2.1 네트워크 응용 프로그램의 원리 ( principles of network applications)

- Three-tier architecture (3 계층 아키텍처) PAD
Client 쪽
Presentation: 사용자 인터페이스와 관련된 부분
Server 쪽
Application: 데이터를 가공하고 비즈니스 로직을 처리하는 역할
Data: 데이터베이스나 파일등의 저장소에 접근하여 데이터를 CRUD 역할 (create, read, update, delete)
Client-server architecture
client와 server 간에 데이터를 주고받는 형태이다. client는 데이터를 요청해서 받는 쪽이고, server는 데이터를 보내는 쪽이다.
Server
- client가 언제 데이터를 요청할지 모르기에, 항상 ON 상태이다.
- client가 같은 IP 주소로 정보를 요청하므로 IP주소가 고정되어 있다.
- data center(cloud 기반)를 통해서 서버가 운용되는 경우도 있다.
Client
- 간헐적으로 연결된다.
- 일반적으로 동적 IP주소를 가진다. (IP주소가 충분하지 못하기 때문에)
- Clients끼리 직접적으로 communication을 못한다. 반드시 server를 통해서 데이터를 주고받는다.
P2P architecture
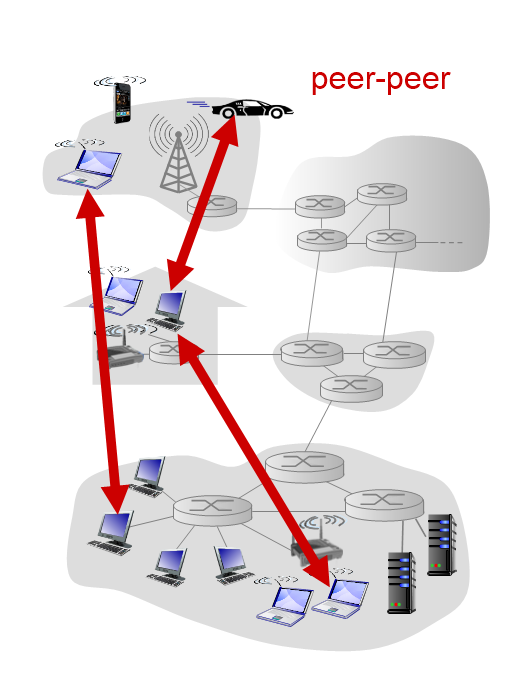
P2P방식은 서로 동등한 Peers(end systems)끼리 직접적으로 communication을 해서 정보를 주고받는다. 새로운 peers가 나타나면 스스로 규모가 늘어난다. P2P link가 많아지는 것이다. 이것을 self scalability(자기 확장성)라고 한다.
- server같이 항상 ON 되어 있는 것이 없다.
- peers는 IP주소를 변경할 수 있다. 새로운 IP주소가 부여가 된 상태에서도 여전히 P2P link를 유지하고 있다.
- 제약조건 : 사용자의 IP주소가 동적으로 바뀌면 P2P 네트워크를 뚫고 들어가지 못하는 경우가 있다. 그래서 네트워크 환경에 따라 P2P가 될 수도 안될 수도 있다.
