이번에는 Urdego의 모니터링 구축 과정에 대해 다뤄볼려 합니다.
MSA 에서 서비스가 분산되어 있는데 모니터링을 어떻게 해야 할까 🤔
모니터링 (Monitoring)
모니터링의 정의는 인프라 및 응용프로그램의 성능이나 효율성을 확인하는 작업이다.
각 대상에서 수집한 Metric 정보를 통해서 리소스, 사용률, 트래픽등을 수치로 표현하는 기능인 셈이다.
여기서 Metric 정보를 수집하는 방법에는 Push 와 Pull 2가지 방식이 존재한다.
Push-based System

Push 방식은 애플리케이션에서 데이터들을 직접 모니터링 시스템으로 보내주는 방식이다.
새로운 애플리케이션이 추가되더라도 모니터링 시스템에 데이터를 보내기만하면 되지만 Metric을 중앙에서 정의하기 때문에 새로운 Metric을 수용하기위해선 중앙시스템에서 변경사항을 반영해줘야 한다. 보통 수집대상이 Auto-Scaling 등으로 가변적일때 사용한다.
종류로는 InfluxDB, Graphite, Nagios 등등이 있다.
Pull-based System

Pull 방식은 모니터링 시스템에서 모니터링할 애플리케이션에 직접 접속하여 필요한 데이터를 당겨오는 방식이다.
모니터링 대상이 되는 애플리케이션들은 자체적으로 Metric을 노출하는 엔드포인트를 제공해야 하며, 모니터링 시스템은 주기적으로 해당 엔드포인트에 접근하여 데이터를 수집한다.
대표적인 도구로는 Prometheus, Datadog, collectd 등등이 있다.
애플리케이션의 성능이나 효율성을 보기위해 모니터링 시스템을 구축하는데 Push 방식은 애플리케이션에서 데이터를 직접 모니터링 시스템에 보내주기 때문에 자칫 모니터링을 위해서 애플리케이션에 부담을 주게되는 기이한(?) 현상이 발생할 수도 있다.
그래서 어데고에 사용할 모니터링 방식은 Pull-based System로 선택하려 한다. 🫡
먼저, 사용할 도구를 선택하기 전에 Metric을 어디서 어떻게 얻어서 도구들에 전달할지를 생각해야한다.
어데고 프로젝트는 대부분 스프링 부트로 이루어져 있는데, 스프링 부트에서는 Spring Boot Actuator를 사용하면 애플리케이션의 상태와 성능이 대한 다양한 Metric들을 쉽게 수집이 가능하다는것!! Spring갓
Spring Boot Actuator
Spring Boot Actuator는 HTTP 엔드포인트나 JMX 빈을 이용해 모니터링 데이터 (상태, 메트릭 등)을 제공한다. 의존성만 추가하면 제공되는 엔드포인트를 바로 사용가능!
implementation 'org.springframework.boot:spring-boot-starter-actuator'
기본적으로 제공되는 엔드포인트들은 공식문서에서 확인할 수 있고 초기에는 대부분의 엔드 포인트가 비활성화 되어 있다.

이렇게 엔드포인트를 활성화하려면 yaml 환경 설정으로 엔드포인트를 노출시켜야한다. 주의할점은 제공되는 엔드포인트들이 애플리케이션에 대해 민감한 정보로부터 애플리케이션 동작에도 영향이 가는 직접적인 엔드포인트들도 포함하고 있어서 언제 어떤 엔드포인트만 노출할 것인지 신중하게 선택해야 한다.
management:
endpoints:
web:
exposure:
include: "*" // health, info, metrics
현재는 위 사진과 같이 모두 열어둔 상태
Metrics
주로 사용되는 metrics 엔드포인트에 대해 알아보자
metrics 엔드포인트들은 Dimensional 구조로 메트릭을 제공하는데 /metrics/** 형태로 원하는 메트릭을 요청하면 tag형식의 key/value 구조로 데이터를 제공한다.
