1.1 인터넷이란 무엇인가? (what is Internet?)

- Host ( 인터넷의 최종적인 외곽에 달려있는 컴퓨터) = end system (인터넷을 통해 데이터를 송수신 및 서비스 등 역할) = node ( 네트워크 안에 있는 장비)
- 통신 링크 ( 유선과 무선 형태로 데이터를 전송)
- 대역폭 ( 전송할 수 있는 데이터의 크기, 속도 등 기준이 되는 것)
- 패킷 교환 (동일한 데이터를 잘라서 전달)
- 라우터 ( 고성능 컴퓨터로 패킷의 경로를 결정)
- 프로토콜: 통신을 하기 위해서 개체 간의 서로가 약속한 규약의 집합체
1.2 네트워크의 가장자리 (network edge)
- 종단 시스템, 접속 네트워크, 링크
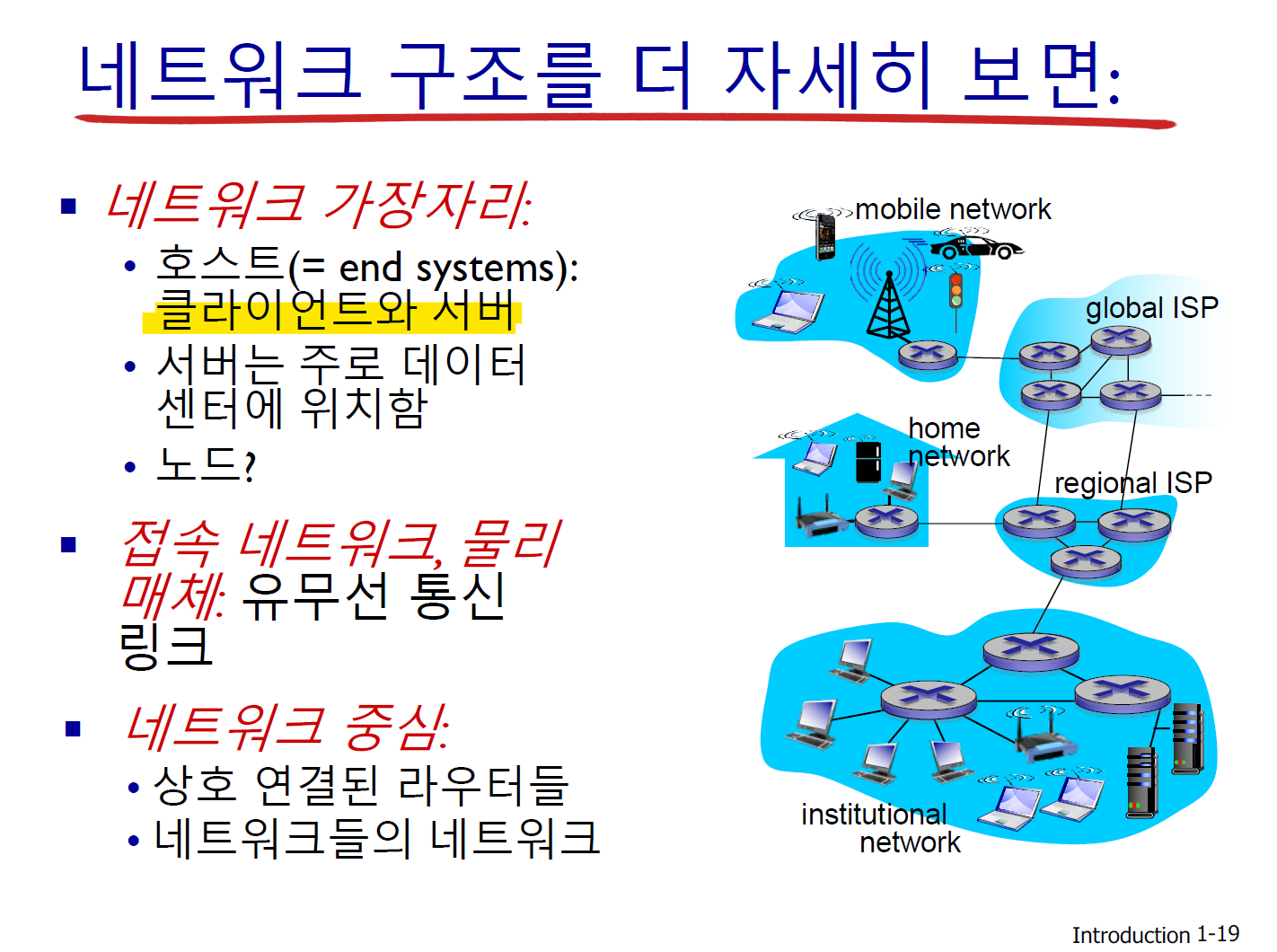
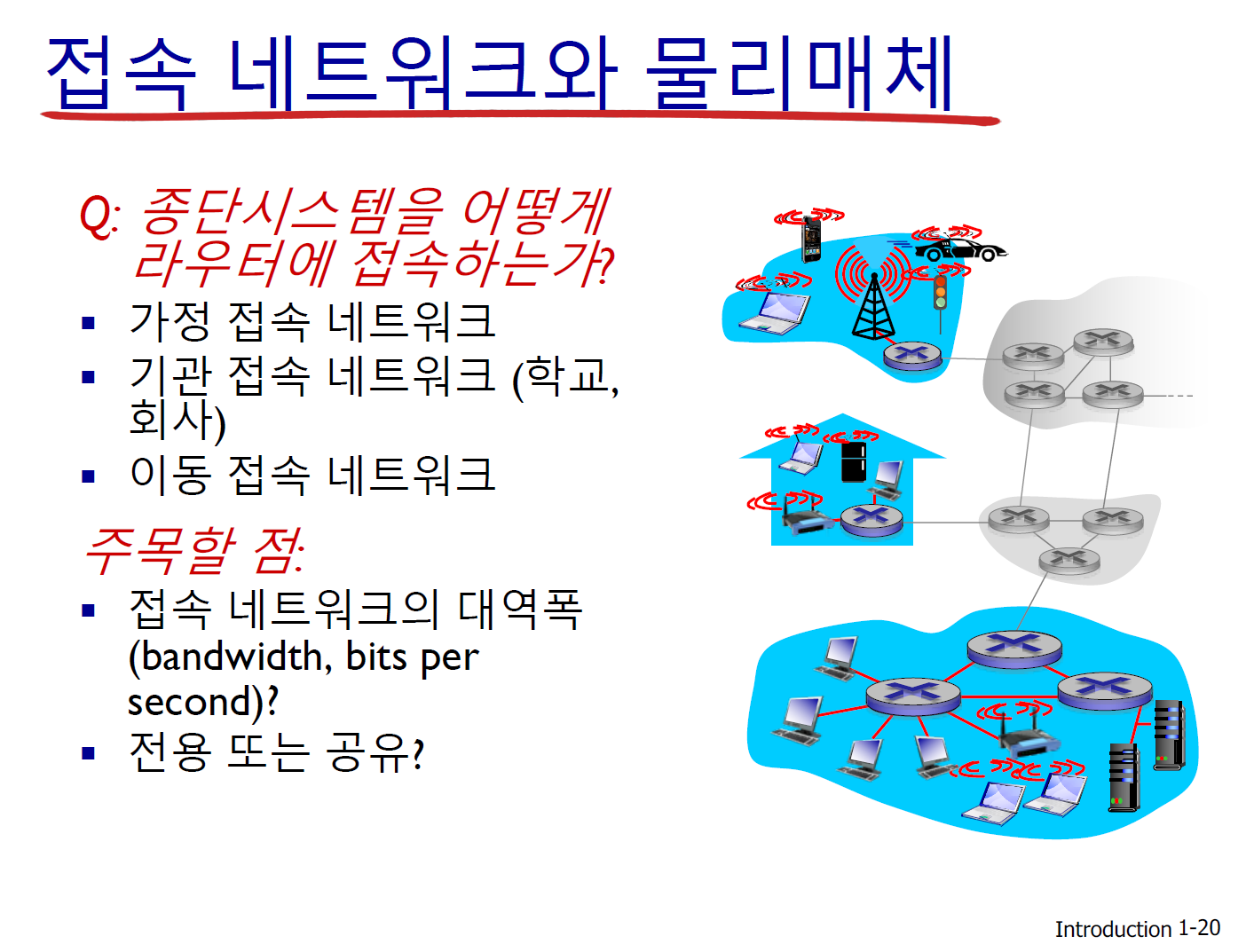
- 접속 네트워크
접속망이라고 생각하면 된다. end system과 다른 end system을 사이의 경로상에 있는 첫 번째 라우터(edge router)에 연결하는 네트워크를 access network라고 한다. 즉, access network는 end system이 네트워크에 연결되기 위해 제공되는 네트워크라고 할 수 있다.