- 옛날 mp3파일 공유, 두 사람 간에 화상통화, 블록체인 등등
Processes communicating
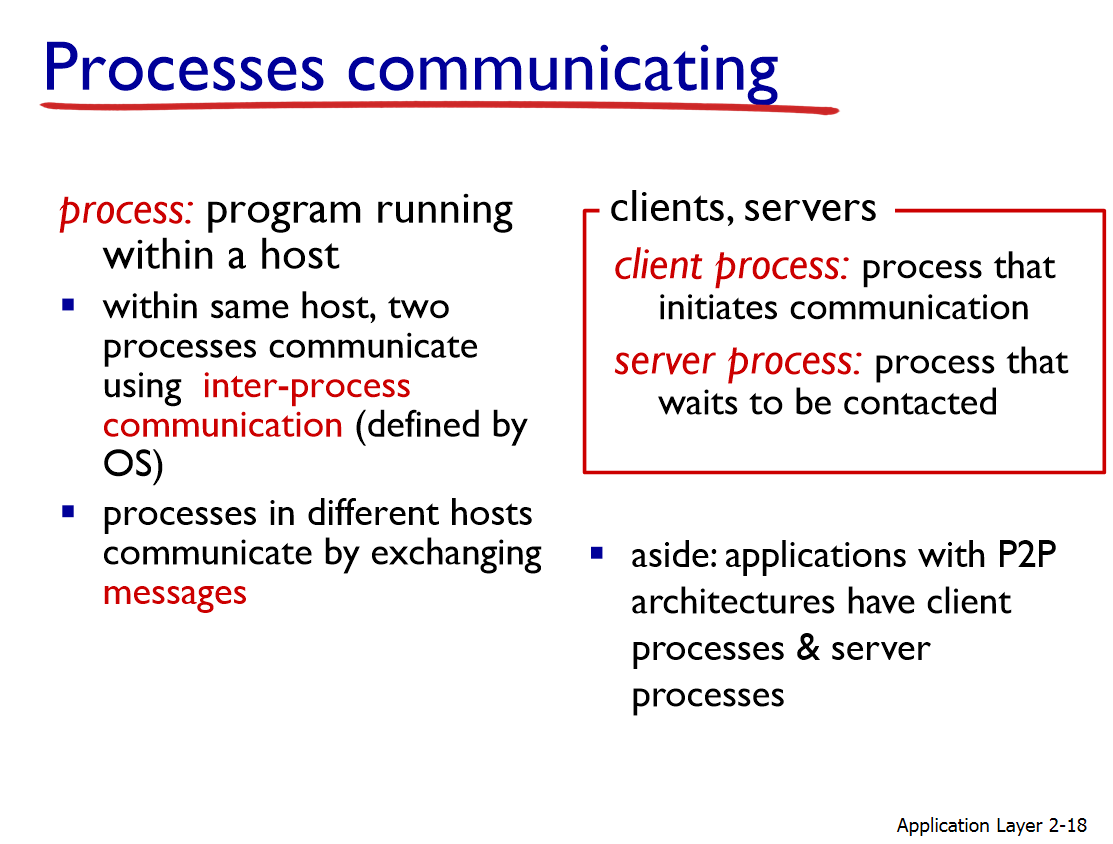
Process: 호스트 내에서 돌아가는 프로그램
- 같은 호스트 내에서 복수개의 processes가 돌아갈 수 있다. 두 개의 processes가 내부적으로 communication 할 수 있다. (IPC)
- 다른 호스트들에 있는 processes과는 messages 교환을 통해 communication 한다.
Client-Server 구조: server는 데이터를 제공하기 위해. client는 데이터를 받기 위하기 때문에 process가 다르다.
P2P 구조: client processes & server processes가 존재한다.
Sockets
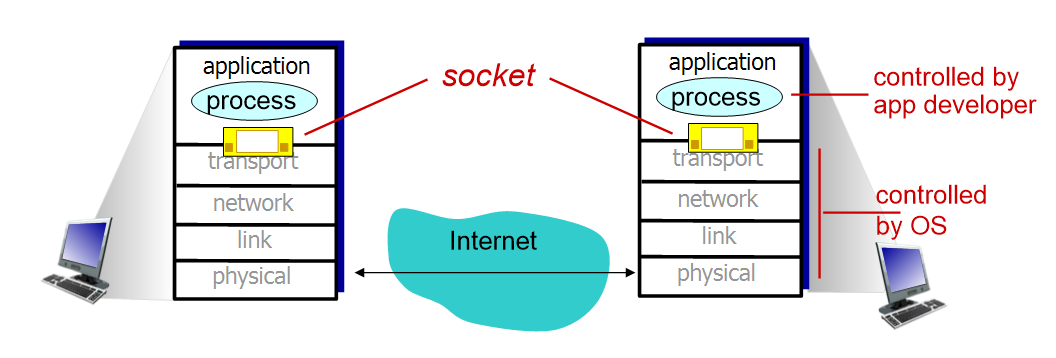
processes가 messages를 주고받는 경로(문)를Socket이라고 한다.
양쪽의 application process가 서로 메시지를 주고받으려고 한다. 일종의 문의 역할을 하는 socket이 있는데, socket을 통해서 어떻게 갈까? 아래 transport를 통해서 전달시켜 준다. application 입장에서는 process가 메시지를 툭 던진다. 아래에 있던 transport가 받아서 다음 과정으로 전달시킨다. 추후 다시 설명
Addressing processes
메시지를 받기 위해 process는 id가 필요하다. 이것은 port number이다.