이런 Tag 방식은 Spring Boot2부터 제공되어 여러 관점에서 메트릭을 분석하기 쉽게 Tag를 추가/삭제 가능
예시로 JVM 사용량을 보여주는 엔드포인트에 접근해보면
http://localhost:8080/actuator/metrics/jvm.memory.used
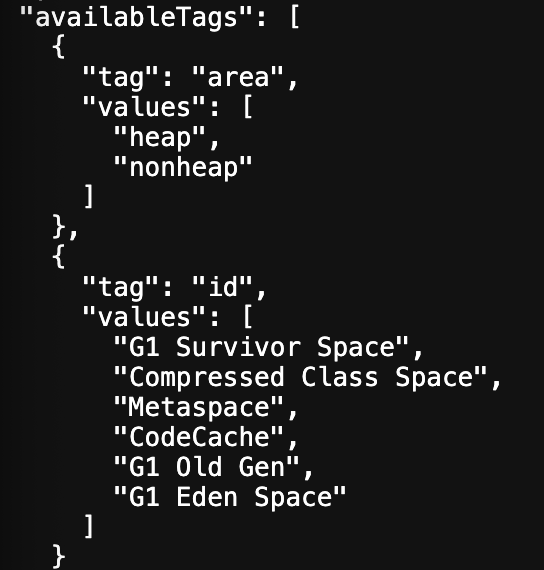
여기서 만약 heap 영역을 보고싶으면 ?tag=area.heap 만 쿼리에 붙여주면 되는것!
RED Method
모니터링 환경을 구축할 때, 시스템의 상태, 성능을 효과적으로 감시하기 위해 다양한 메트릭을 사용하는데, 그중 하나가 RED Method이다. RED Method는 특히 MSA에서 유용한 모니터링 방법론으로 Prometheus와 Grafana의 주요 개발자인 Tom Wilkie가 제안한 메소드이다.
- (Request) Rate : 요청수
- (Request) Errors : 에러 수
- (Request) Duration : 응답 시간
이런 RED Method에 필요한 메트릭을 제공하는 엔드포인트는 아래와 같다.
http://localhost:8080/actuator/metrics/http.server.requests
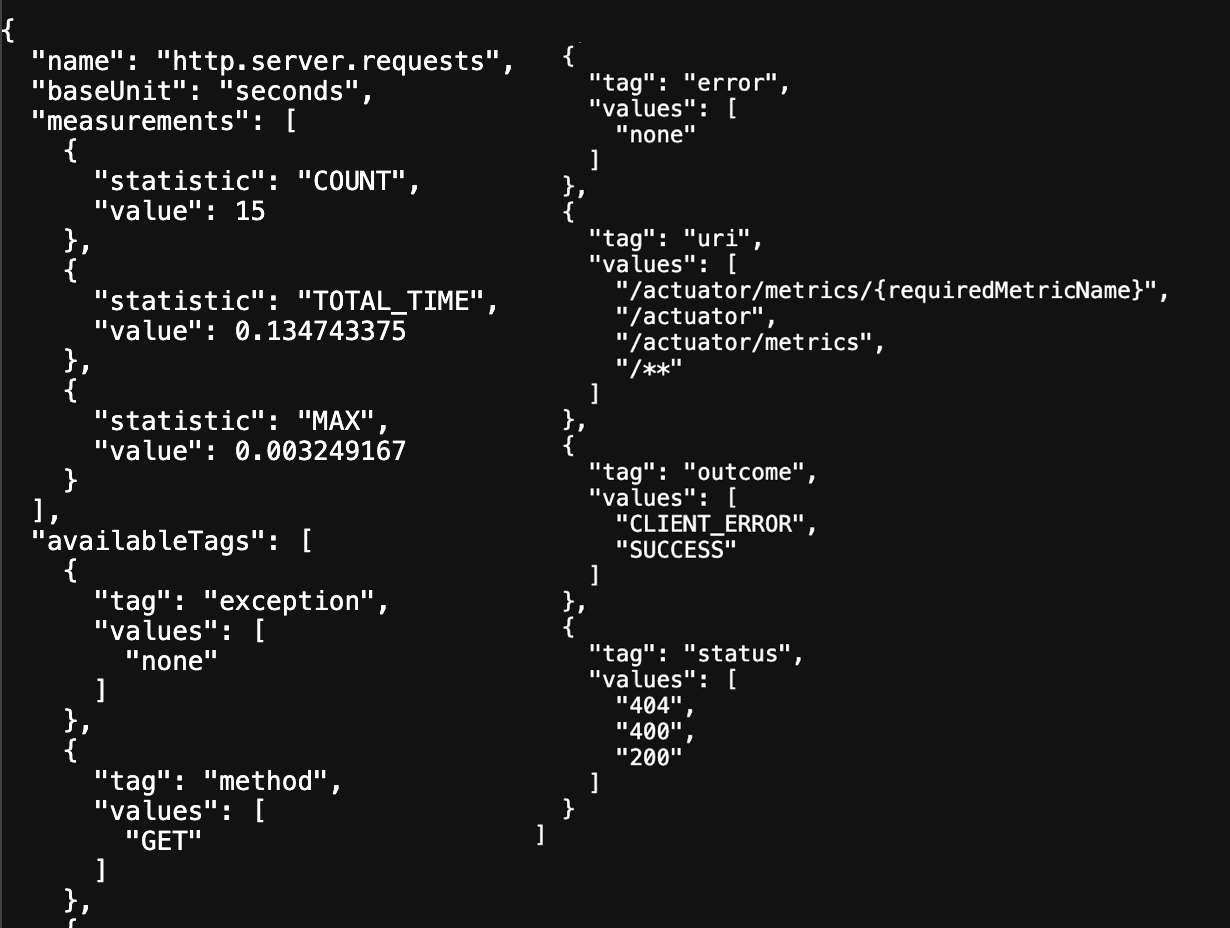
강력한 Tag 기능을 통해 메트릭을 쉽게 파악이 가능하다.