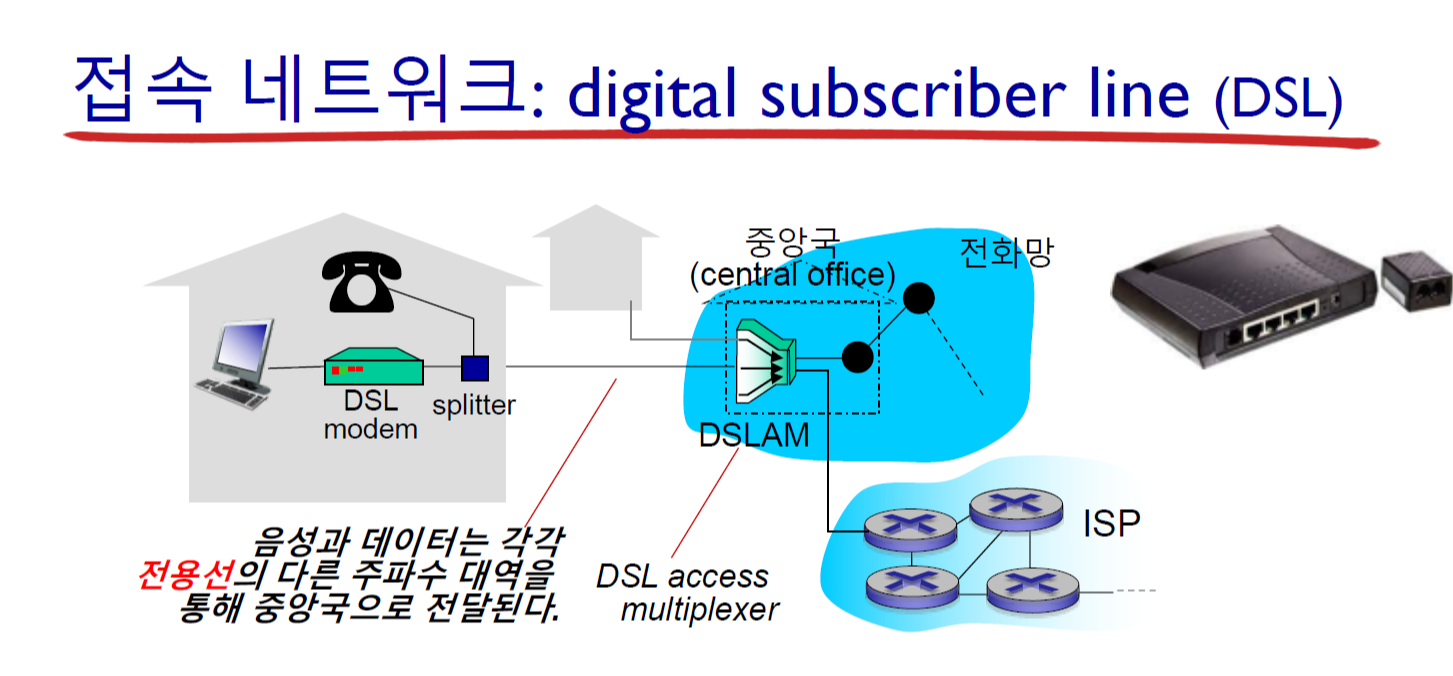


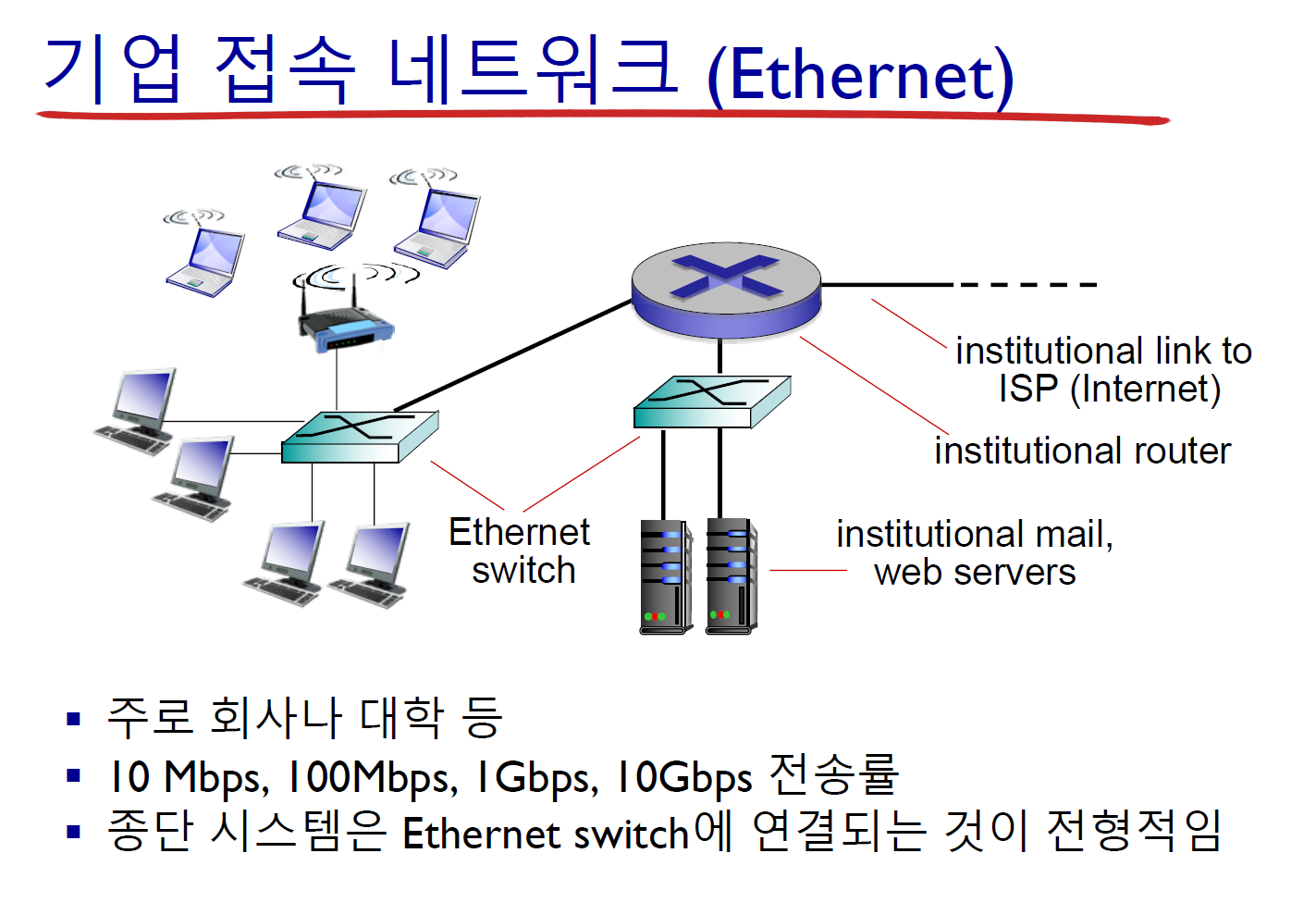
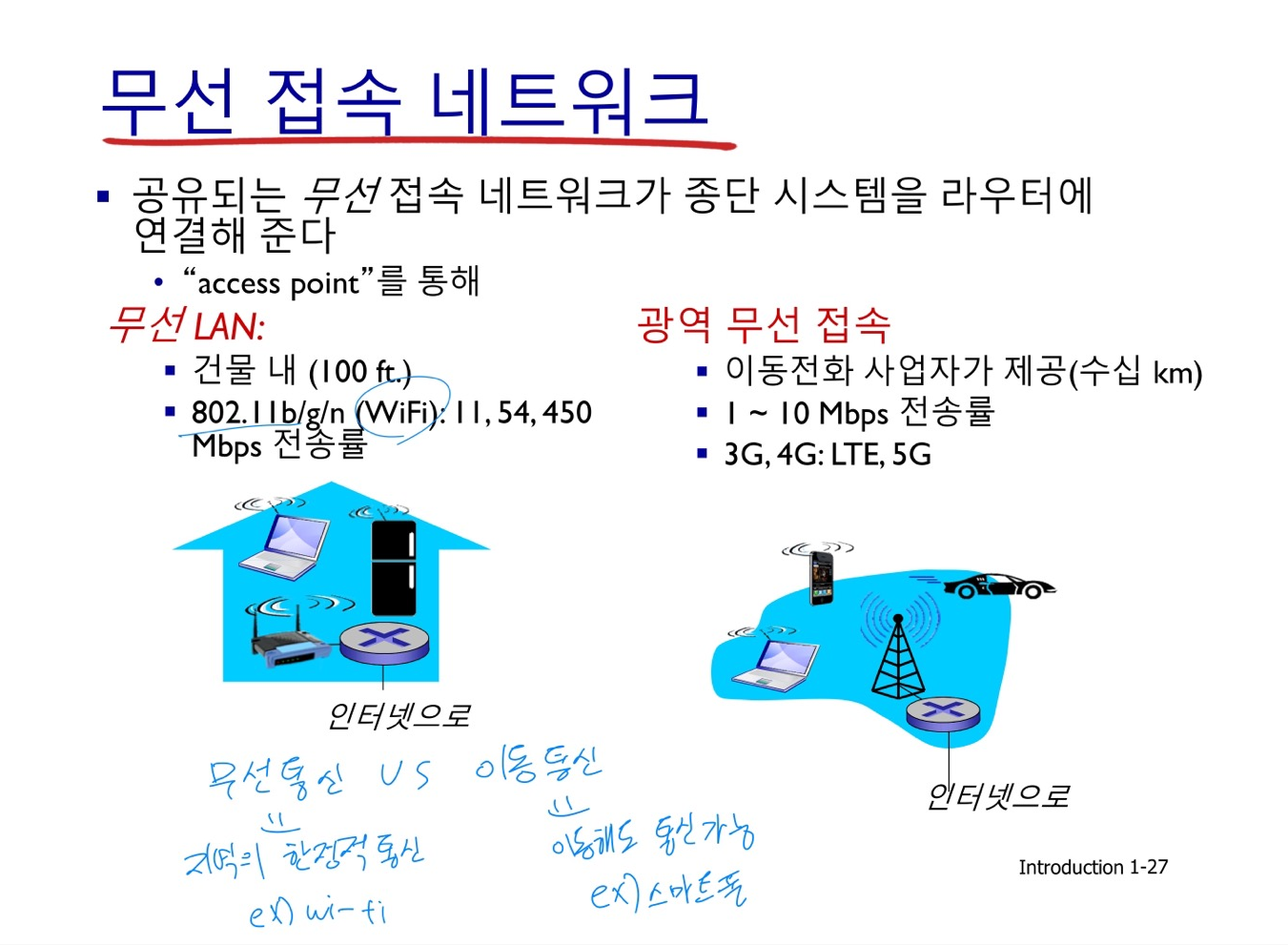
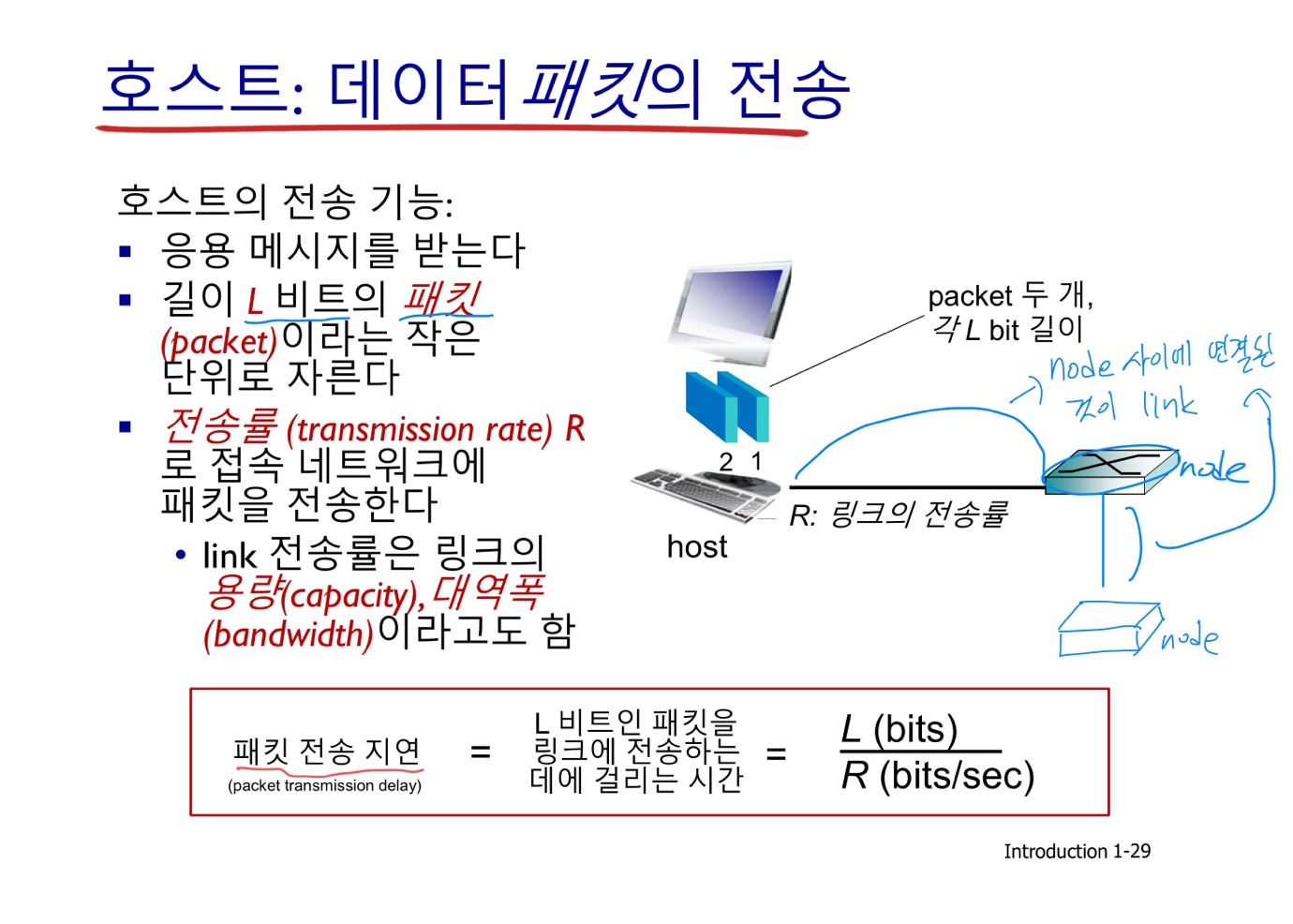

1.3 네트워크 코어 (network core)
- 패킷 교환, 회선 교환, 네트워크 구조
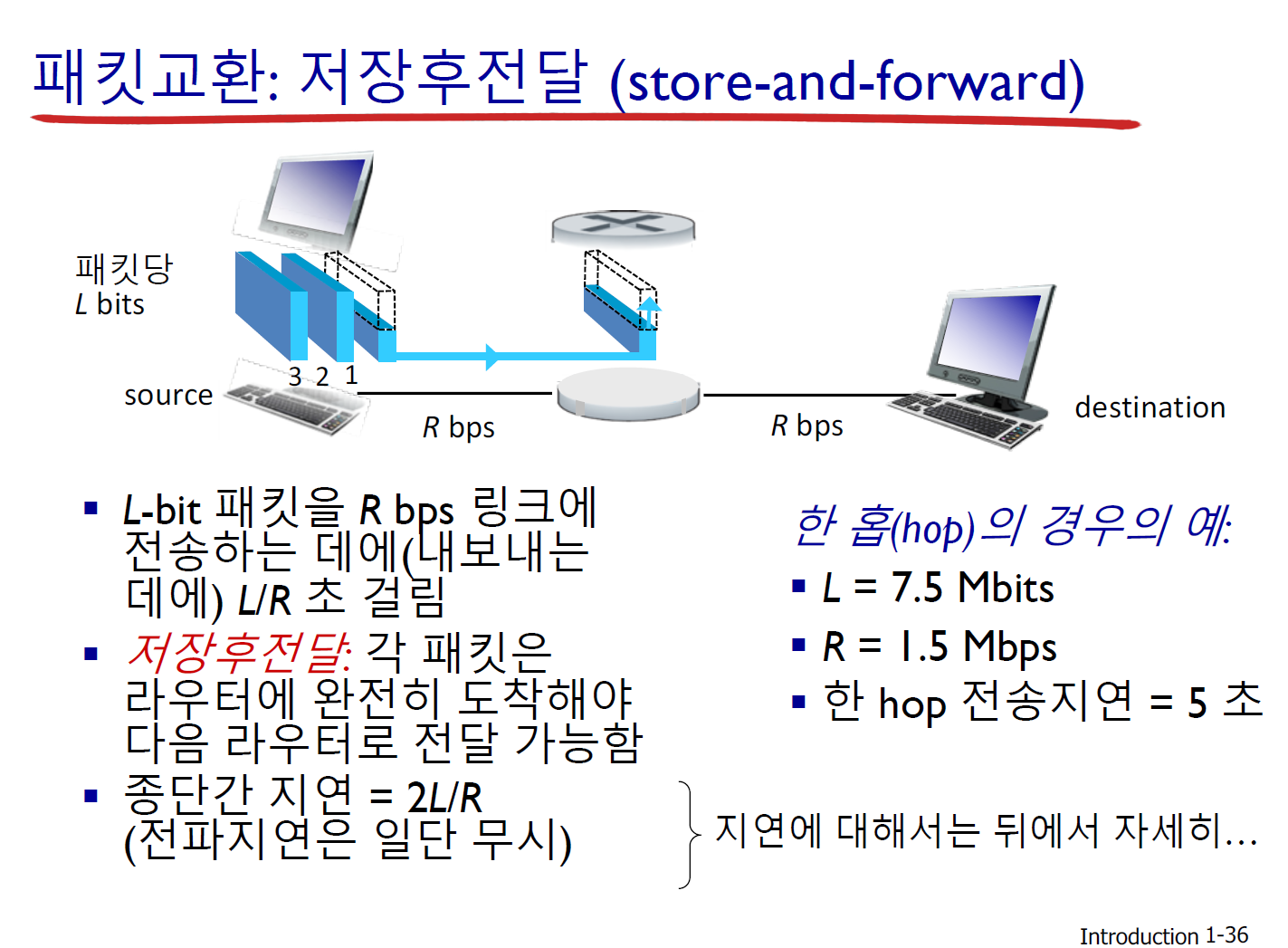
- 패킷교환 (packet-switching): 패킷단위로 switching 하는 것이다. 패킷단위로 어디로 갈지 길을 정해주는 것이다.
여기에서 중요한 원칙은 Store and forward이다.
라우터가 패킷 하나를 받아서 잠깐 저장(store) 후, 어디로 보낼지 판단하고 보내는 것(forward)이다. 이 과정에서 시간이 걸리는데 이것을 지연시간(delay time)이라고 한다.
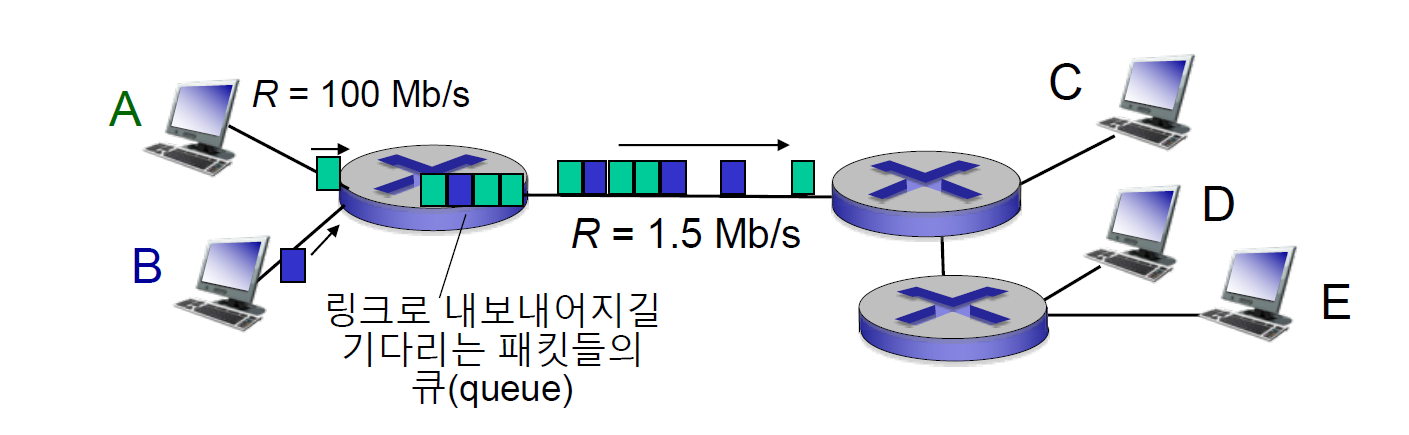
위와 같이 여러 사용자가 link를 공유하고 있는 상황에서, 들어가는 길은 100Mb/s로 넓은데 나가는 길이 1.5Mb/s로 좁다면, 전송이 느려지게 된다.