예를 들어, 한 집에 4 식구가 산다고 해보자. 그 집에 각 사람들을 어떻게 구별할까?? 집주소는 하나만 쓰고 각 식구마다 이름을 붙이자. 이때 집주소는 IP주소이고, 그 집의 각 사람들에게 붙인 이름은 port number이다.
많이 쓰는 port number는 정해놓는다. HTTP: 80 mail: 25
IP주소가 128.119.245.12 인 호스트에서 HTTP 메시지를 보낸다 하면, port number는 80으로 보내는 것이다. 상대방은 IP주소를 보고 호스트를 구별하고, port number를 보고 processes를 구별하는 것이다.

2.2 Web and HTTP
Web page는 objects로 구성되어 있다. objects는 HTML file, JPEG, Java applet, audio file 등등으로 이루어져 있다. web page는 기본 objects가 포함된 기본 HTML file로 구성되어 있다.

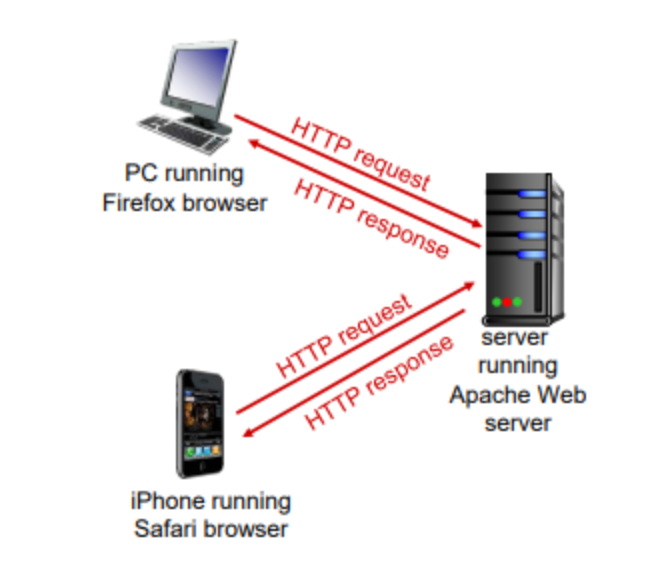
HTTP는 웹에서 사용되는 web application layer protocol이다. web application은 HTTP 외에는 프로토콜이 없다고 생각하면 된다.
클라이언트는 서버로부터 정보를 받아서 display 한다. 서버는 URL 정보를 가지고 있고, 해당하는 응답을 보내준다.
application layer에 있는 HTTP는 아래 layer인 transport layer에서 사용한 TCP를 사용한다. 웹은 신뢰성이 중요하기 때문에 신뢰성 없는 UDP는 손실이나 오류가 발생할 수 있어서 TCP를 사용한다.
HTTP는 stateless(비상태 프로토콜)이다. HTTP 입장에서는 클라이언트의 요청에 대한 정보에 관심 있다.그냥 무언가가 오면, 상응하는 답을 보낼 뿐이다. "stateless" 상태를 유지하지 않기 (한번 왔던 사용자인지 알 수 없다) 때문에 가벼워서 서버가 부담 없이 돌릴 수 있다.
HTTP connections
HTTP connection은 두 가지가 있다.
1. non-persistent (비지속) HTTP
- TCP 연결을 통해 전송되는 객체 수는 최대 하나이고 연결 후 connection이 닫힌다.
- 여러 개체를 다운로드하려면 여러 연결이 필요하다.
2. persistent (지속) HTTP
- 클라이언트와 서버 간 단일 TCP 연결을 통해 여러 개체를 전송할 수 있다.
Non-persistent HTTP


위와 같은 URL을 들어간다고 가정해 보자.
1a. HTTP 클라이언트가 HTTP 서버에 TCP connection(연결)을 요청한다.
1b. HTTP 서버는 accept 함. accept 했다는 사실을 클라이언트에 알린다.
