[실전 카프카 개발부터 운영까지 by 고승범]
Kafka -> LinkedIn에서 처음 개발
도입사례
잘란도의 규모가 커지고 사업이 다각화되면서 내부적으로 데이터에 대한 온갖 요구사항이 불거지기 시작 -> 데이터의 변화가 스트림으로 컨슈머 측에 전달되는 이벤트 드리븐 시스템으로 전환 -> 이를 통해 컨슈머들은 자신의 오규사항에 따라 데이터를 처리하거나 구독이 가능
Event Driven Architecture
분산 아키텍처 환경에서 이벤트를 생성하고 발행된 이벤트를 수신자에게 전송하는 구조
수신자는 그 이벤트를 처리하는 방식으로, 상호 간 결합도를 낮추기 위해 비동기 방식으로 메시지를 전달하는 패턴이다.
각 마이크로서비스는 함께 작동하지만 서로 다른 비즈니스 로직을 적용하고 자체 출력 이벤트를 보낼 수 있으며
주로 Message Broker ( Kafka, RabbitMQ) 와 결합하여 구성된다.
이벤트는 형식을 제외하고 서로에 대해 알 필요는 없다.
이벤트 드리븐 시스템에서 가장 중요한 사항은 인바운드 데이터와 아웃바운드 데이터가 동일해야 한다는 점 -> 여러 부서에서 데이터를 소비하는데 서로 소비한 데이터가 불일치하거나 일부 데이터가 누락된다면 데이터에 대한 신뢰성을 잃고 쓸모없는 데이터가 된다.
이러한 현상을 방지하기 위해서 인/아웃바운드 데이터가 서로 일치하는지 검증해야하는데 이를 위한 데이터 파이프라인이 추가됨에 따라 데이터 검증에 대한 피로도가 증가하게 된다.
초기의 잘란도는 데이터의 오차를 줄이려는 목적으로 API와 PostgreSQL로 연결하는 CRUD 타입으로 구성하고 데이터베이스 업데이트가 완료된 후에 아웃바운드 이벤트가 생성되도록 구성하여 오차는 줄일 수 있었지만 동기 방식에서 다음과 같은 한계가 발생했다.
- 여러 네트워크 환경에서 모든 데이터 변경에 대한 올바른 전달 보장 문제
- 동일한 데이터를 동시에 수정하면서 정확하게 순서를 보장해야 하는 문제, 또한 수정된 이벤트들을 정확한 순서대로 아웃바운드 전송 문제
- 빠른 전송, 대량의 배치 전송을 위한 클라이언트를 지원하기 어려운 문제
∴ 잘란도는 이러한 한계를 극복하고자 비동기 방식의 대표 스트리밍 플랫폼, 카프카 도입

카프카를 구성하는 요소
- 주키퍼 (ZooKeeper): 아파치 프로젝트 애플리케이션 이름, 카프카의 메타데이터 관리 및 브로커의 정상상태 점검 담당한다.
- 카프카 (Kafka) or 카프카 클러스터 (cluster): 아파치 프로젝트 애플리케이션 이름, 여러대의 브로커를 구성한 클러스트를 의미
- 브로커 (broker): 카프카 애플리케이션이 설치된 서버나 노드를 말한다.
- 프로듀서 (producer): 카프카로 메시지를 보내는 역할을 하는 클라이언트를 총칭한다.
- 컨슈머 (cunsumer): 카프카에서 메시지를 꺼내가는 역할을 하는 클라이언트를 총칭한다.
- 토픽 (topic): 카파카는 메시지 피드들을 토픽으로 구분하고, 각 토픽의 이름은 카프카 내에서 고유한다.
- 파티션 (partition): 병렬 처리 및 고성능을 얻기 위해 하나의 토픽을 여러 개로 나눈 것을 말한다.
- 세그먼트 (segment): 프로듀서가 전송한 실제 메시지가 브로커의 로컬 디스크에 저장되는 파일을 말한다.
- 메시지 (message) or 레코드 (record): 프로듀서가 브로커로 전송하거나 컨슈머가 읽어가는 데이터 조각을 말한다.
