[실전 카프카 개발부터 운영까지 by 고승범]
분산 시스템
분산 시스템은 쉽게말해 네트워크상에서 연결된 컴퓨터들의 그룹을 말하며 단일 시스템이 갖기 못한 높은 성능을 목표로 한다. 성능이 높다는 장점 이외에도 하나의 서버 또는 노드가 장애가 발생할 때 다른 서버 또는 노드가 대신 처리하므로 장애 대응이 탁월하다. 또한 부하가 높은 경우에는 시스템 확장이 용이하다.
카프카도 분산 시스템으로 최초 구성한 클러스터의 리소스가 한계치에 도달하여 더욱 높은 메시지 처리량이 필요할 경우, 브로커를 추가하는 방식으로 확장이 가능하다.
카프카에서 브로커는 온라인 상태에서 매우 간단하게 추가가 가능하다. 최초에 하나의 카프카 클러스터가 총 3대의 브로커로 운영 중이여도 서비스가 폭발적으로 증가할 경우 나중엔 총 30대 또는 50대 그 이상의 브로커 수로 확장이 가능하다.
페이지 캐시 (page cache)
카프카는 높은 처리량을 얻기 위해 몇가지 기능을 추가했는데 그중 가장 대표적인 기능이 페이지 캐시 이다. 운영체제 OS는 성능을 높이기 위해 꾸준히 진화하고 개선되고 있는데 특히 페이지 캐시의 활용이 대표적이다. 카프카 역시 OS의 페이지 캐시를 활용하는 방식으로 설계되어 있다.
페이지 캐시는 직접 디스크에 읽고 쓰는 대신 물리 메모리 중 애플리케이션이 사용하지 않는 일부 잔여 메모리를 활용한다. 이를 이용하면 디스크 I/O에 대한 접근이 줄어드므로 성능을 높일 수 있다.

배치 전송 처리
카프카는 프로듀서, 컨슈머 클라이언트들과 서로 통신하고 이들 사이에서 수많은 메시지를 주고 받는다. 이때 발생하는 수많은 통신을 묶어서(batch) 처리하여, 단건으로 통신할 때에 비해 네트워크 오버헤드를 줄일 수 있고 더욱 빠르고 효율적으로 처리할 수 있다.
간단히 예를 들자면
기차가 한번 움직이는데 고비용이 필요하다면 실시간 그룹보다 배치 그룹이 효율적일 것이다. 실시간 그룹의 첫 승객은 목적지에 누구보다 빠르게 도착하지만 실시간 그룹의 마지막 승객과 배치그룹의 승객의 도착시간과 비슷할 것이다.
압축 전송
카프카는 메시지 전송 시 좀 더 성능이 높은 압축 전송을 사용하는 것을 권장한다. 카프카에서 지원하는 압축 타입은 gzip, snappy, lz4, zstd 등이 있다. 압축만으로도 네트워크 대역폭이나 회선 비용 등을 줄일 수 있는데 앞서 설명한 배치 전송과 결합해 사용하면 더욱 높은 효과를 지닌다. (파일 하나 압축보다 비슷한 파일 10개, 20개 압축하는 효율)
압축 타입에 따라 약간의 특성이 있어서 일반적으로 높은 압축률이 필요하다면 gzip, zstd를 권장하고 빠른 응답속도가 필요하다면 lz4, snappy를 권장한다.
토픽, 파티션, 오프셋
카프카는 토픽 (topic)이라는 곳에 데이터를 저장하는데, 우리가 흔히 사용하는 이메일 주소 정도의 개념으로 보면 된다.
토픽은 병렬 처리를 위해 여러 개의 파티션 (partition)이라는 단위로 다시 나뉜다. 이 파티션의 메시지가 저장되는 위치를 오프셋 (offset)이라고 부르며 오프셋은 순차적으로 증가하는 숫자 형태이다.
고가용성 보장
카프카는 앞서 설명한 것처럼 분산 시스템이기에 하나의 서버가 다운되어도 다른 서버가 장애 서버의 역할을 대신해 안정적인 서비스가 가능하다. 이러한 고가용성을 보장하기 위해 카프카는 리플리케이션 기능을 제공한다.