outcome은 너무 많은 status 코드들을 단순화 시킨 것으로 응답 시간을 측정할 때 실패와 성공을 구분해서 봐야할 필요가 있으므로 자주 사용된다.
Rate and Duration of Success
- http.server.requests?tag=outcome:SUCCESS
Rate and Duration of Errors
- http.server.requests?tag=outcome:SERVER_ERROR
http.server.requests?tag=exception:IllegalArgumentException
처럼 특정 예외에 대한 메트릭도 수집할 수 있다.
Micrometer
지금까지는 하나의 메트릭을 얻기 위해 하나의 url을 통해 접근했는데 이렇게 하나하나 메트릭을 수집하면 부하를 감시하기 위한 모니터링 플랫폼 자체가 애플리케이션에 부하를 줄 수 있는 기이한(?) 상황이 생길 수 있다. 그래서 이를 위해 Micrometer가 필요하다!!

공식문서에서는 이렇게 소개한다.
- Vendor lock-in 없이 JVM 기반의 애플리케이션 코드를 측정 가능
- SLF4J 가시성 버전
- 추상화 인터페이스인 MeterRegistry를 제공해 메트릭 수집/저장 가능
이 MeterRegistry의 다양한 구현체가 존재하는데 각 구현체는 특정 모니터링 시스템과 호환된다. 예를들어 Prometheus, Datadog, Graphite, InfluxDB 등 다양한 모니터링 시스템에 맞춘 MeterRegistry 구현체가 존재!
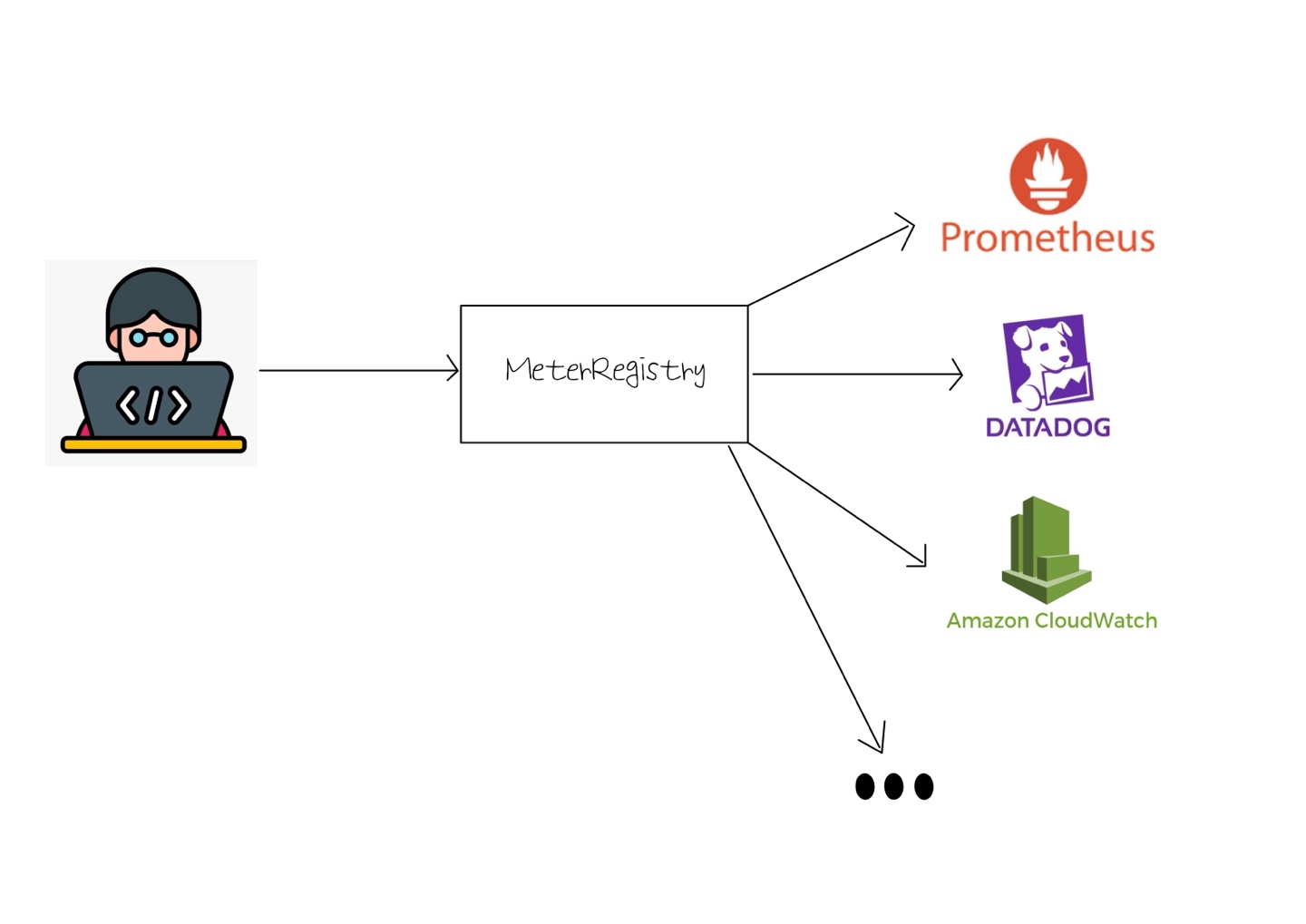
이역시 MeterRegistry 구현체를 사용하고 싶으면 간단한 의존성 추가만 해주면 된다.
implementation 'io.micrometer:micrometer-registry-prometheus'
이제 actuator 엔드포인트에 prometheus라는 새로운 엔드포인트가 자동으로 추가되고, prometheus 모니터링 시스템에서 해당 엔드포인트를 통해 필요한 메트릭을 수집할 수 있게 된다.