2. HTTP 클라이언트는 HTTP 요청 메시지(URL 포함)를 TCP 연결 소켓으로 보낸다.
3. HTTP 서버는 요청 메시지를 수신하고, 요청된 객체를 포함하는 응답 메시지를 형성하며, 소켓에 메시지를 보낸다.
4. HTTP 서버는 하나 주고받았으니 TCP 연결을 닫는다.
5. HTTP 클라이언트는 응답 메시지를 수신하고 해당하는 것을 display 한다.
6. 1~5번 과정 반복
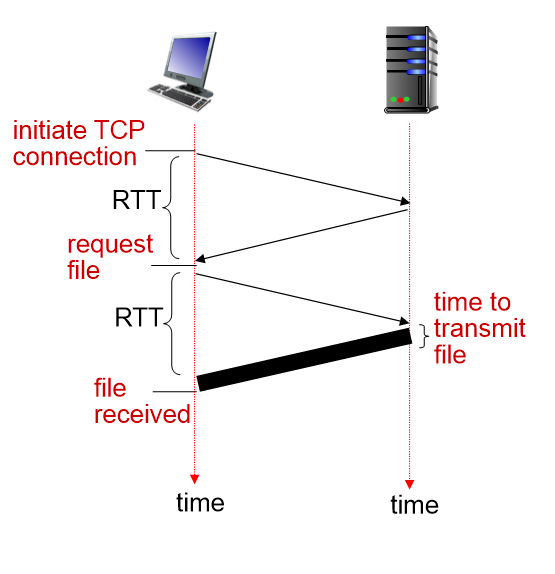
- RTT(round-trip time): 패킷이 클라이언트에서 서버로 왕복하는 시간
- HTTP response time: 파일전송 시간, TCP 연결을 시작하기 위한 하나의 RTT
- non-persistent HTTP response time = 2 RTT + file transmission time
문제점: 객체당 2개의 RTT가 요구됨, 각 TCP 연결에 대한 OS 오버헤드발생
Persistent HTTP
Persistent HTTP는 TCP 연결 한 번에 여러 개의 객체를 전송할 수 있다. 클라이언트는 참조된 객체를 만나는 즉시 request를 보낸다.
- persistent HTTP response time = 1 RTT + 1 RTT*객체의 수 + file transmission time
HTTP request(요청)
HTTP 요청은 클라이언트가 서버로 데이터를 보내는 방식

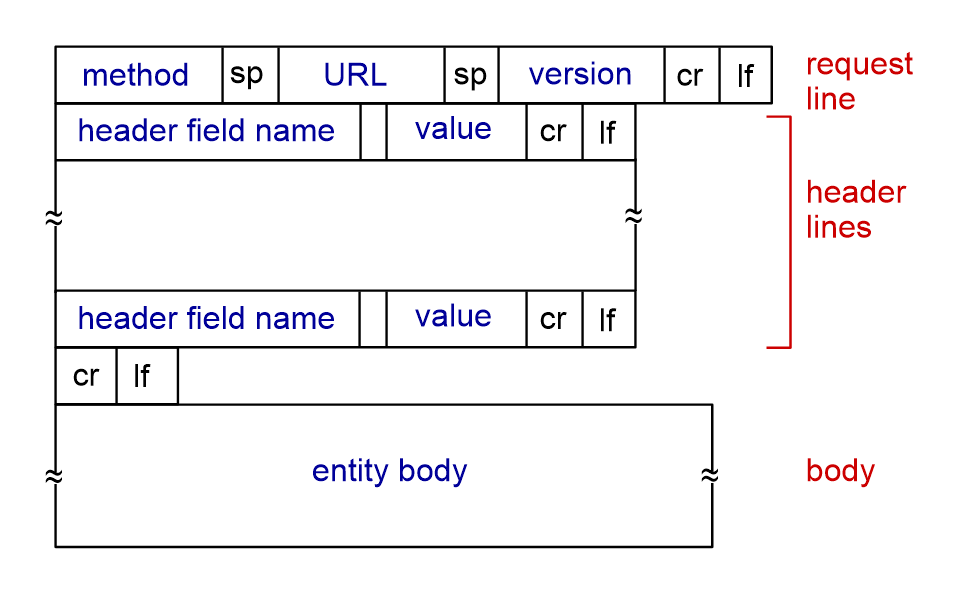
method : 클라이언트가 서버에 요청하는 동작을 정의 (GET, POST 등등)