카프카에서 제공하는 리플리케이션은 토픽 자체를 복제하는 것이 아닌 토픽의 파티션을 복제하는 것이다. 원본과 리플리케이션을 구분하기 위해 흔히 마스터, 미러 같은 용어를 사용하는데 카프카에서는 리더 (leader)와 팔로워 (follower) 라고 부른다.
일반적으로 팔로워 수가 많을수록 안정적이고 좋을 거라 생각할 수 있겠지만 딱히 좋은 것은 아니다. 팔로워의 수만큼 결국 브로커의 디스크 공간도 소비되므로 이상적인 리플리케이션 팩터 수를 유지해야 한다. 따라서 일반적으로 카프카에서는 리플리케이션 팩터 수를 3으로 구성하도록 권장한다.
주키퍼의 의존성
카프카를 언급하면서 빼놓을 수 없는 부분이 주키퍼(zookeeper)이다. 카프카를 비롯해 아파치 산하 프로젝트인 하둡, 나이파이, 에이치베이스 등 많은 분산 애플리케이션에서 코디네이터 역할을 하는 애플리케이션으로 사용되고 있는데,
주키퍼는 여러 대의 서버를 앙상블(클러스터)로 구성하고, 살아 있는 노드 수가 과반수 이상 유지된다면 지속적인 서비스가 가능한 구조이다. 따라서 주키퍼는 반드시 홀수로 구성해야 한다.
지노드 (znode)를 이용해 카프카의 메타 정봉가 주키퍼에 기록되며, 주키퍼는 지노드를 이용해 브로커의 노드관리, 토픽관리, 컨트롤러 관리 등 매우 중요한 역할을 하고 있다. 하지만 최근들어 주키퍼의 성능 한계가 드러나면서 의존성을 제거하려는 움직임이 보이고있고 주키퍼가 삭제된 카프카 버전이 릴리즈되고 있다.
지금은 카프카의 중요한 메타데이터를 저장하고 각 브로커를 관리하는 중요한 역할을 하는 것이 주키퍼 라는 사실만 알고 넘어가자
프로듀서의 기본 동작과 예제
프로듀서 디자인
ProducerRecird 부분이 카프카로 전송하기 위한 실제 데이터이며 레코드는 토픽, 파티션, 키, 밸류로 구성된다.
프로듀서가 카프카로 레코드를 전송할 때, 카프카의 특정 토픽으로 메시지를 전송한다. 따라서 레코드에서 토픽과 밸류(메시지 내용)은 필수값이며, 특정 파티션을 지정하기 위한 레코드의 파티션과 특정 파티션에 레코드들을 정렬하기 위한 레코드의 키는 필수값이 아닌 선택사항이다.
그 다음 각 레코드들은 프로듀서의 send() 메소드를 통해 시리얼라이저, 파티셔너를 거치게 된다. 만약 프로듀서 레코드의 선택사항인 파티션을 지정했다면 파티셔너는 아무 동작하지않고 바로 지정된 파티션으로 전달하지만 파티션을 지정하지 않았다면 파티셔너가 키를 가지고 파티션을 선택해 레코드를 전달한다. 여기서 기본적으로 라운드 로빈(시분할 시스템 - 시간단위로 할당) 방식으로 동작한다.
프로듀서 내부에서 send() 메소드 동작 이후 레코드들을 배치 전송을 위해 파티션별로 모아둔다.