단위시간 동안 나갈 수 있는 데이터보다 들어오는 데이터가 많게 되어, 결과적으로 queue에서 대기상태로 기다리게 된다. 여기서 실제 라우터의 메모리는 유한대이므로 메모리가 다 차면 패킷이 버려지게 된다.
즉, 메모리에 자리가 있으면 보내지고 없으면 버려진다.
- Forwarding, Routing
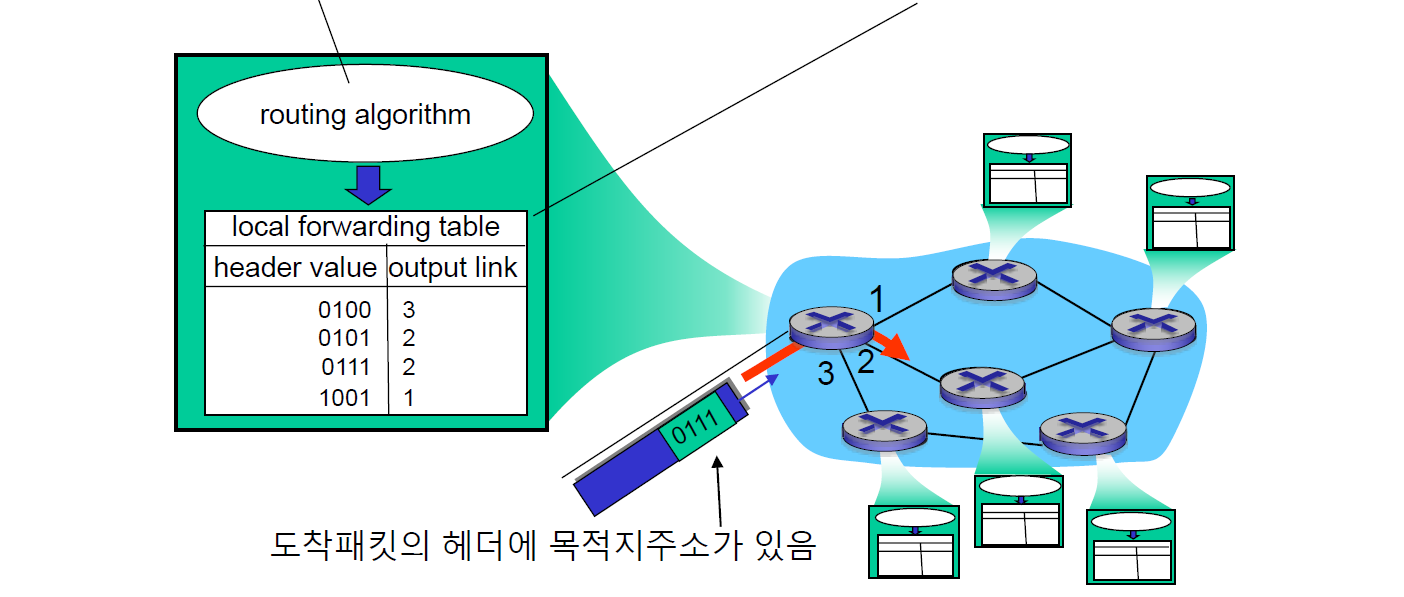
- Forwarding
라우터는 데이터의 목적지 주소를 보고 어디로 보내야 할지 판단해야 한다. 판단해서 보내는 기능을 Forwarding이라고 한다. 그렇다면 무얼 보고 판단할까? 바로 local forwarding table을 보고 판단한다.
- Routing
local forwarding table은 라우터들끼리 만들어야 한다.데이터가 발생하기 전에 라우터들끼리 미리 정보를 주고받는다. 그래서 라우터들끼리 누가 존재하고 누가 연결되어 있고 어디로 보낸 게 가장 합리적인지 미리 결정(routing algorithm)한다. 그리고 이것을 forwarding table로 만든다. 이후 패킷이 오면 forwarding table에 근거하여 내보내는 일을 진행할 수 있다.