URL : 클라이언트가 요청하는 서버의 리소스를 식별
header : 요청에 대한 추가적인 정보를 제공
body : 요청한 데이터를 전송하는 부분 (HTTP 메서드가 GET일 경우에는 바디가 없다)
요청 방식
1. POST : body에 데이터를 실어서 서버로 데이터를 전송하는 방식
2. URL : HTTP 메서드 중 GET 메서드를 사용하여 서버로 데이터를 전송하는 방식
HTTP response(응답)
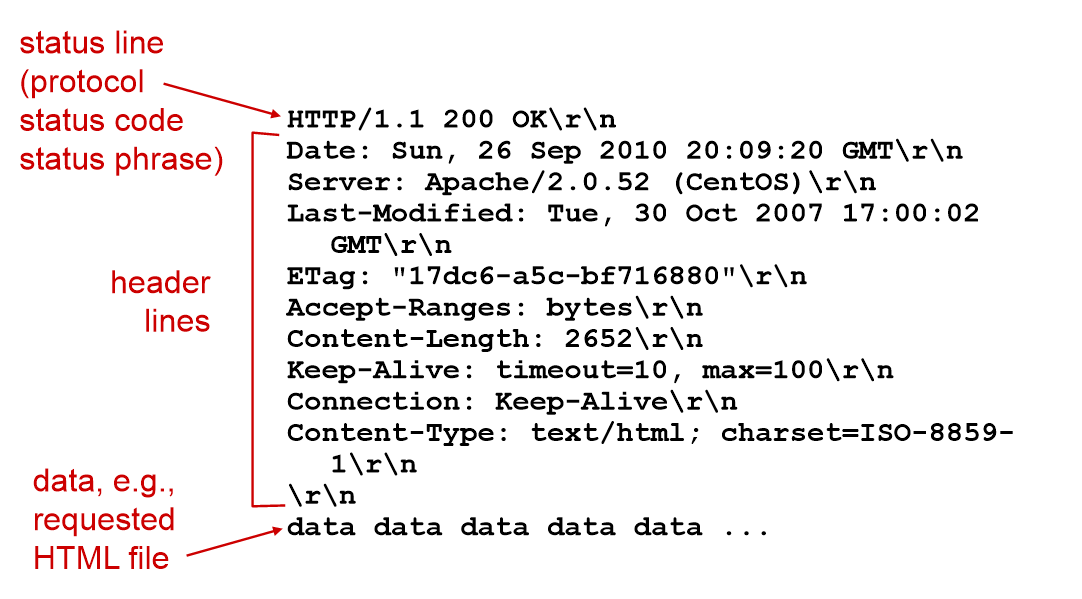

HTTP response status codes
200 OK : 요청 성공
301 Moved Permanently : 요청된 객체가 옮겨졌다. (거의 볼일 없음)
400 Bad Request : 서버가 이해할 수 없는 요청 왔다.
404 Not Found : 서버에서 요청된 문서를 찾을 없다.
505 HTTP Version Not Supported : HTTP의 버전이 지원되지 않는다.
cookies
종류
1. HTTP request message의 header line의 Cookie
2. HTTP response message의 header line의 Cookie
3. user의 host, user의 browser에 의해 관리되는 Cookie
4. 웹사이트 백엔드 데이터베이스 상에 있는 Cookie
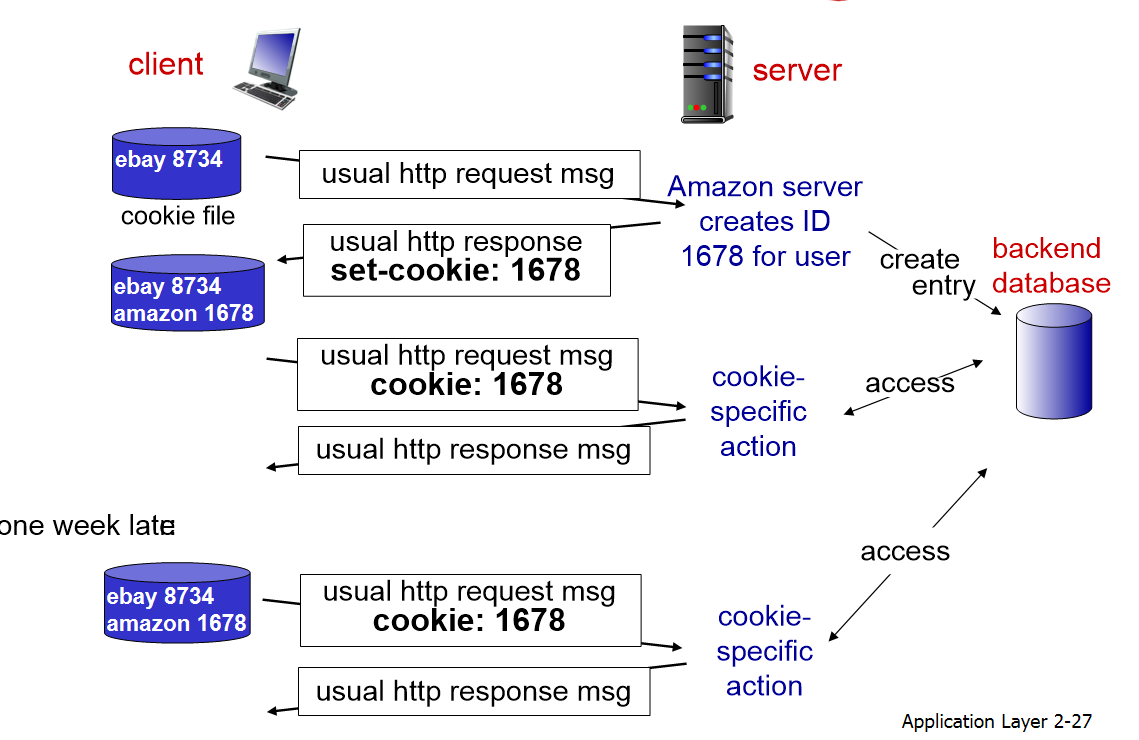