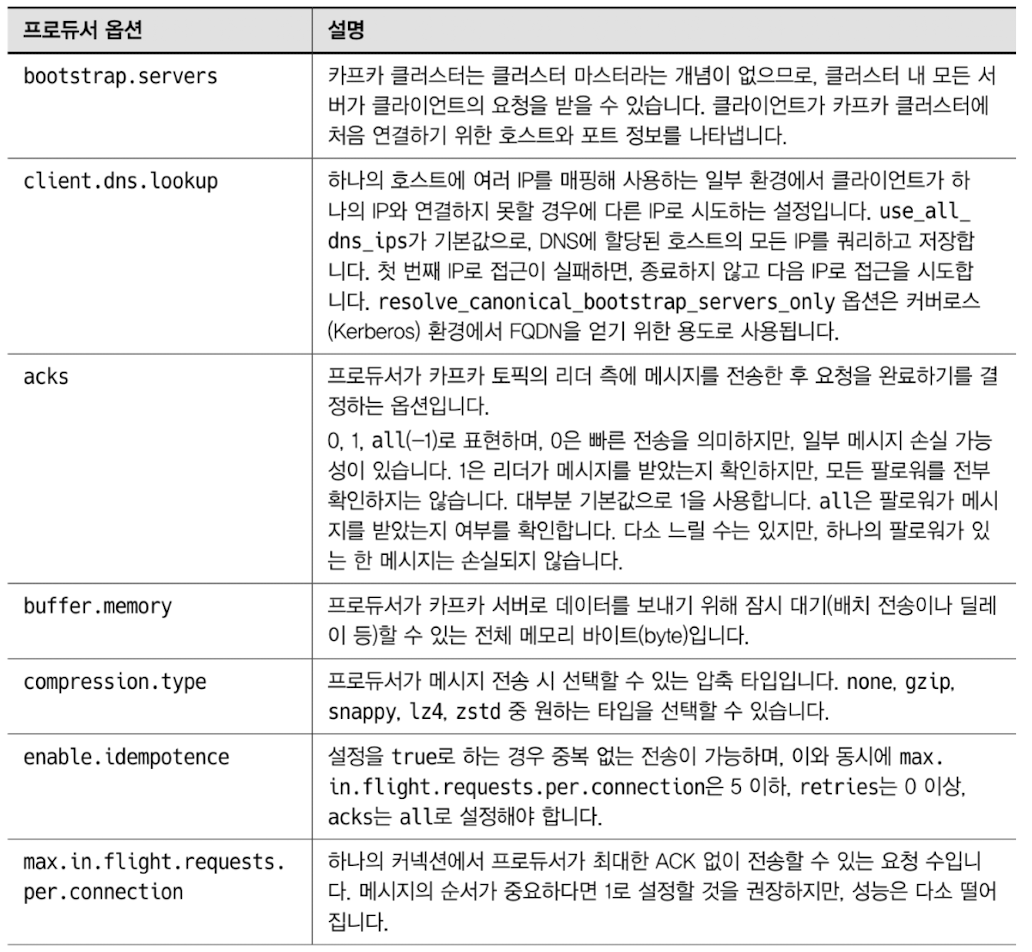
프로듀서의 주요 옵션
자신이 원하는 형태로 카프카를 이용해 메시지를 전송하고자 하다면 프로듀서의 주요 옵션을 잘 파악해야 한다.

프로듀서 예제
프로듀서의 전송 방법은 '메시지를 보내고 확인하지 않기', '동기 전송', '비동기 전송' 이라는 세가지 방식으로 크게 나눌 수 있다.
예제1 - 메시지를 보내고 확인하지 않기
public class ProducerFireForgot {
public static void main(String[] args) {
Properties props = new Properties(); // (1)
props.put("bootstrap.servers", "peter-kafka01.foo.bar:9092,peter-kafka02.foo.bar:9092,peter-kafka03.foo.bar:9092"); // (2)
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); // (3)
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafKaProducer<>(props); // (4)
try {
for (int i = 0; i < 3; i++) {
ProducerRecord<String, String> record = new ProducerRecord<>("peter-basic01", "Apache Kafka is a distributed streaming platform - " + i); // (5)
producer.send(record); // (6)
}
} catch (Exception e) {
e.printStackTrace(); // (7)
} finally {
producer.close(); // (8)
}
}
}- Properties 객체 생성
- 브로커 리스트 정의
- 메시지 키와 밸류는 문자열 타입이므로 카프카의 기본 StringSerializer 지정
- Properties 객체를 전달해 새 프로듀서 생성
- ProducerRecord 객체 생성
- send() 메서드를 사용해 메시지를 전송한 후 자바 Future 객체로 RecordMetadata를 리턴 받지만, 리턴값을 무시하므로 메시지가 성공적으로 전송됐는지 알 수 없음
- 카프카 브로커에게 메시지를 전송한 후의 에러는 무시하지만, 전송 전에 에러가 발생하면 예외를 처리할 수 없음
- 프로듀서 종료
프로듀서에서 카프카의 토픽으로 메시지를 전송하고 난 후 성공적으로 도착했는지 확인하지 않는 예제이므로 실제 운영 환경에서는 추천 하지 않는다.