http://localhost:8080/actuator/prometheus
# Actuator
management:
endpoints:
web:
exposure:
include: prometheus
enabled-by-default: false
endpoint:
prometheus:
enabled: true
server:
port: [설정한 포트]
base-path: [설정한 경로]- 모든 엔드포인트를 사용하지 않겠다는 의미로 enabled-by-default 속성을 false로 초기화한 뒤 사용할 엔드포인트만 include해서 사용하자
- shutdown 엔드포인트는 절대 사용하지 말자 애플리케이션의 실행을 중단시킬 수 있다..
- Acuator는 서비스 운영에 사용되는 포트와 다른 포트를 사용하자 -> 웹 사이트를 공격할 때 보통 Actuator 페이지를 스캐닝하기때문에 포트를 달리해서 1차적으로 보호하자
- Acutator의 default경로보다 프로젝트 고유의 경로로 변경해서 운영하자 -> Actuator를 그냥 적용했을때 default는 전부 /actuator/** 형식이다. 따라서 예측되지 않게 프로젝트 고유의 경로로 변경해 운영하는것이 좋다.
최종적으로 http://localhost:[설정한 포트]/[설정한 경로]~~~/ 엔드포인트를 사용해 프로메테우스 메트릭을 수집할 수 있게 된다
이제 추가해준 엔드포인트를 통해 Prometheus로 메트릭을 수집한 후 Grafana로 시각화 해보자!
먼저 메트릭 수집 도구로 Prometheus, 수집한 메트릭을 시각화하기 위한 도구로 Grafana를 선택했는데 그이유는 다음과 같다.
Prometheus
오픈소스 시스템 모니터링 및 경로 툴킷으로 시계열 데이터 수집과 쿼리에 최적화 되어있기 때문에 시스템 상태를 실시간으로 모니터링하고 감지하는게 매우 좋다. 또 경고 규칙을 설정할 수 있어서 지정한 조건이 충족되면 알림을 받아 신속하게 대응도 가능하다.
일단 많은 프로젝트에 사용되어 참고 자료가 많고 Spring Actuator와 쉽게 통합되어 다양한 메트릭을 쉽게 수집할 수 있기에 선택했다.