- Client에 Cookie 파일이 없으면 server에서 user ID 만들고 response msg에 Cookie 파일에 담아 보내준다. 그리고 이 user ID는 백엔드 데이터베이스에 기입한다.
- Client에 Cookie 파일이 있으면 request msg에 Cookie 파일을 함께 보내고, server의 백엔드 데이터베이스에서 user의 state에 해당하는 response msg를 보내준다.
HTTP가 Cookie(state)를 전달해 준다고 해서 HTTP가 state를 가지고 있는 것은 아니다. state를 가지고 있는 것은 Cookie이고, HTTP는 양쪽의 end points에서 상호보관하고 있는 Cookie(state)를 전달만 해준다는 것을 기억해야 한다.
Cookie가 사용되는 곳
- 웹브라우저에 대한 로그인 정보 기억
- 온라인 몰에서의 구매목록 기능
- email 정보 기억
thus, privacy 문제 발생
Web caches
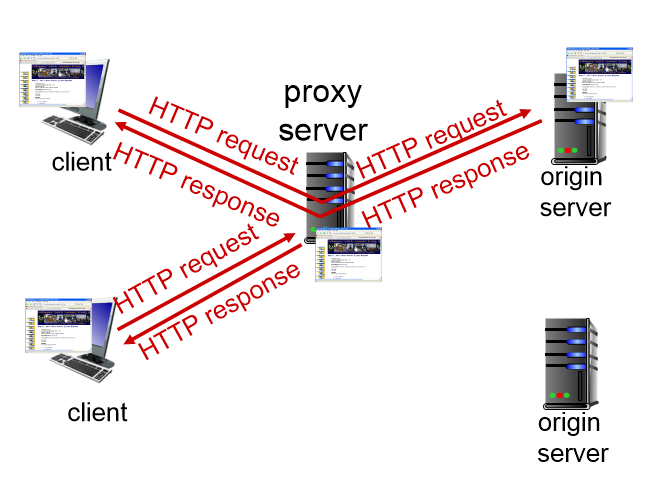
client가 멀리 있는 origin server까지 가지 않고 가까운 proxy server의 web caches 파일에 접근하여 원하는 파일을 받아오는 기술이다.
과정
client가 proxy server에 접근해 caches file이 있는지 본다.
=> caches가 있으면 proxy server에서 데이터를 받아온다.
=> caches가 없으면 proxy server는 origin server로부터 데이터를 요청하여 받아온다. 받은 데이터는 proxy server에 저장된다. 그리고 client에게 데이터를 전달해 준다.