예제 2 - 동기 전송
public class ProducerSync {
public static void main(String[] args) {
Properties props = new Properties(); // (1)
props.put("bootstrap.servers", "peter-kafka01.foo.bar:9092,peter-kafka02.foo.bar:9092,peter-kafka03.foo.bar:9092"); // (2)
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); // (3)
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<>(props); // (4)
try {
for (int i = 0; i < 3; i++) {
ProducerRecord<String, String> record = new ProducerRecord<>("peter-basic01", "Apache Kafka is a distributed streaming platform - " + i); // (5)
RecordMetadata metadata = producer.send(record).get(); // (6)
System.out.printf("Topic: %s, Partition: %d, Offset: %d, Key: %s, Received Message: $s\n", metadata.topic(), metadata.partition(), metadata.offset(), record.key(), record.value());
}
} catch (Exception e) {
e.printStackTrace(); // (7)
} finally {
producer.close(); // (8)
}
}
}- Properties 객체 생성
- 브로커 리스트 정의
- 메시지 키와 밸류는 문자열 타입이므로 카프카의 기본 StringSerializer 지정
- Properties 객체를 전달해 새 프로듀서 생성
- ProducerRecord 객체 생성
- get () 메소드를 이용해 카프카의 응답을 기다리고 메시지가 성공적으로 전송되지 않으면 예외가 발생하고, 에러가 없다면 RecordMetadata를 얻음
- 카프카로 메시지를 보내기 전과 보내는 동안 에러가 발생하면 예외 발생
- 프로듀서 종료
동기 전송으로 프로듀서는 메시지를 보내고 send () 메소드의 Future 객체를 리턴하며, get () 메서드를 이용해 Future를 기다린 후 send ()가 성공했는지 실패했는지 확인한다.
예제 3 - 콜백
public class PeterProducerCallback implements Callback { // (1)
private ProducerRecord<String, String> record;
public PeterProducerCallback(ProducerRecord<String, String> record) {
this.record = record;
}
@Override
public void onCompletion(RecordMetadata metadata, Exception e) {
if (e != null) {
e.printStackTrace(); // (2)
} else {
System.out.printf("Topic: %s, Partition: %d, Offset: %d, Key: %s, Received Message: %s\n", metadata.topic(), metadata.partition(), metadata.offset(), record.key(), record.value());
}
}
}- 콜백을 사용하기 위해 org.apache.kafka.clients.producer.Callback 을 구현하는 클래스가 필요
- 카프카가 오류를 리턴하면 onCompletion()은 예외를 갖게 되며, 실제 운영 환경에서는 추가적인 예외 처리가 필요
예제 4 - 비동기 전송
public class ProducerAsync {
public static void main(String[] args) {
Properties props = new Properties(); // (1)
props.put("bootstrap.servers", "peter-kafka01.foo.bar:9092,peter-kafka02.foo.bar:9092,peter-kafka03.foo.bar:9092"); // (2)
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); // (3)
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafKaProducer<>(props); // (4)
try {
for (int i = 0; i < 3; i++) {
ProducerRecord<String, String> record = new ProducerRecord<>("peter-basic01", "Apache Kafka is a distributed streaming platform - " + i); // (5)
producer.send(record, new PeterProducerCallback(record)); // (6)
}
} catch (Exception e) {
e.printStackTrace();
} finally {
producer.close(); // (7)
}
}
}- Properties 객체 생성
- 브로커 리스트 정의
- 메시지 키와 밸류는 문자열 타입이므로 카프카의 기본 StringSerializer 지정
- Properties 객체를 전달해 새 프로듀서 생성
- ProducerRecord 객체 생성
- 프로듀서에서 레코드를 보낼 때 콜백 객체를 같이 보냄
- 프로듀서 종료
비동기 전송 예제, 프로듀서는 send () 메서드와 콜백을 함께 호출하게 된다. 동기 전송과 같이 프로듀서가 보낸 모든 메시지에 대해 응답을 기다리면 많은 시간을 소비하게 되므로 빠른 전송을 할 수 없다. 하지만 이처럼 비동기 방식으로 전송하면 빠른 전송이 가능하고 메시지 전송이 실패한 경우라도 예외를 처리할 수 있어서 이후 에러 로그 등에 기록할 수 있다.