Grafana
Grafana는 수집된 메트릭 정보들을 시각화하는 도구로 Prometheus와 통합 시 시너지 효과가 좋다. 원하는대로 대시보드를 커스터마이징 가능하고 다양한 대시보드 템플릿을 선택할 수 있다. 또 Prometheus에서 설정한 경고를 시각적으로 관리 가능하고 Slack 이나 이메일로 알림을 보낼 수 있기 때문에 선택했다.
서버에 바로 올리기보단 로컬에서 연결해보고 배포하려고 한다!
먼저 아래와같이 작성후 docker에 올려줬다
version: '3'
services:
prometheus:
image: prom/prometheus:latest
container_name: prometheus
ports:
- "9090:9090"
volumes:
- ./prometheus.yml:/etc/prometheus/prometheus.yml
networks:
- monitoring
grafana:
image: grafana/grafana:latest
container_name: grafana
ports:
- "3000:3000"
volumes:
- grafana-storage:/var/lib/grafana
depends_on:
- prometheus
networks:
- monitoring
networks:
monitoring:
driver: bridge
volumes:
grafana-storage:
이때 주의할 점은 두 모니터링 도구를 모두 현재 띄워진 spring boot 프로젝트들과 동일한 network로 묶어줘야한다. 실제 배포 환경에서는 보안을 위해 최소한의 포트만 노출시킬 것이라 IP 주소를 통한 직접 연결이 아닌 같은 networks로 묶어 container 이름으로 연결을 해줘야 한다.
Prometheus Target 설정
위의 docker-compose.yml 중 volumes 설정을 보면 prometheus.yml을 매핑해주고 있는데 prometheus.yml 파일이 Prometheus의 설정 파일로 모니터링 대상(Target)을 정의하는 역할을 한다.
따라서 이 파일에 이전에 Spring Actuator를 이용해 메트릭을 노출해줬던 엔드포인트를 연결해주어야 한다. 이때도 역시 나중에 차단해줄 엔드포인트이기 때문에 직접 연결이 아닌 networks의 컨테이너명을 사용해 연결해준다.
global:
scrape_interval: 5s
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['컨테이너명:[비밀포트]']
- job_name: 'gateway-service'
metrics_path: '/[비밀경로]'
static_configs:
- targets: ['컨테이너명:[비밀포트]']
- job_name: 'discovery-service'
metrics_path: '/[비밀경로]'