정리하자면
1. 라우터에 들어오는 패킷의 header에는 목적지 주소가 있다.
2. 이 주소에 대한 경로 정보를 미리 정하는 routing algorithm에 의해 각 라우터에 local forwarding table이 만들어진다.
3. 이후 라우터에 패킷이 왔을 때, 패킷의 목적지 주소와 table의 header value를 보고 해당하는 output link로 보낸다.
- Forwarding : 패킷이 왔을 때 실제 전달하는 기능
- Routing : 경로를 만들기 위해서 라우터들끼리 협력하는 것
- 회선교환 (circuit switching): source와 destination 사이의 경로를 정해버리는 것이다. 즉, 경로를 미리 설정하는 것
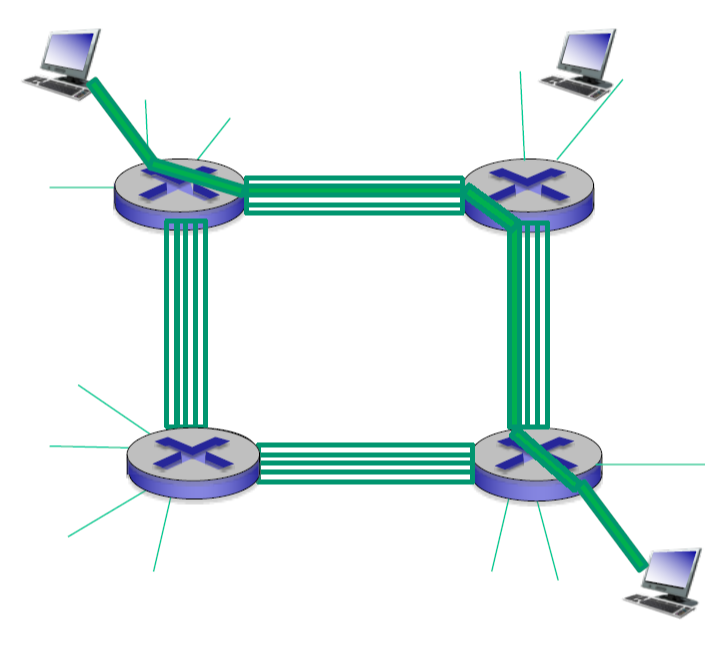
- 회선 교환 (circuit-switching)의 특징
- 공유하지 않아 독립적이다.
- 경로를 미리 지정한다.
- delay와 loss가 완화된다. (라우터에 도착하는 패킷은 미리 지정된 경로로 빠르게 전송되기 때문에)
- Bandwidth이 고정되어 사용자의 수가 정해져 있다.
- 회선 교환 (circuit-switching)을 구현하는 방법에는 두 가지가 있다.
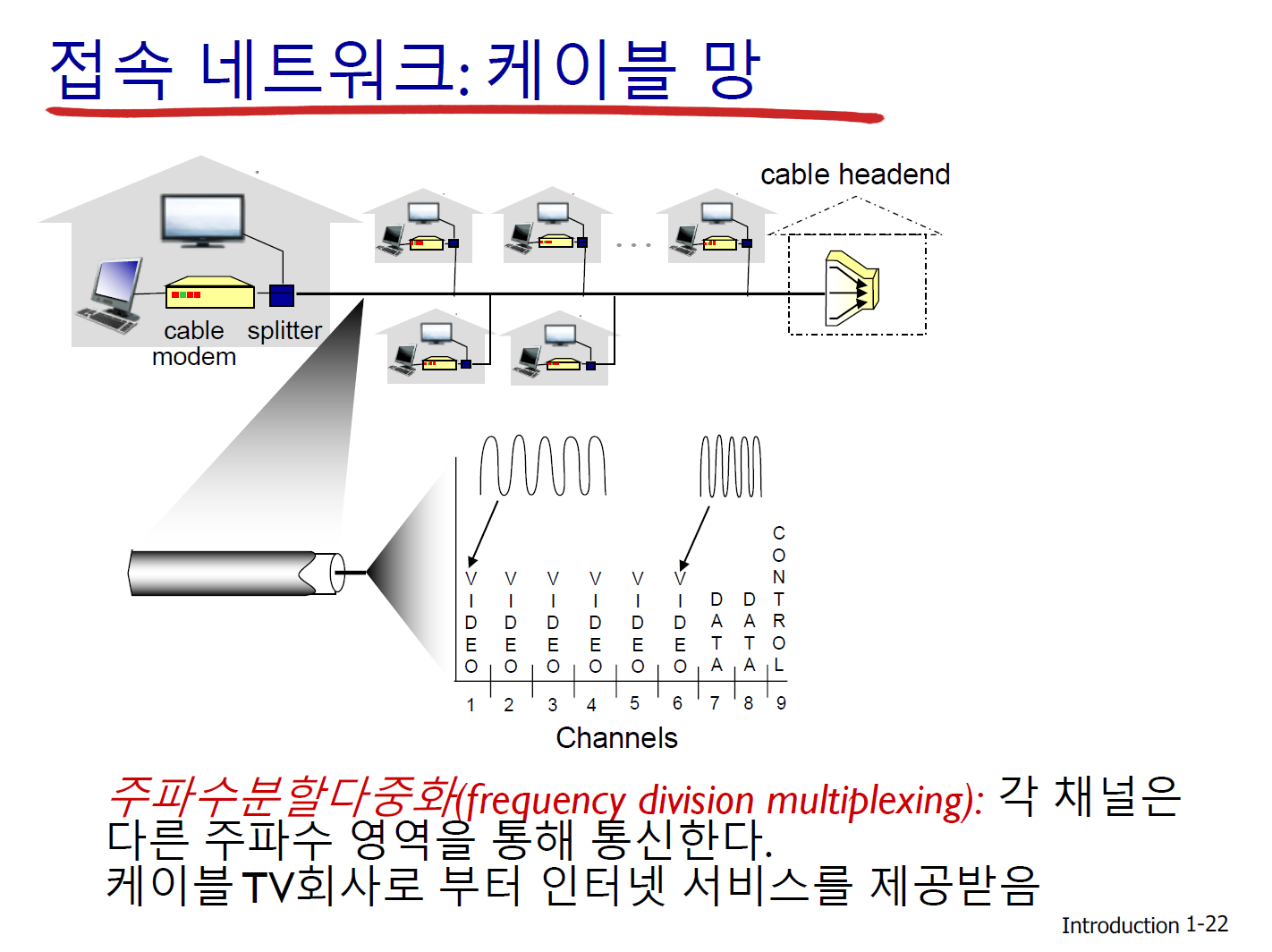
1. FDM (frequency division multiplexing) : 주파수 단위로 쪼개는 것
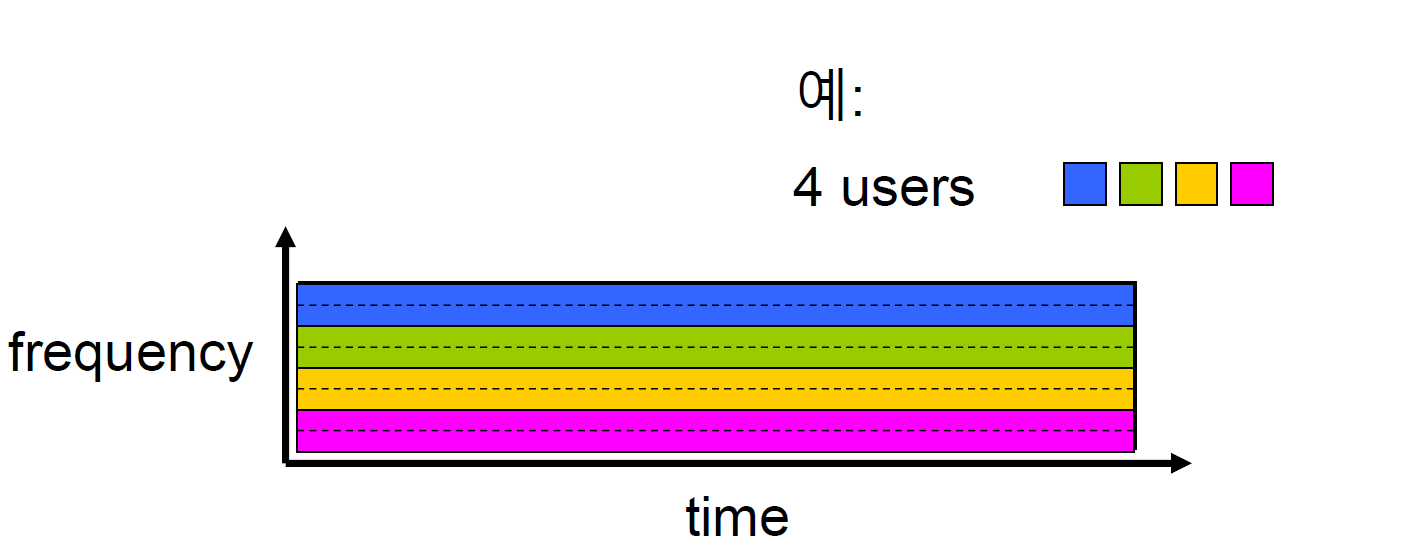
어떤 데이터를 보내는 주파수를 사용자에게 미리 정하는 것. 각 사용자가 특정 주파수로 보낼 것을 정한다. 주파수를 쪼개서 하나씩 주파수 자원을 나눠주는 것이다. 만약 4명의 사용자가 정해졌다면, 5번째 사용자는 못 듣 는 것이다. 파란색 사용자는 파란 주파 수를 사용해서 전화를 건다.
2. TDM (time division multiplexing) : 시간 단위로 쪼개는 것
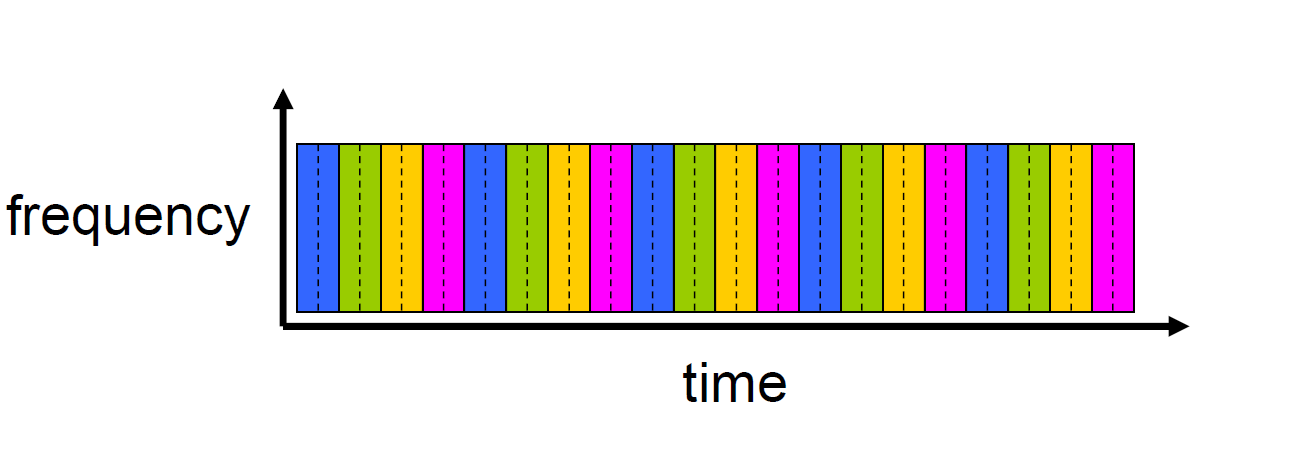
시간에 따라, 매 주기마다 사용자들이 데이터를 보내는 것. 4명의 사용자에게 시간을 다 할당해서, 5번째 사용자가 낄 공간이 없다. 아날로그 방식에서는 불가능하다.