컨슈머의 기본 동작과 예제
컨슈머는 카프카의 토픽에 저장되어 있는 메시지를 가져오는 역할을 하는데 내부적으로는 컨슈머 그룹, 리밸런싱 등 여러 동작을 수행한다.
프로듀서가 아무리 빠르게 카프카로 메시지를 전송하더라도컨슈머가 카프카로부터 빠르게 메시지를 읽어오지 못한다면 결국 지연이 발생한다.
컨슈머의 기본 동작
프로듀서가 카프카의 토픽으로 메시지를 전송하면 해당 메시지들은 브로커들의 로컬 디스크에 저장되고 우리는 컨슈머를 이용해 토픽에 저장된 메시지를 가져올 수 있다.
컨슈머 그룹은 하나 이상의 컨슈머들이 모여 있는 그룹을 의미하고 컨슈머는 반드시 컨슈머 그룹에 속하게 된다. 이 컨슈머 그룹은 각 파티션의 리더에게 카프카 토픽에 저장된 메시지를 가져오기 위한 요청을 보낸다.
(일반적으로 파티션 수보다 컨슈머 수가 많게 구현하는 것은 바람직한 구성이 아니다. 컨슈머 수가 파티션 수보다 많다해서 빠르게 토픽의 메시지를 가져오거나 처리량이 높아지는 것이 아니라 더 많은 수의 컨슈머들이 그냥 대기 상태로 존재하기 때문)
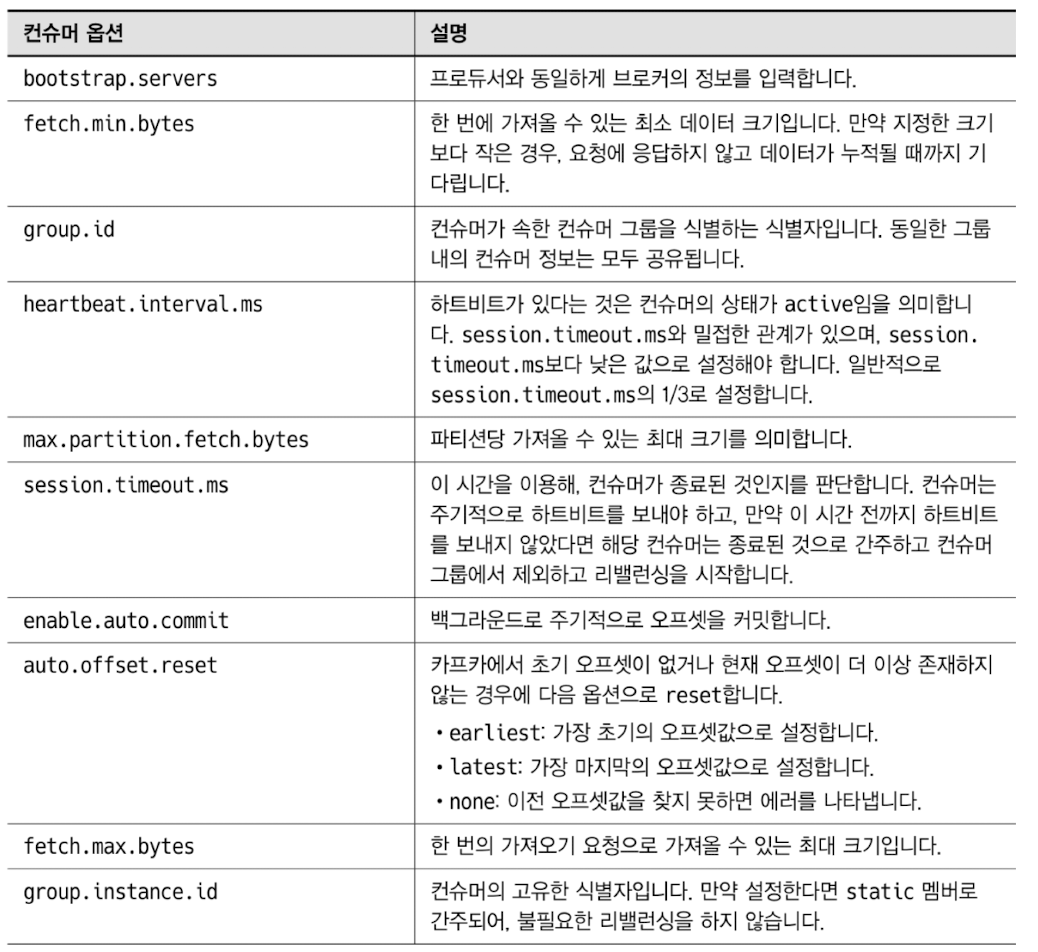
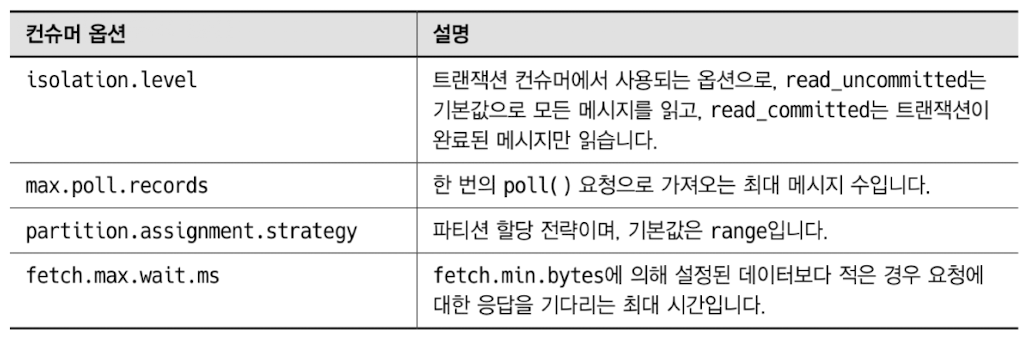
컨슈머의 주요 옵션
카프카에 메시지가 잘 저장되어 있어도 관리자가 컨슈머를 어떻게 처리하고 다루느냐에 따라 컨슈머 동작에서 메시지의 중복, 유실, 등 여러가지 상황이 발생할 수 있다.
컨슈머를 사용하는 목적이 최대한 안정적이며 지연이 없도록 카프카로부터 메시지를 가져오는 것인데, 이를 위한 옵션을 잘 이해하고 사용해야 자신이 원하는 형태로 컨슈머가 동작된다.
컨슈머 예제
컨슈머도 메시지를 가져오는 방법은 크게 세자기 방식이 있다. 오토 커밋, 동기 가져오기, 비동기 가져오기
예제 1 - 오토 커밋
public class ConsumerAuto {
public static void main(String[] args) {
Properties props = new Properties(); // (1)
props.put("bootstrap.servers", "peter-kafka01.foo.bar:9092,peter-kafka02.foo.bar:9092,peter-kafka03.foo.bar:9092"); // (2)
props.put("group.id", "peter-consumer01"); // (3)