static_configs:
- targets: ['컨테이너명:[비밀포트]']
- job_name: 'content-service'
metrics_path: '/[비밀경로]'
static_configs:
- targets: ['컨테이너명:[비밀포트]']
이렇게 설정해주면 Prometheus는 해당 엔드포인트에서 메트릭을 수집할 수 있게 된다.
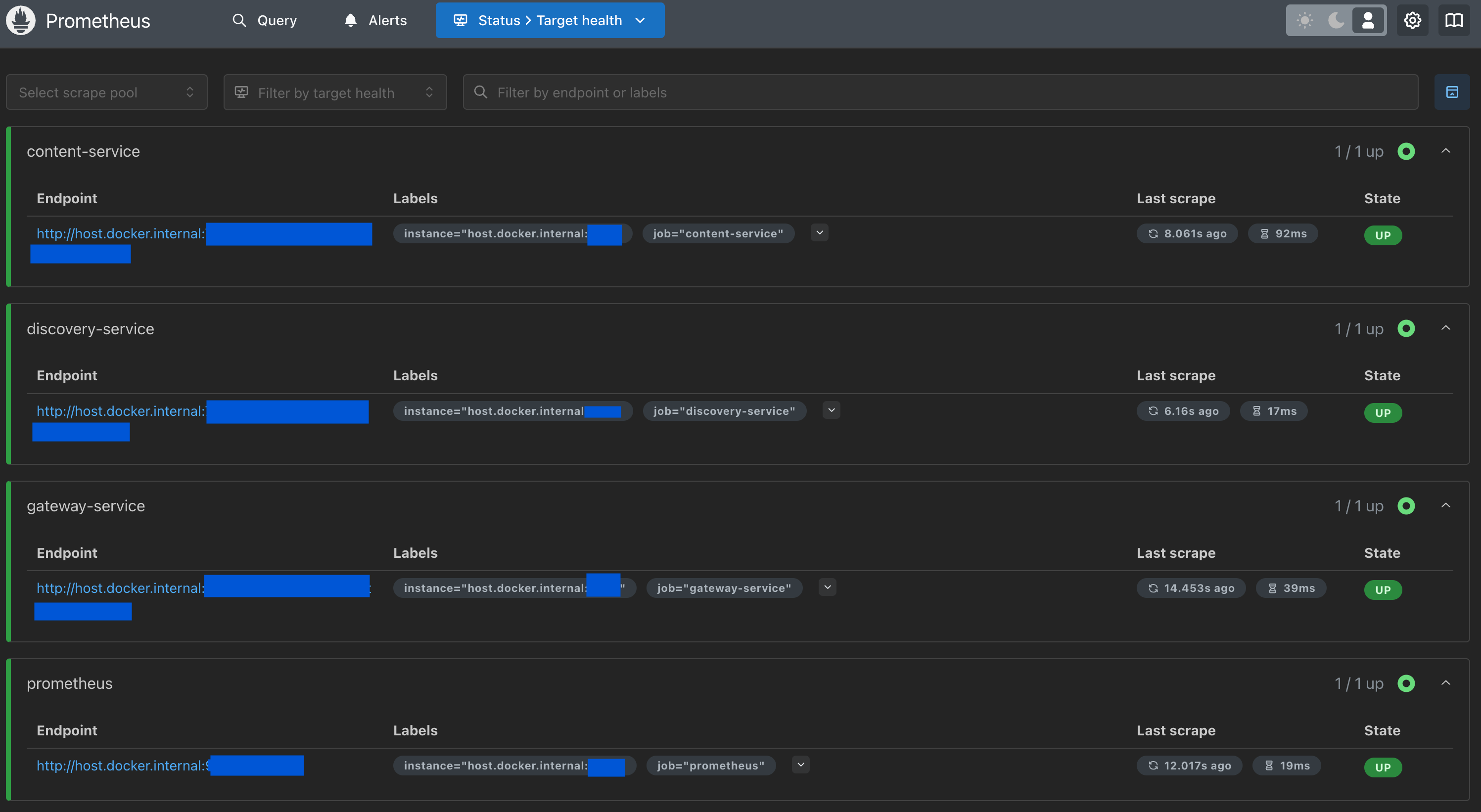
수집한 메트릭을 시각화하기 위해 Grafana에 접속해서 Prometheus를 연결해주자!
Grafana Labs에서 다양한 대시보드 템플릿을 제공하고 있는데 많이 사용되고 있는 Spring boot 2.1 System Monitor를 사용했다.
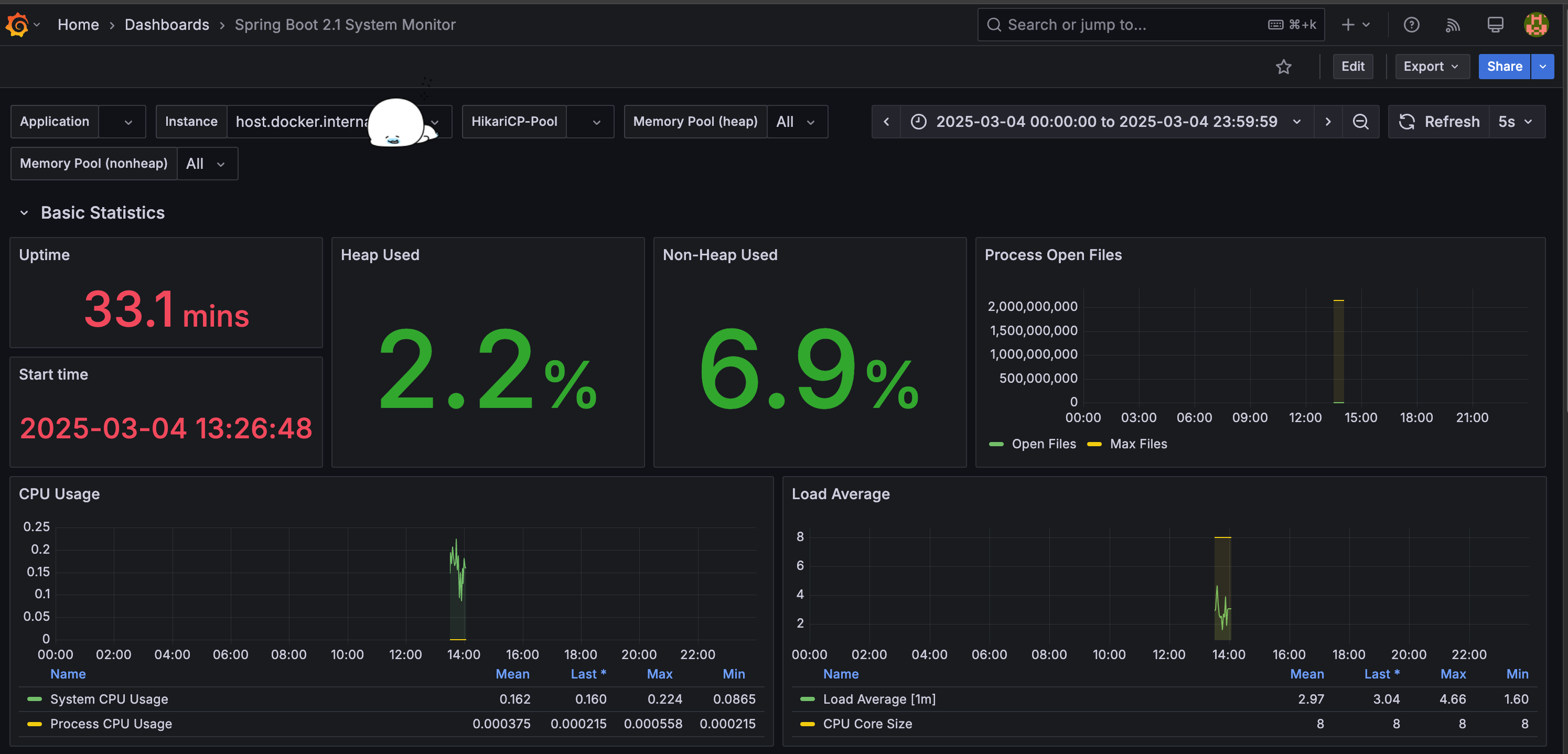
Tomcat 설정 적용
제공되는 템플릿에서는 Jetty Statistics가 제공되지만 Spring Boot는 기본적으로 Tomcat을 내장 서버로 사용하기에 Tomcat관련 메트릭으로 교체해야 한다. 이를위해 Tomcat의 MBeanRegistry 기능을 활성화 시켜 Prometheus가 Tomcat에서 제공하는 메트릭을 수집할 수 있게 하자
server:
tomcat:
mbeanregistry:
enabled: true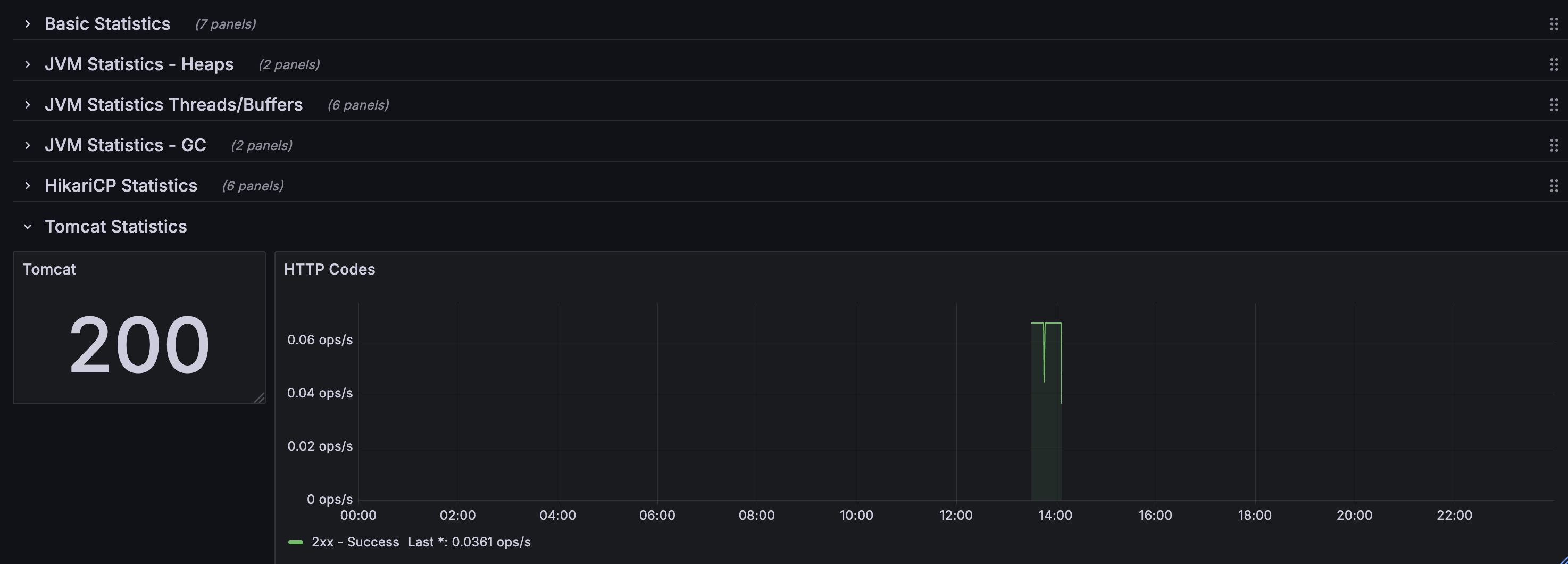
이제 서버에 올려보자!