- 회선 교환 (circuit-switching)의 단점
전화통화할 때, 나 또는 상대방이 쉴 틈 없이 얘기한다면(계속해서 데이터를 보낸다면) circuit-switching을 좋게 활용하는 것이다. 경로가 보장되어 있고 그 경로를 다 활용하는 것이다.
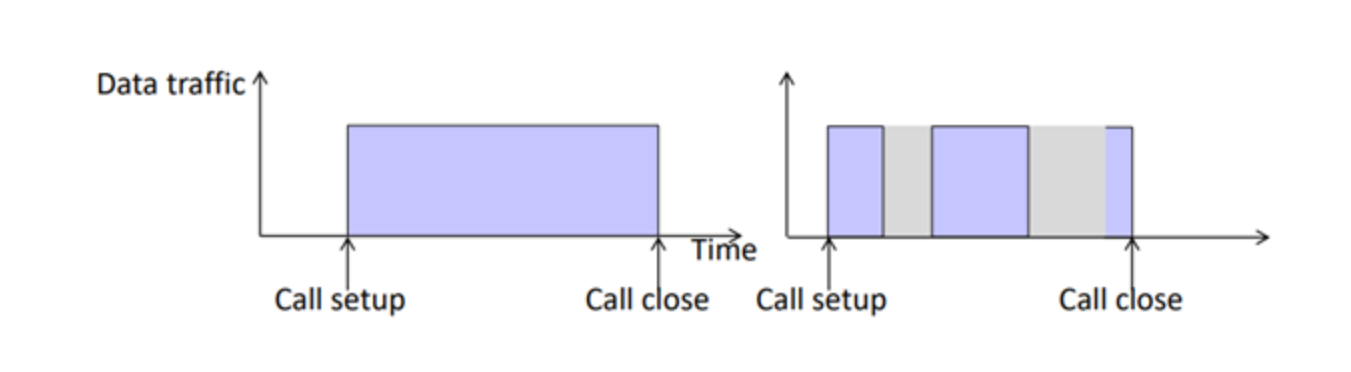
하지만 전화통화 중에 소리를 내지 않으면 , 중간에 데이터를 보내지 않는 순간이 있다. (웹페이지 볼 때 페이지 킨 후(데이터 사용), 보기만 하는 경우(데이터 사용 X)도 비슷) 이것은 자원을 낭비하는 것이다.
위 그림에서 왼쪽은 다 활용, 오른쪽은 회색시간 동안 자원낭비이다. 즉, 데이터를 보내지 않는 순간은 자원을 낭비한다는 단점이 있다.
- 패킷 교환 vs 회선교환
- 패킷 교환이 더 나은 점
Circuit-switching는 계속해서 데이터를 주고받아야 하는데, 데이터를 주고받지 못하는 경우가 생긴다면 이것은 낭비이다. Packet-switching는 이러한 낭비를 줄여준다. 주고받는 데이터를 패킷단위로 자르고 그 패킷들을 섞어서 보냄으로써 데이터가 전달되는 길을 효율적으로 이용하는 것이다.
1. link의 낭비가 줄어든다.
패킷을 link를 공유하고 있는 다른 사용자들의 데이터들과 섞여서 전송되기 때문에 계속해서 link를 계속해서 활용할 수 있어서, link가 사용되지 않는 경우를 줄일 수 있다.
2. 더 많은 사용자가 사용 가능하다. (중요)
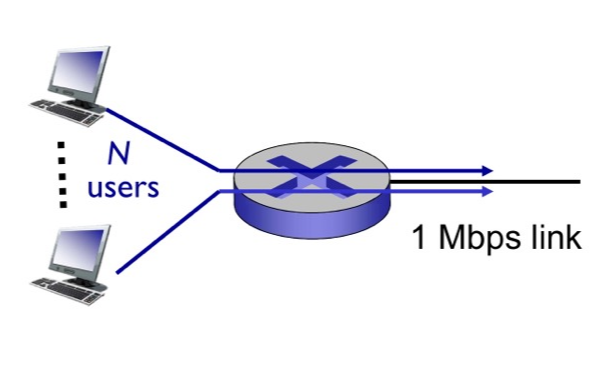
1Mb/s link
Each user:
- 100 kb/s when "active"
- active 10% of time
다음과 같이 N명의 사용자가 있고 라우터는 하나 있어서, N명의 사용자를 하나의 라우터로 전송해야 하는 상황이다. 링크의 capacity(용량)은 1 Mbps이고 각 사용자는 활성화했을 때 초당 100kb를 전달해야 한다고 가정해 보자.
회선 교환과 패킷 교환 중에 어느 방식이 더 나을까? 그것은 누구의 관점이냐에 따라 나뉜다. 인터넷 서비스를 제공하는 사업자 입장이라면 패킷 교환 방식이 더 낫다.왜 그럴까?
회선교환 의 경우
회선 교환 방식은 한 사용자가 회선을 할당받으면 그 사용자가 회선을 사용하고 있지 않더라도 다른 사용자에게 회선을 할당할 수 없다. 실제 사용자가 링크를 클릭하고 검색어를 검색하는 시간을 전체 시간의 10% 밖에 되지 않는다고 하면나머지 90%의 시간은 그저 낭비되는 것이다. 결국은 한 사람당100kb를 사용가능하니 10명의 사용자만 사용할 수 있다.
하지만 패킷교환의 경우
우선 수용 인원을 10명 넘게 할당할 수 있다. 그런데 이 경우 링크 capacity 1 Mbps를 넘어가기 때문에 통신 속도가 느려지는 결과를 낳을 수 있다. 통신 속도가 느려진다고 해도 그 순간이 잦을까?
만약 35명의 사용자가 접속해 있다고 가정해 보자. 인터넷을 사용하는데 각각의 사람들은 전체 사용 시간의 10%만 데이터를 주고받는데 회선망을 사용한다. 그 상황에서 10명보다 더 많은 사람들이 동시다발적으로 회선망을 사용하는 확률이 얼마나 될지 따져보자. 이항 분포를 가지고 0명에서 10명까지의 사용자만 회선망을 사용하는 경우를 빼보면 그 이상, 11명에서 35명까지 회선망을 사용할 확률이 나온다. 밑의 그림에서 계산을 해보면 백분율로 약 0.004%가 나온다.

회선 교환 방식을 사용했을 때의 3.5배나 많은 사용자를 수용하더라도 패킷 교환 방식에서 사용자들이 불편을 느낄 확률은 고작 0.004% 밖에 되지 않는 것이다. 따라서 서비스 제공자 입장에서는 패킷 교환 방식이 효율적으로 느껴진다.
- 회선교환이 더 나은 점
Circuit-switching는 경로를 지정하여 일정한 전송률을 보장받는다. 그래서 전화통화 같은 품질보장이 되어야 하고 계속해서 데이터를 주고받아야 하는 서비스에선, 가변적인 Packet-switching보다 일정한 Circuit-switching를 이용하는 것이 좋다.
1. queueing delay가 완화된다.
패킷 교환 방식은 지연 시간을 겪을 우려가 있다. 예를 들어 여러 사용자들이 보낸 패킷들이 섞여 있다 보니까 이것이 전체 transmission rate를 넘어가는 경우에 지연 시간이 발생할 수 있다. 사용자가 보내는 패킷들은 중간에 라우터에 도착하게 되는데, 라우터는 패킷에 담겨 있는 주소를 보고 패킷을 어디로 보낼지 결정해야 한다. 그동안 queue에 잠깐 저장되는데 여기서 잠깐 지연 시간이 발생한다. queue의 크기가 무한하지 않기 때문에 중간에 라우터가 저장할 수 있는 용량을 넘어서는 대용량의 데이터들이 몰려들면 지연 시간으로 인해 초과하는 패킷들은 그냥 버려지는 수가 있다. 이것을 패킷 손실이라고 한다. => 정보량을 조절하여 혼잡현상을 방지, 제거하는 혼잡제어(congestion control)를 위한 프로토콜 필요하다.
하지만 회선교환은 미리 경로를 설정하기 때문에 지연 시간이 완화된다.
2. 장시간 긴 데이터를 보낼 때
패킷 교환 방식은 여러 자원들에서 데이터가 패킷으로 쪼개져 날아가기 때문에, 장시간 긴 데이터를 보낸다면 많은 패킷을 보내므로, 데이터 전송이 지연되거나 전송을 완전히 보장받을 수 없다. 회선 교환 방식은 자원을 독점하여 사용하기 때문에 패킷보다 신뢰 있는 전송을 보장받을 수 있다.
3. 제한된 시간에 빠르게 보낼 때
위와 같은 이유로, 패킷 같은 일정한 전송을 보장받지 못하는 상황에서, 시간을 제한한다면 신뢰 있는 전송을 보장받지 못할 것이다.
4. 독립적이다.
회선 교환 방식은 다른 사용자와 공유하지 않아 독립적이다. (장점? 단점?)