그래서 최초의 client를 제외한 clients는 proxy server에서 정보를 받아올 수 있게 된다.
Web caches 쓰는 이유
1. response time을 줄일 수 있다. Web caches는 굳이 멀리 있는 origin server로 가지 않고, 가까이 있는 proxy server로 가서 정보를 가져오기 때문에 요청-응답 시간을 줄일 수 있다
2. server의 traffic을 줄일 수 있다. Web caches를 사용하면 client의 request가 모두 server로 가는 것이 아닌, proxy server로 분산되기 때문에, 그만큼 request에 대한 traffic을 아낄 수 있다.
2.3 electronic mail (e-mail)
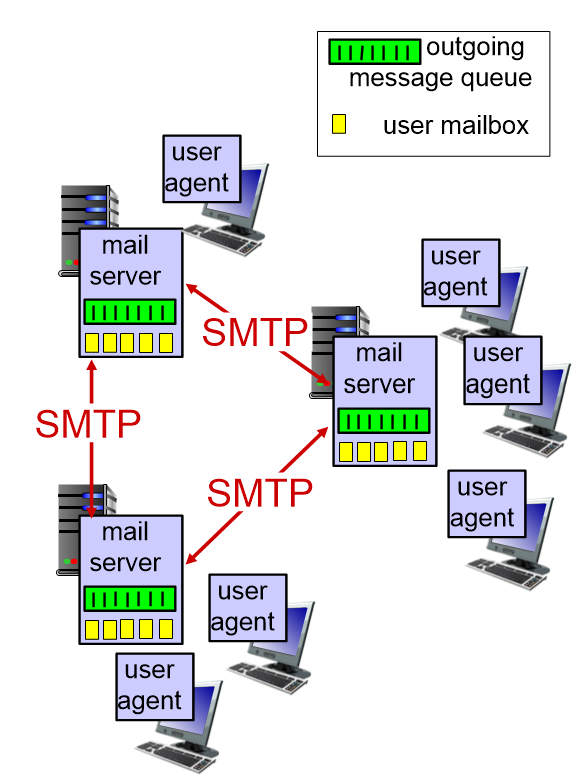
Email system은 크게 3가지로 구성되어 있다.
1. user agent : mail reader라고도 한다. 메일을 작성하거나 읽는 것을 수행한다.
2. mail server : email msg를 가지고 있는 server이다. email을 갖고 온다고 하면, server에 저장되어 있는 메시지를 가지고 온다 생각하면 된다. 위 그림의 mailbox는 유저에게 들어온 email들을 가지고 있다. message queue는 나갈 email들을 가지고 있다.
3. SMTP (simple mail transfer protocol) : mail server들 간에 주고받을 때 사용하는 protocol이다. mail을 보내는 쪽 서버가 client. 받는 쪽 서버가 server가 된다.
SMTP는 TCP를 사용하고 port number는 25번 사용한다. 보내는 쪽과 받는 쪽이 같은 port number를 사용해야 한다.
전송 과정이 3개의 과정으로 구성된다.
1. handshaking : TCP connection open.
2. transfer : 전송
3. closure : 위 과정이 끝나면 TCP connection close.

Handshaking 하고, DATA 전까지 email을 주고받는데 필요한 과정을 주고받고, (Do you like ketchup? How about pickles? -> 실제 메시지) 실제 메시지를 전달하고 끝낸다.
HTTP와 SMTP 비교
- (HTTP: pull , SMTP: push) => HTTP는 server에 있는 내용 가져오는 것이고, SMTP는 server에다가 내용을 보내는 것이다.
- email은 한번 가면 연달아 가기 때문에 SMTP는 persistent connection을 이용한다. HTTP는 Non-persistent, persistent connection을 이용한다.
Alice -> Bob mail 전송 과정
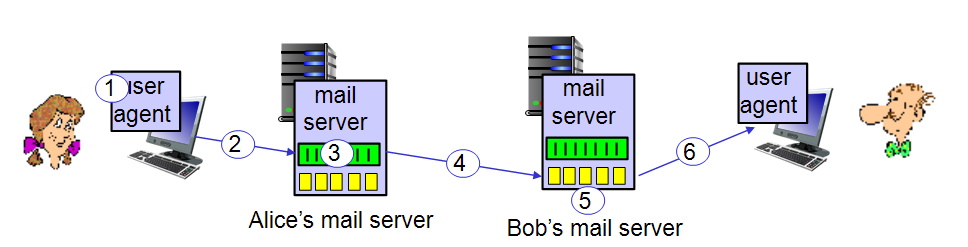
요약하자면,
1. Alice가 메일을 보냄.
2. 3번 mail server에서 Alice의 메일을 받음.