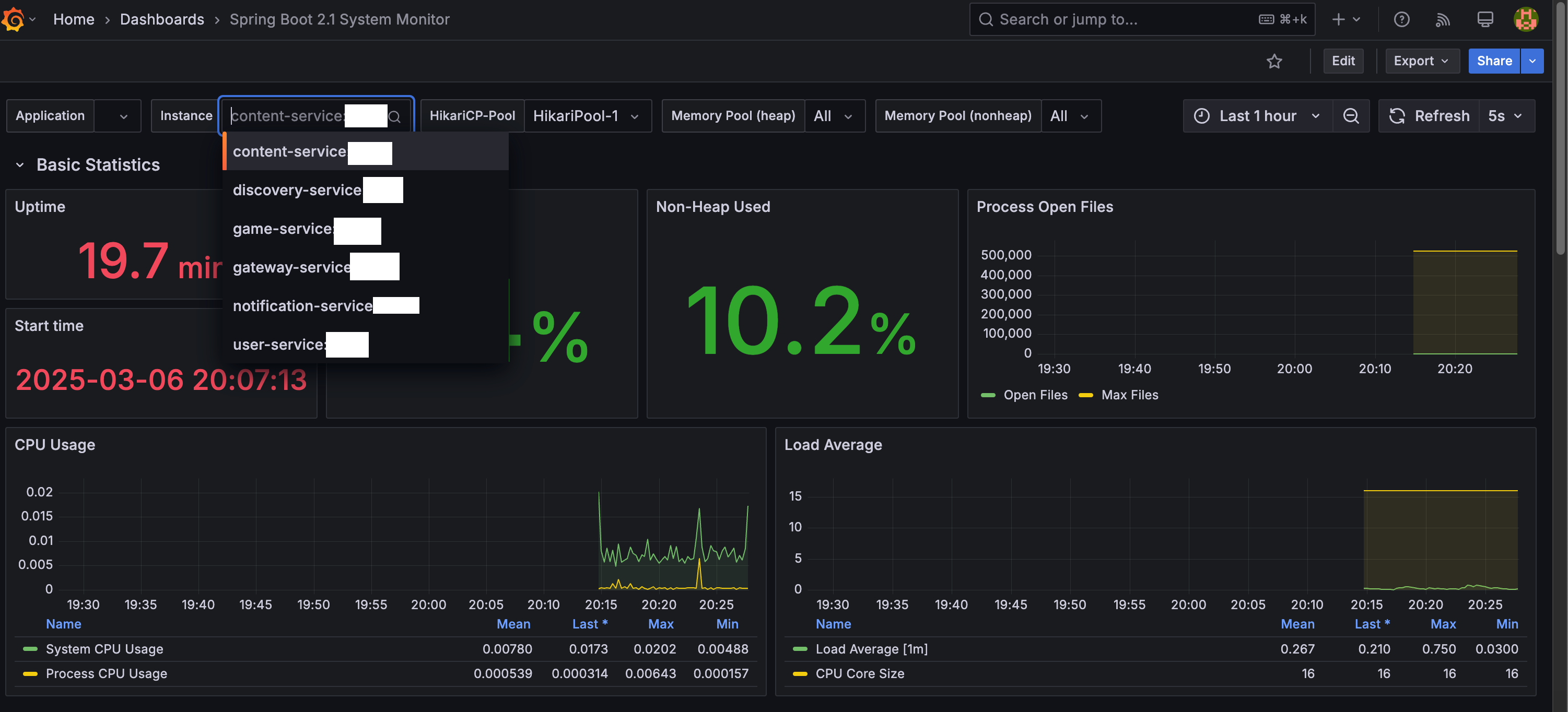
다음엔 로그관리 로깅도 올릴예정~~
'Project > 어데고 (urdego)' 카테고리의 다른 글
| [TensorFlow - NSFW] 부적절한 컨텐츠 감지 (1) | 2025.02.18 |
|---|---|
| [깃허브 액션 - CI&CD] Self-hosted Runner (2) | 2025.01.12 |
| [홈서버 구축] Public Cloud(AWS) -> On-premise(홈서버) 구축 전환 (1) | 2024.12.18 |



댓글