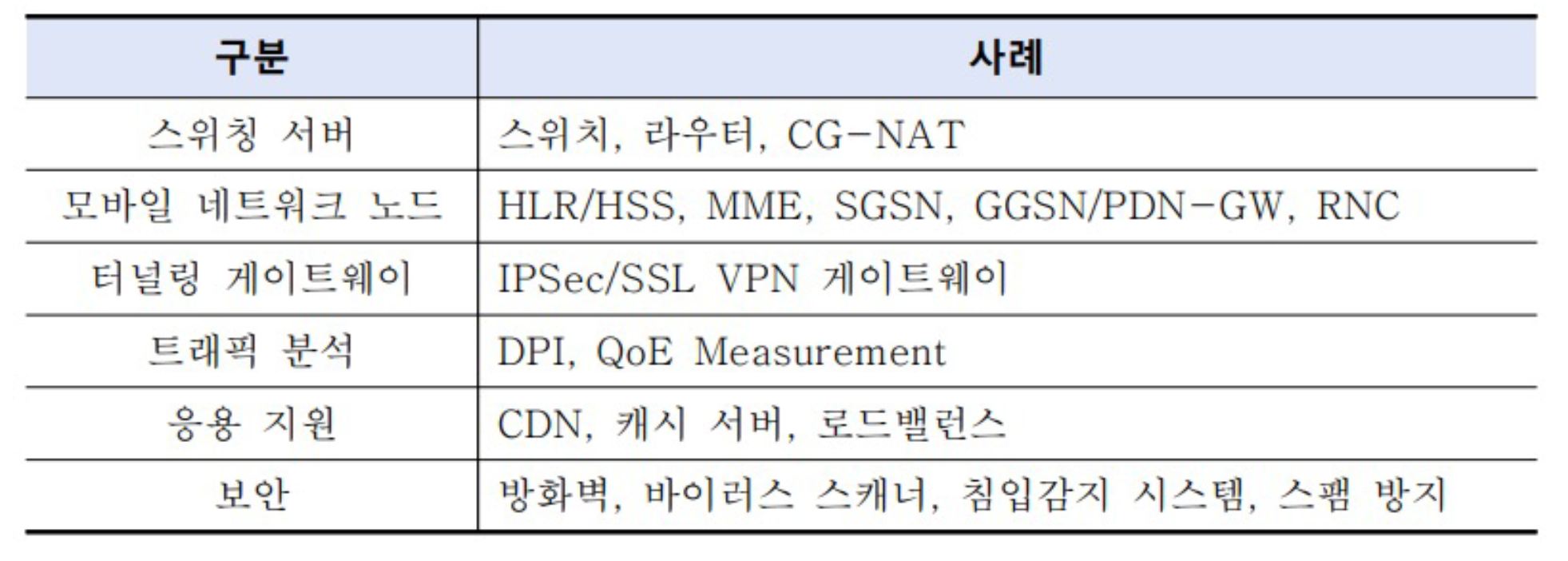
NFV 적용 가능한 네트워크 구성 요소
'CS > 클라우드 컴퓨팅' 카테고리의 다른 글
| [클라우드] 9. MSA (MicroService Architecture) (1) | 2024.05.16 |
|---|---|
| [클라우드] 8. 스토리지 가상화 (Storage Virtualization) (0) | 2024.05.10 |
| [클라우드] 6. Kubernetes (쿠버네티스) (0) | 2024.04.17 |
| [클라우드] 5. 네크워크 가상화(Network Virtualization) (0) | 2024.04.04 |
| [클라우드] 4. Container (Docker) (0) | 2024.03.21 |




댓글