props.put("enable.auto.commit", "true"); // (4)
props.put("auto.offset.reset", "latest"); // (5)
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); // (6)
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props); // (7)
consumer.subscribe(Arrays.asList("peter-basic01")); // (8)
try {
while (true) { // (9)
ConsumerRecord<String, String> records = consumer.poll(1000); // (10)
for(ConsumerRecord<String, String> record : records) { // (11)
System.out.printf("Topic: %s, Partition: %s, Offset: %d, Key: %s, Value: %s\n", record.topic(), record.partition(), record.offset(), record.key(), record.value());
}
}
} catch (Exception e) {
e.printStackTrace();
} finally {
consumer.close(); // (12)
}
}
}- Properties 객체 생성
- 브로커 리스트 정의
- 컨슈머 그룹 아이디 정의
- 오토 커밋을 사용하지 않음
- 컨슈머 오프셋을 찾지 못하는 경우 latest로 초기화하며 가장 최근부터 메시지를 가져옴
- 문자열을 사용했으므로 StringDeserializer 지정
- Properties 객체를 전달해 새 컨슈머 생성
- 구독할 토픽을 지정
- 무한 루프 시작. 메시지를 가져오기 위해 카프카에 지속적으로 poll() 사용
- 컨슈머는 폴링하는 것을 유지하며, 타임아웃 주기를 설정, 해당 시간만큼 블록함
- poll()은 레코드 전체를 리턴하고, 하나의 메시지만 가져오는 것이 아니므로 반복문 처리
- 컨슈머 종료
컨슈머 애플리케이션들의 기본값으로 가장 많이 사용되고 있는 오토 커밋, 오프셋을 주기적으로 커밋하므로 관리자가 오프셋을 따로 관리하지 않아도 된다는 장점과 컨슈머 종료 등이 빈번히 일어나면 일부 메시지를 못 가져오거나 중복으로 가져오는 단점도 있다.