리플리케이션 (replication)
카프카에서 리플리케이션이란 각 메시지들을 여러 개로 복제해서 카프카 클러스터 내 브로커들에 분산시키는 동작을 의미한다. 이러한 리플리케이션 덕분에 하나의 브로커가 종료되더라도 카프카는 안정성을 유지할 수 있다.
--partition 1, --replication-factor 3
앞서 위와같은 옵션을 이용한 명령어로 peter-overview01 토픽을 만들었다. replication-factor는 카프카 내 몇 개의 리플리케이션을 유지하겠다는 의미이다. 즉 3이라면 원본을 포함한 리플리케이션 총 3개가 있다는 뜻 (정확하게 말하자면 토픽이 리플리케이션이 되는 것이 아니라 토픽의 파티션이 리플리케이션이 된다.)
테스트나 개발 환경: 리플리케이션 팩터 수 1로 설정
운영 환경 (로그성 메시지로서 약간의 유실 허용): 리플리케이션 팩터 수 2로 설정
운영 환경 (유실 허용x): 리플리케이션 팩터 수 3로 설정
파티션 (partition)
하나의 토픽이 한 번에 처리할 수 있는 한계를 높이기 위해 토픽 하나를 여러 개로 나눠 병렬 처리가 가능하게 하는 것
파티션 번호는 0부터 시작
파티션의 수는 토픽을 생성할 때 옵션으로 설정
파티션의 수는 언제든 늘릴 수 있지만 한번 늘린 파티션은 줄일 수 없음을 명심
적절한 파티션 수를 산정하기 위해 계산해주는 공식을 제공하는 컨플루언트 사이트 참고 https://eventsizer.io/
https://eventsizer.io/
Sizing Calculator for Apache Kafka and Confluent Platform Public access to the Sizing Calculator has been removed for the foreseeable future as we work on a comprehensive review and upgrade. We truly value your feedback and apologise for any inconvenience
eventsizer.io
세그먼트 (segment)
메시지들은 세그먼트라는 로그 파일의 형태로 브로커의 로컬 디스크에 저장된다.
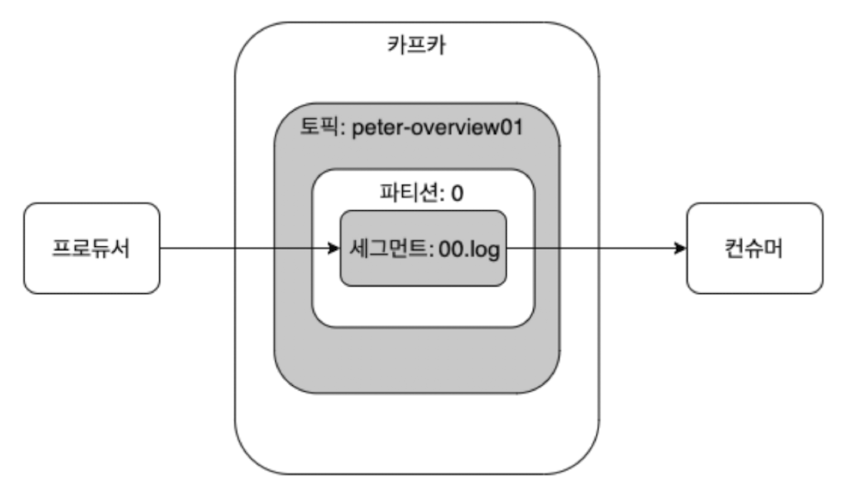
- 프로듀서는 카프카의 peter-overview01 토픽으로 메시지를 전송
- peter-overview01 토픽은 파티션이 하나뿐이므로, 프로듀서로부터 받은 메시지를 파티션0의 세그먼트 로그 파일에 저장
- 브로커의 세그먼트 로그 파일에 저장된 메시지는 컨슈머가 읽어갈 수 있음
'Develop > Kafka' 카테고리의 다른 글
| Kafka 핵심 개념 (1) | 2025.01.02 |
|---|

댓글