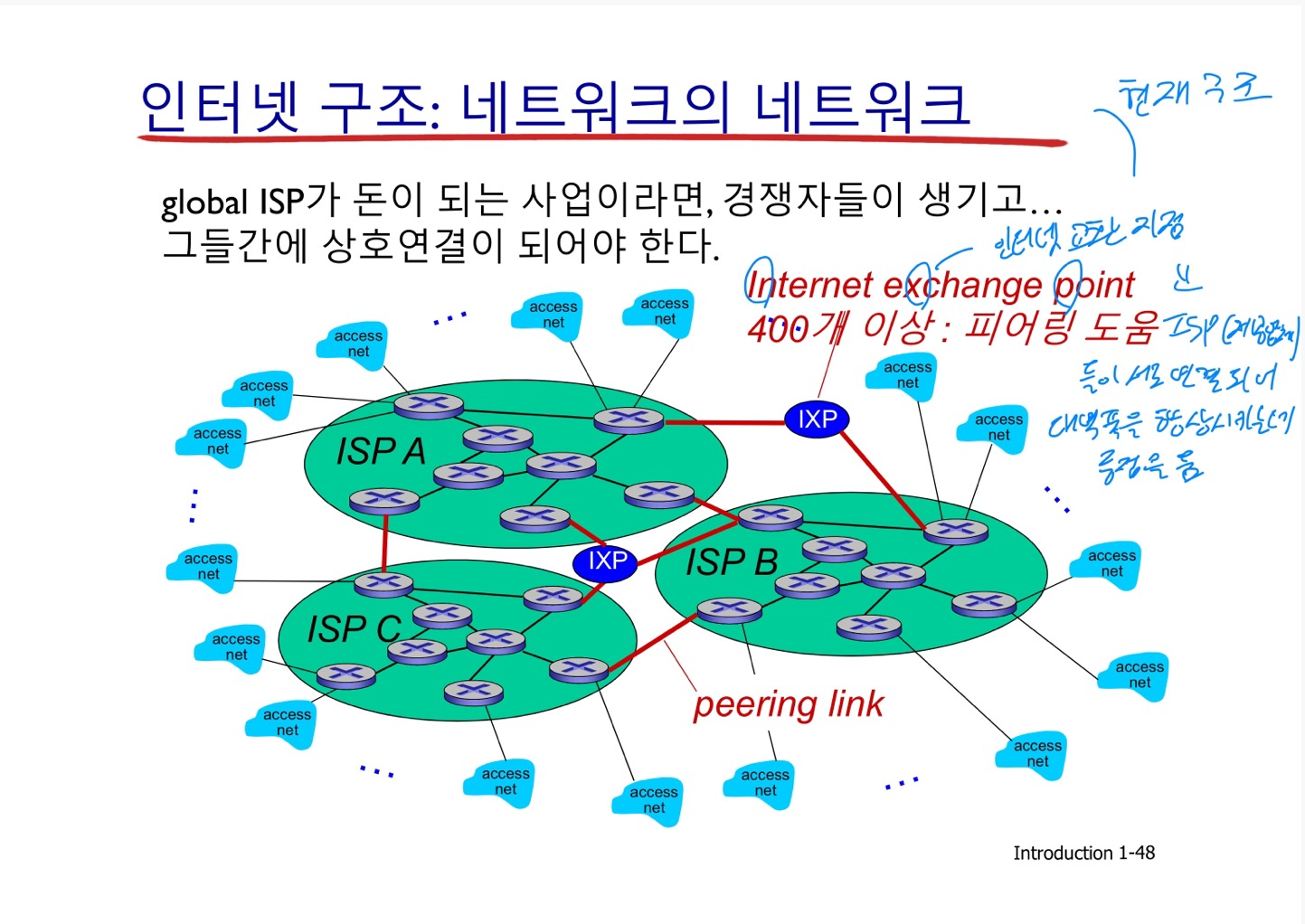
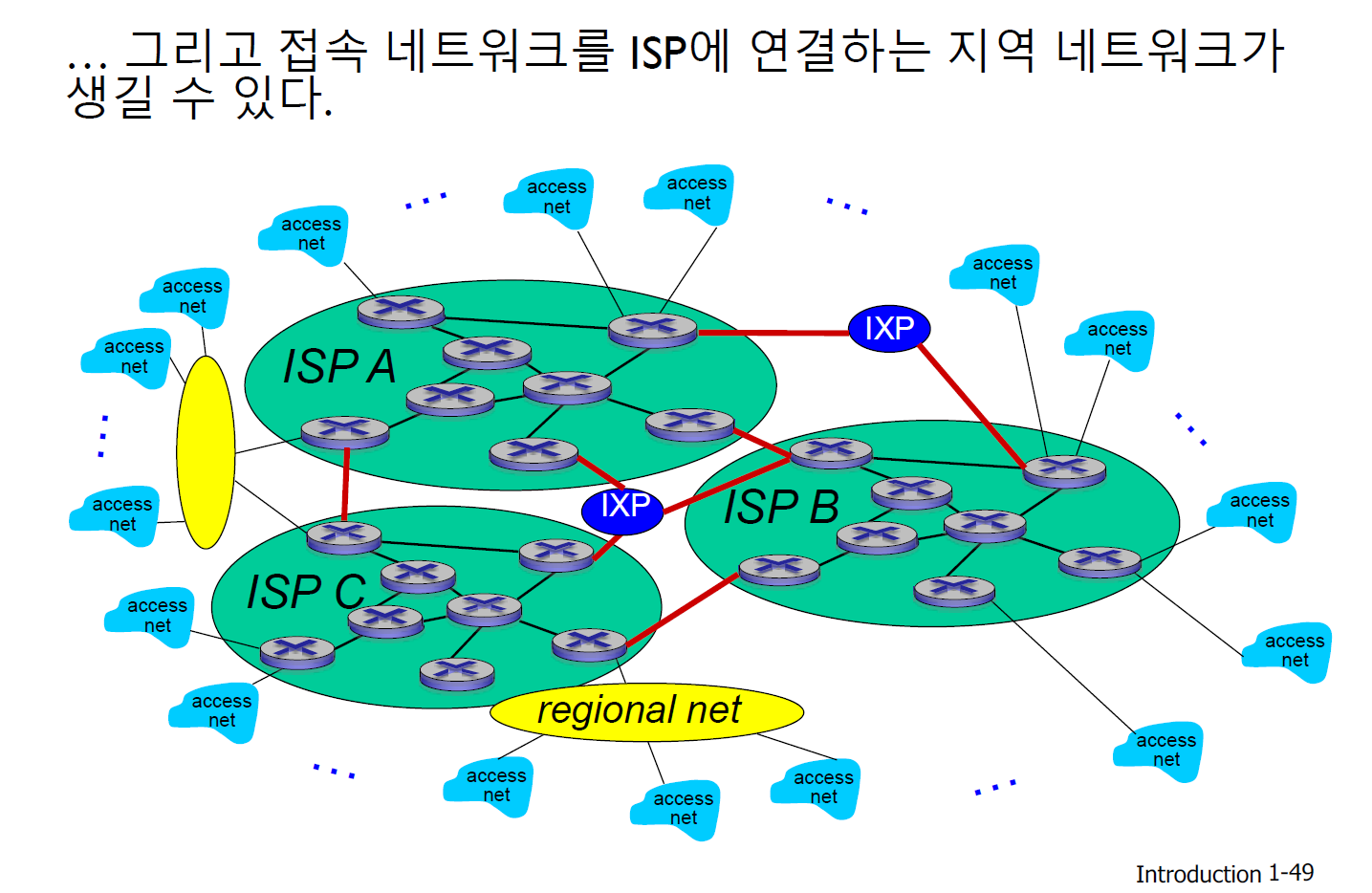
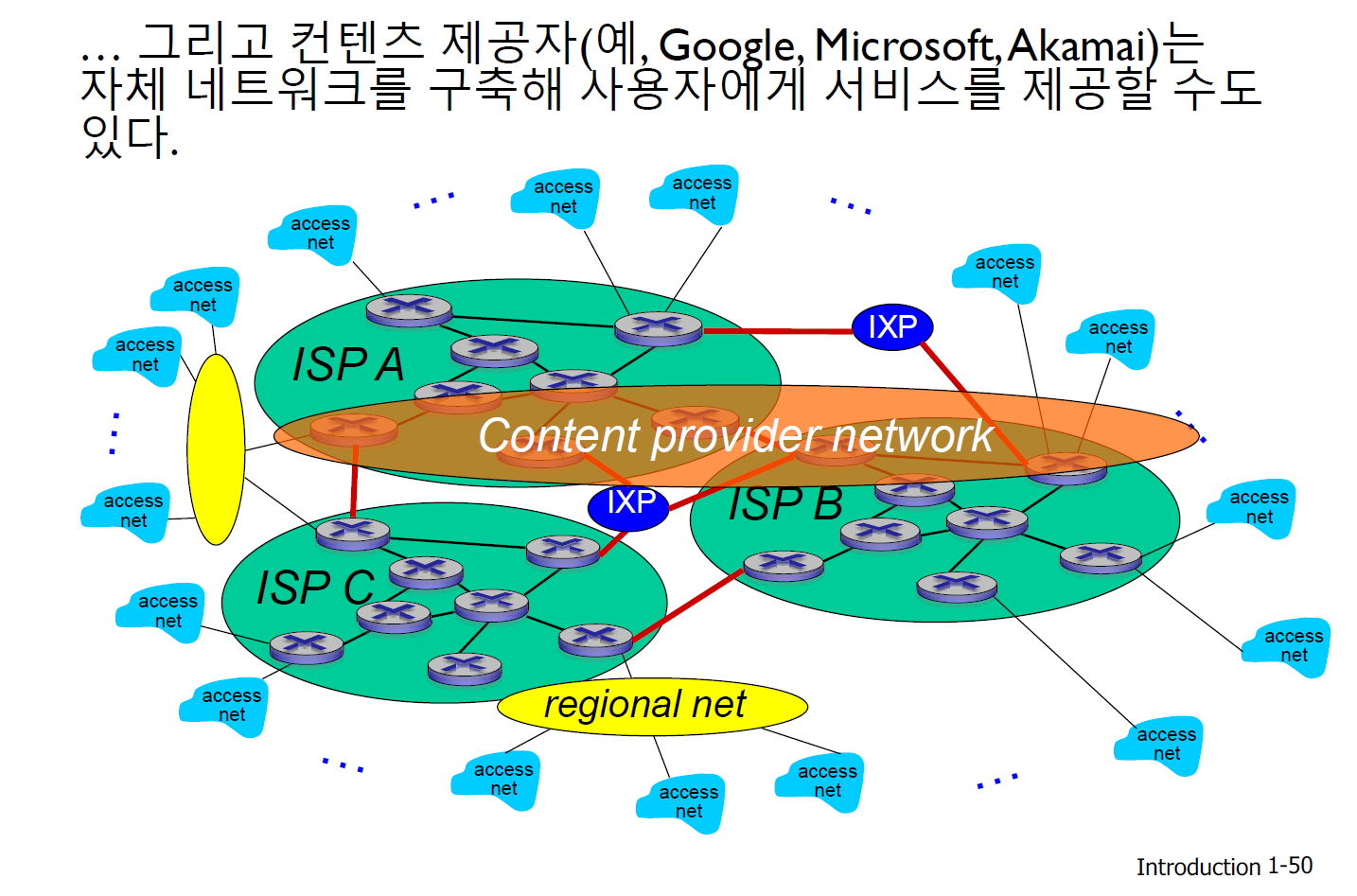
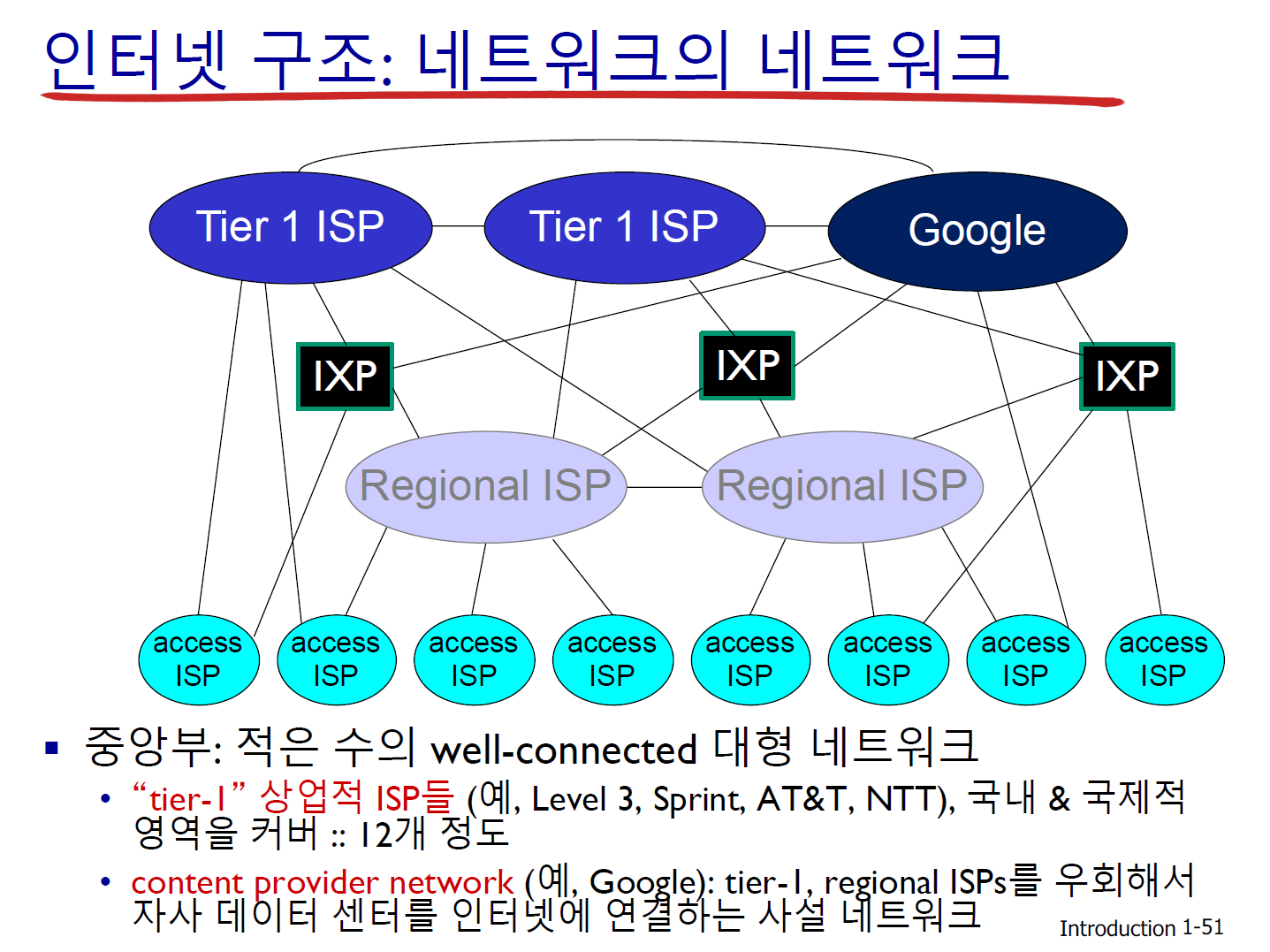
- 인터넷 구조