예제 2 - 동기 가져오기
public class ConsumerSync {
public static void main(String[] args) {
Properties props = new Properties(); // (1)
props.put("bootstrap.servers", "peter-kafka01.foo.bar:9092,peter-kafka02.foo.bar:9092,peter-kafka03.foo.bar:9092"); // (2)
props.put("group.id", "peter-consumer01"); // (3)
props.put("enable.auto.commit", "false"); // (4)
props.put("auto.offset.reset", "latest"); // (5)
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); // (6)
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props); // (7)
consumer.subscribe(Arrays.asList("peter-basic01")); // (8)
try {
while (true) { // (9)
ConsumerRecord<String, String> records = consumer.poll(1000); // (10)
for (ConsumerRecord<String, String> record : records) { // (11)
System.out.printf("Topic: %s, Partition: %s, Offset: %d, Key: %s, Value: %s\n", record.topic(), record.partition(), record.offset(), record.key(), record.value());
}
consumer.commitSync(); // (12)
}
} catch (Exception e) {
e.printStackTrace();
} finally {
consumer.close(); // (13)
}
}
}- Properties 객체 생성
- 브로커 리스트 정의
- 컨슈머 그룹 아이디 정의
- 오토 커밋을 사용하지 않음
- 컨슈머 오프셋을 찾지 못하는 경우 latest로 초기화하며 가장 최근부터 메시지를 가져옴
- 문자열을 사용했으므로 StringDeserializer 지정
- Properties 객체를 전달해 새 컨슈머 생성
- 구독할 토픽을 지정
- 무한 루프 시작. 메시지를 가져오기 위해 카프카에 지속적으로 poll() 사용
- 컨슈머는 폴링하는 것을 유지하며, 타임아웃 주기를 설정, 해당 시간만큼 블록함
- poll()은 레코드 전체를 리턴하고, 하나의 메시지만 가져오는 것이 아니므로 반복문 처리
- 현재 배치를 통해 읽은 모든 메시지를 처리한 후, 추가 메시지를 폴링하기 전 현재의 오프셋을 동기 커밋
- 컨슈머 종료
오토 커밋과 달리 poll() 을 이용해 메시지를 가져온 후 처리까지 완료하고 현재의 오프셋을 커밋한다. 동기 방식으로 가져오면 속도는 느리지만 메시지 손실은 거의 발생하지 않는다. 여기서 메시지 손실은 실제로 토픽에는 메시지가 존재하지만 잘못된 오프셋 커밋으로 인한 위치 변경으로 컨슈머가 메시지를 가져오지 못하는 경우를 말함
동기 방식도 메시지의 중복 이슈는 피할 수 없다.