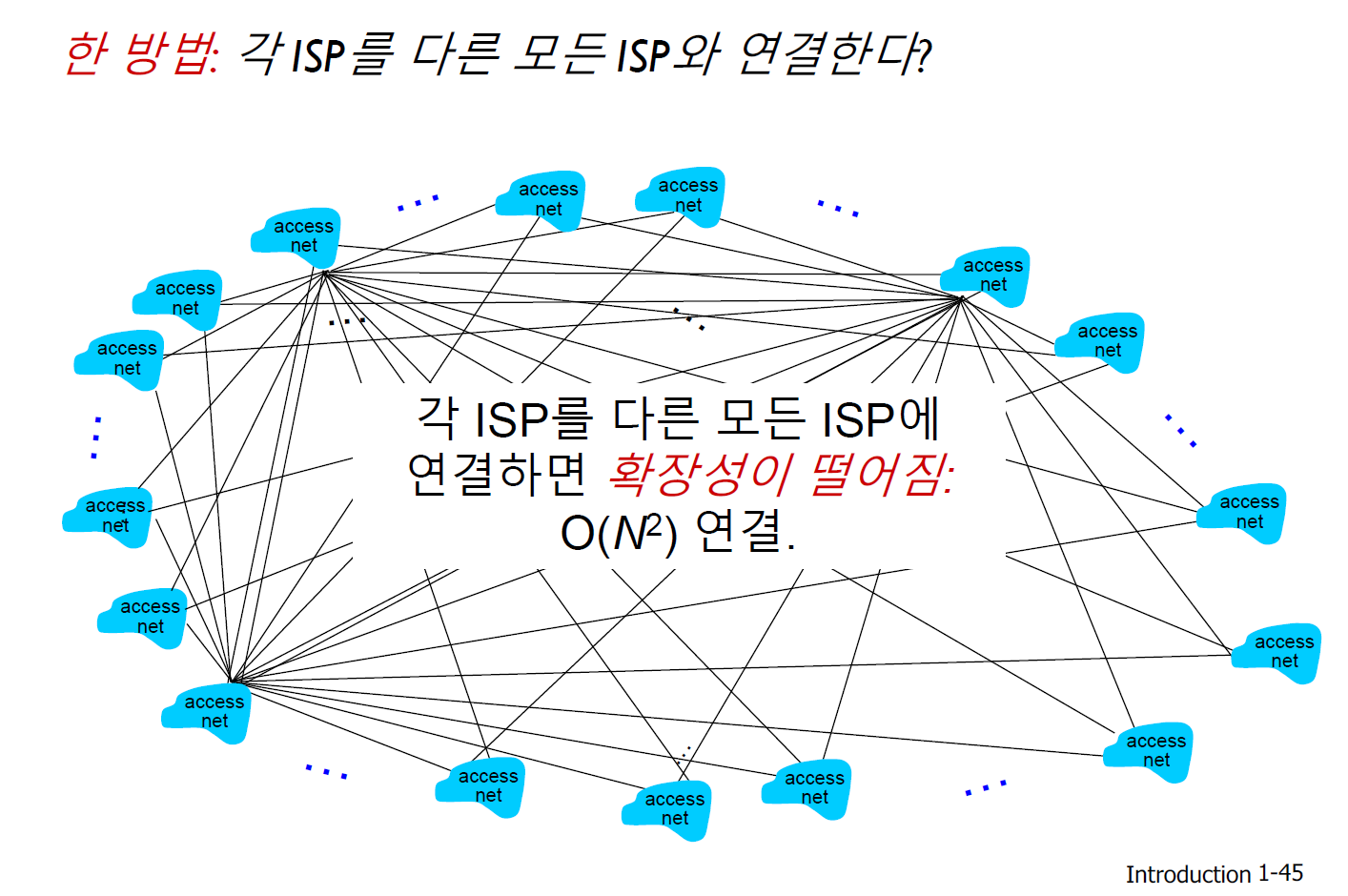
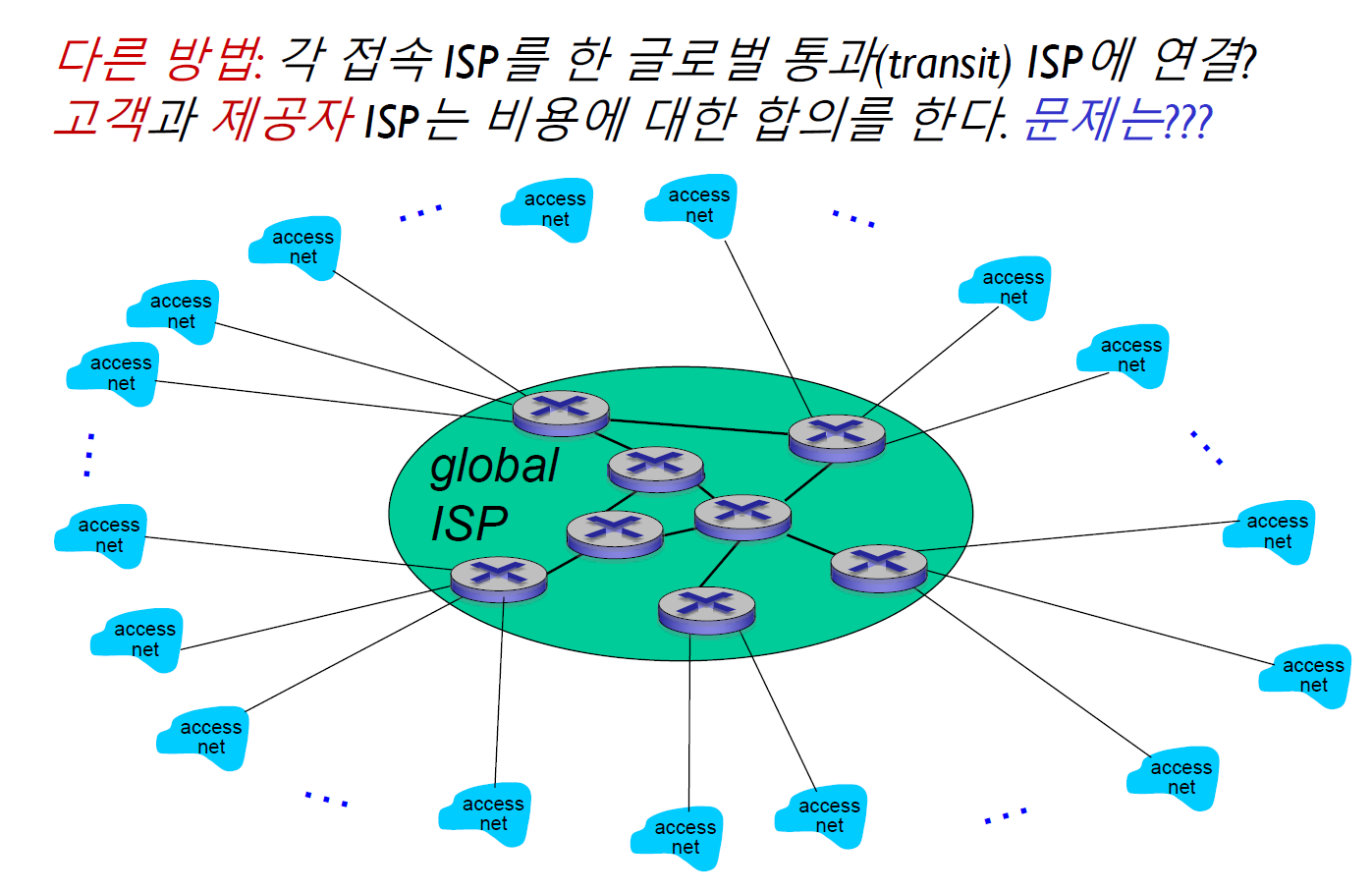
Q. 수백만 개의 접속 ISP가 있다면, 어떻게 연결할까?
1.4 네트워크에서의 지연, 손실, 처리율 (delay, loss, throughput in networks)
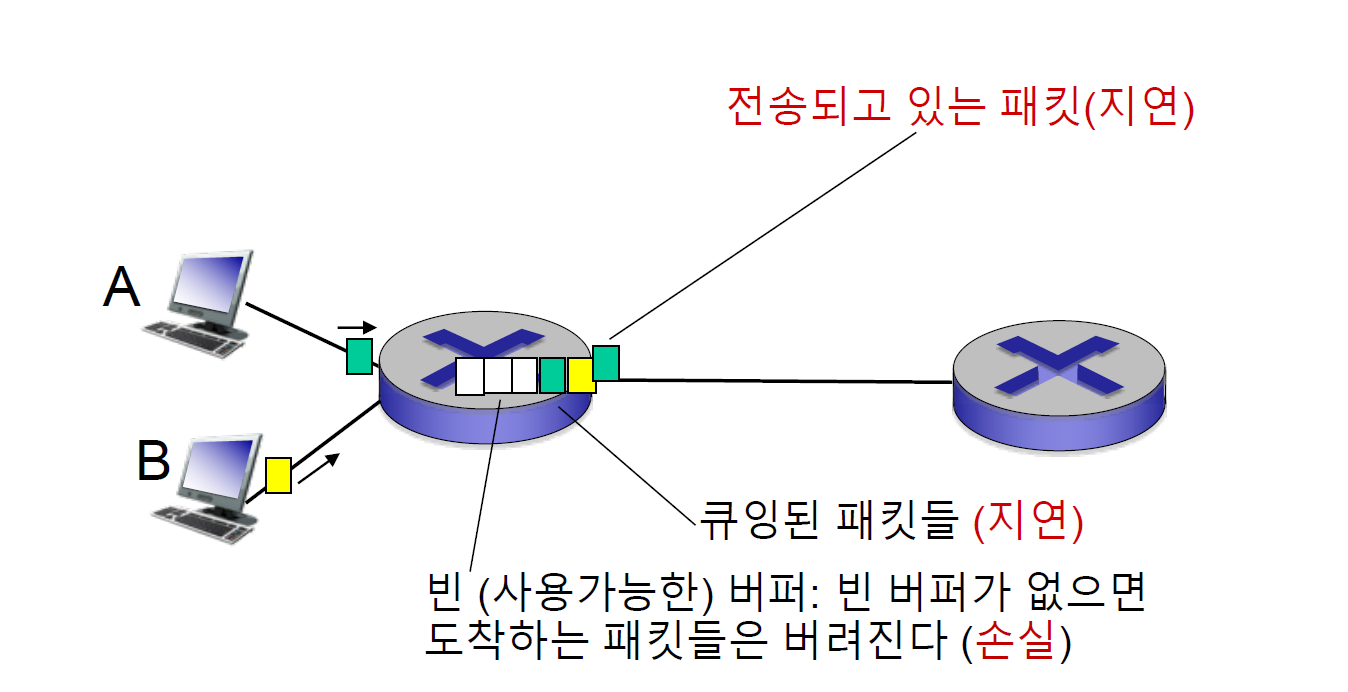
단위시간 동안 도착하는 패킷의 수가 output link의 capacity를 넘어설 때 라우터의 queue에 패킷이 대기상태로 쌓이게 되어, delay가 발생하게 된다. 이것을 queueing delay라고 한다. 만약 queue가 가득 차서 더 이상 패킷을 받을 공간이 없다면? 패킷은 버려지게 된다. loss(손실) 된다.
- delay
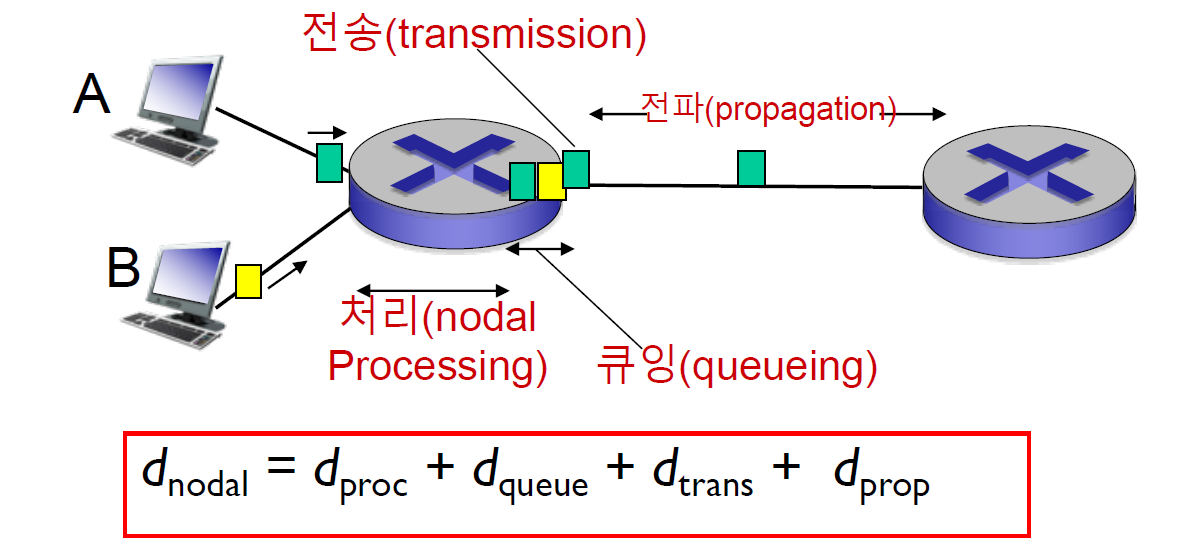
1. nodal processing (d nodal)
bit error를 체크하는 시간.
output link를 결정하는 데 걸리는 시간. (routing algorithm이 돌아가는 시간)
2. queueing delay (d queue)
queue에서 패킷이 대기상태로 쌓여 나갈 때까지 기다리는 시간
3. transmission delay (d trans)
데이터가 전송되는 데 걸리는 시간.
L/R
4. propagation delay (d prop)
물리적인 선을 따라 신호가 가는데 걸리는 시간
d/s (d: length of physical link (물리 링크의 길이) , s: propagation speed (전파속도) (~2x10^8 m/sec)
이 네 가지 delay 중 가장 가변적인 것은?? (가장 예측하기 힘든 것은??)
- transmission delay : 이미 결정되어 있는 프로토콜. 어떤 식으로 신호를 변환할지 결정되어 있다. 패킷의 길이에 따라 달라지겠지만 어떤 IP에 따라 패킷의 크기가 고정되어 있기에 값이 크게 달라지지 않는다.
- propagation delay : 라우터들의 물리적인 거리를 바꾸지 않는 이상 바뀌지 않음. 거리 대비 커진다. 클 수도 있지만 고정된 값이기 때문에 예측하기 쉽다.
- nodal processing : nodal processing은 CPU. 노드에 따라 달라지지만 워낙 작은 값이라 크게 신경 안 써도 된다.
- queueing delay는 혼자 데이터를 보내는 것이 아니라 수많은 end systems이 언제 어디로 보낼지 예측 불가능하다. 가장 가변적이다.
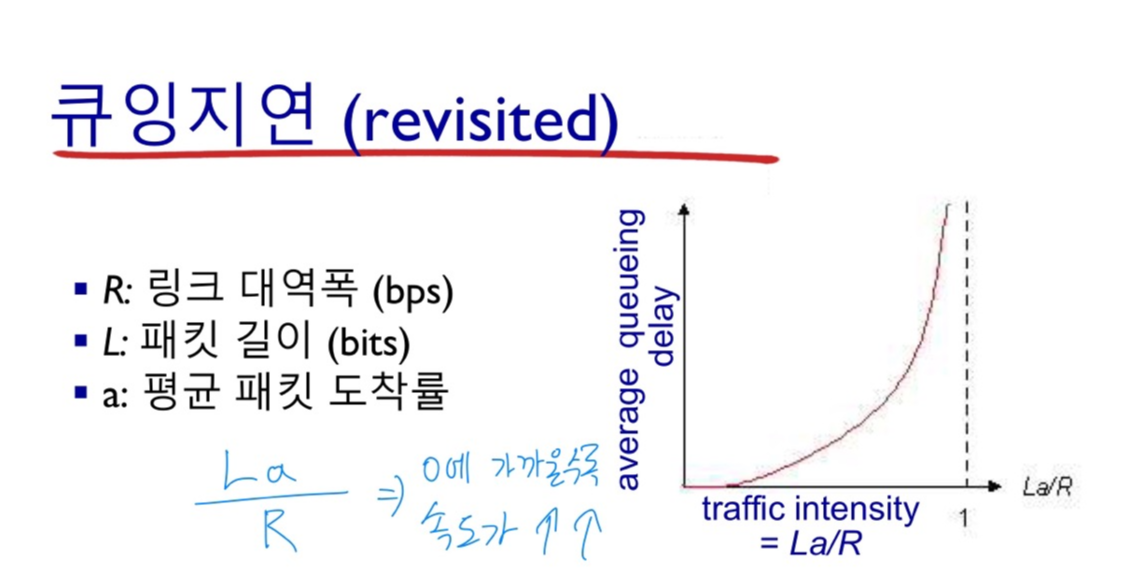
traffic intensity = (La/R)가 1에 가까워지면 막히는 정도가 늘어난다. 0에 가까우면 속도가 증가한다.
- loss
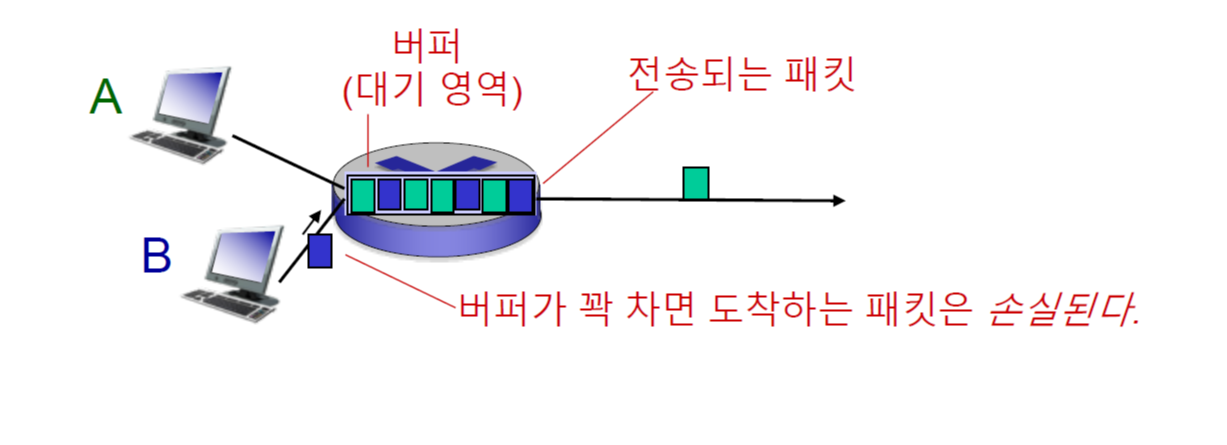
패킷 손실은 위와 같이 라우터의 buffer가 가득 차서이 들어갈 공간이 없을 때, 버려지는 현상이다. 이럴 때 재전송을 통해서 다시 보내야 한다.
재전송 방법들 뒷부분에서 배운다.
- throught
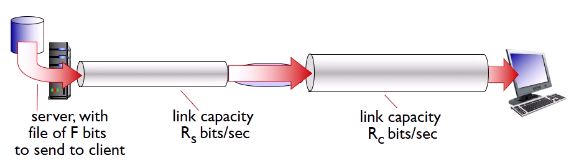
한마디로 성능이다. 단위시간 동안 sender와 receiver가 교환된 데이터의 양을 말한다.
처리율은 link의 bandwidth가 고정되었다 하더라고, 망상태에 따라(사용자가 얼마나 몰렸느냐) 달라지기도 한다.
'CS > 컴퓨터 네트워크' 카테고리의 다른 글
| Chapter 6 링크계층 (The Link Layer and LANs) (2) | 2023.06.06 |
|---|---|
| Chapter 5 네트워크 계층 (The Control Plane) (0) | 2023.06.05 |
| Chapter 4 네트워크 계층 (The Data Plane) (1) | 2023.06.03 |
| Chapter 3 전송계층 (Transport Layer) (0) | 2023.04.18 |
| Chapter 2 어플리케이션 계층 (Application Layer) (0) | 2023.04.10 |




댓글