예제 3 - 비동기 가져오기
public class ConsumerAsync {
public static void main(String[] args) {
Properties props = new Properties(); // (1)
props.put("bootstrap.servers", "peter-kafka01.foo.bar:9092,peter-kafka02.foo.bar:9092,peter-kafka03.foo.bar:9092"); // (2)
props.put("group.id", "peter-consumer01"); // (3)
props.put("enable.auto.commit", "false"); // (4)
props.put("auto.offset.reset", "latest"); // (5)
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); // (6)
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props); // (7)
consumer.subscribe(Arrays.asList("peter-basic01")); // (8)
try {
while (true) { // (9)
ConsumerRecord<String, String> records = consumer.poll(1000); // (10)
for (ConsumerRecord<String, String> record : records) { // (11)
System.out.printf("Topic: %s, Partition: %s, Offset: %d, Key: %s, Value: %s\n", record.topic(), record.partition(), record.offset(), record.key(), record.value());
}
consumer.commitAsync(); // (12)
}
} catch (Exception e) {
e.printStackTrace();
} finally {
consumer.close(); // (13)
}
}
}- Properties 객체 생성
- 브로커 리스트 정의
- 컨슈머 그룹 아이디 정의
- 오토 커밋을 사용하지 않음
- 컨슈머 오프셋을 찾지 못하는 경우 latest로 초기화하며 가장 최근부터 메시지를 가져옴
- 문자열을 사용했으므로 StringDeserializer 지정
- Properties 객체를 전달해 새 컨슈머 생성
- 구독할 토픽을 지정
- 무한 루프 시작. 메시지를 가져오기 위해 카프카에 지속적으로 poll() 사용
- 컨슈머는 폴링하는 것을 유지하며, 타임아웃 주기를 설정, 해당 시간만큼 블록함
- poll()은 레코드 전체를 리턴하고, 하나의 메시지만 가져오는 것이 아니므로 반복문 처리
- 현재 배치를 통해 읽은 모든 메시지를 처리한 후, 추가 메시지를 폴링하기 전 현재의 오프셋을 비동기 커밋
- 컨슈머 종료
동기 가져오기와 차이점은 consumer.commitAsync() 이다. commitSync()와 달리 오프셋 커밋을 실패하더라도 재시도하지 않는다.
비동기 방식이고 예를들어 총 10개의 메시지가 있고 오프셋 1부터 10까지 순차적으로 커밋한다고 가정한다.
1. 1번 오프셋의 메시지를 읽은 뒤 1번 오프셋을 비동기 커밋한다. (현재 마지막 오프셋 1)
2. 2번 오프셋의 메시지를 읽은 뒤 2번 오프셋을 비동기 커밋하지만 실패 (현재 마지막 오프셋 1)
3. 3번 오프셋의 메시지를 읽은 뒤 3번 오프셋을 비동기 커밋하지만 실패 (현재 마지막 오프셋 1)
4. 4번 오프셋의 메시지를 읽은 뒤 4번 오프셋을 비동기 커밋하지만 실패 (현재 마지막 오프셋 1)
5. 5번 오프셋의 메시지를 읽은 뒤 5번 오프셋을 비동기 커밋한다. (현재 마지막 오프셋 5)
현재 5번 오프셋의 메시지를 읽었고 5번 오프셋의 비동기 커밋을 성공해 현재 마지막 오프셋은 5이다. 하지만 여기서 만약 2번 오프셋의 비동기 커밋이 성공하게 되면 마지막 오프셋이 2로 변경될 것이다. 따라서 만약 현재 컨슈머가 종료되고 다른 컨슈머가 이어서 작업한다면 다시 3번 오프셋부터 메시지를 가져오게 되니 메시지 중복이 엄청 발생 할 수 있게된다.
컨슈머 그룹의 이해
하나의 컨슈머 그룹 안에 여러 개의 컨슈머가 구성될 수 있다.
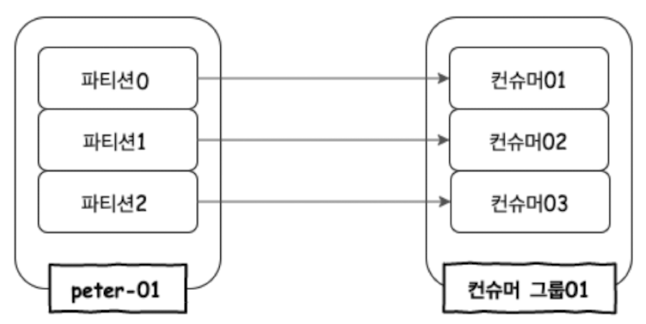
만약 컨슈머01이 문제가 생겨 종료되면 컨슈머02, 컨슈머03이 컨슈머01이 하던 일을 대신하여 peter-01 토픽의 파티션0을 컨슘하기 시작한다.

댓글