3. 5번 mail server로 Alice의 메일을 전송.
4. Bob이 메일을 열면 Bob의 user agent로 메일 전송.
Mail access protocols
Mail access protocol이란 user agent가 Mail server로부터 가지고 오는 protocol이다.
(주의) SMTP는 Mail server들 간에 메시지를 교환하는 protocol이다.
1. POP3 : 다운로드와 삭제가 가능하나 삭제하면 되돌리기 불가하다. download-and keep 형태. 받아와서 PC에 email을 저장하는 형태이다.
2. IMAP : 모든 메시지들이 내 PC 말고 서버에 저장된다. 단지 서버에 있는 것을 읽는 것이다. user들이 폴더를 만들어서 메시지를 분류하는 기능이 추가되었다.
3. HTTP : 최근에는 그냥 웹으로 접속해서 메일을 본다.

- authorization phase : user id와 password를 입력해서 맞으면 OK. 사용자 인증 과정이 있다.
- transaction phase : 받은 email들의 list를 보여준다. (retr: msg를 가져옴. dele: 삭제)
2.4 DNS ( Domain Name System)
컴퓨터는 통신을 하기 위해서 IP주소가 필요하다. 사람은 IP주소가 불편하기에 Domain Name 혹은 Host Name을 사용한다. 그래서 DNS(Domain Name System)는 IP주소와 Domain Name을 연결해 주는 시스템이고 여러 name server의 계층에 구현된 분산 데이터베이스이다.
DNS는 불필요한 데이터 전송이나 통신적인 traffic을 줄이기 위해서 UDP를 사용한다.
DNS server
단일 DNS 서버에 있는 중앙 집중 데이터베이스는 확장성이 전혀 없고, 트래픽, 유지관리 등 문제가 많기 때문에 DNS는 분산되도록 설계되었다.
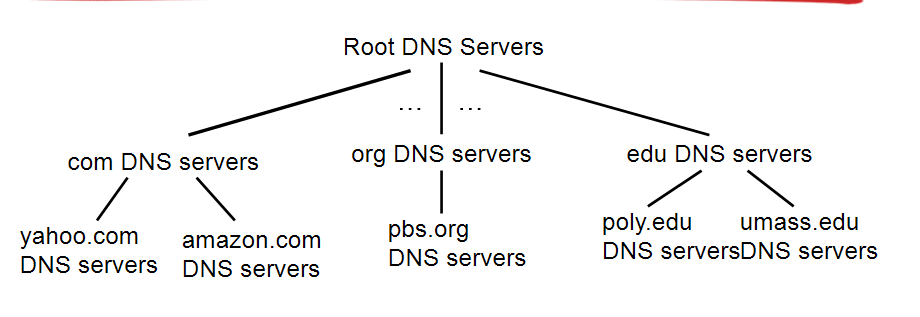
- 루트(root) DNS 서버 : 전 세계에 400개 이상의 루트 DNS 서버가 있다.
- 최상위 레벨 도메인(TLD, top-level domain) DNS 서버 : com org net edu 같은 상위 레벨 도메인과 국가별 상위 레벨 도메인(uk, fr, jp 등)에 대한 TLD 서버가 있다.
- 책임(authoritative) DNS 서버 : 조직의 자체 DNS 서버이며 호스트 네임을 IP 주소로 매핑하는 DNS 레코드를 제공한다.
- 지역(local) DNS 서버 : 계층 구조에 속하지는 않는다.
위의 서버들이 어떻게 상호 작용을 하는지를 알기 위해서 어떤 DNS 클라이언트가 호스트 네임 www.amazon.com의 IP 주소를 얻기 원한다고 가정해 보자
- 클라이언트는 루트 서버 중 하나에 접속한다.
- 루트 서버는 최상위 레벨 도메인 com을 갖는 TLD 서버 IP 주소를 보낸다.
- 클라이언트는 TLD 서버 중 하나에 접속하고, 서버는 도메인 amazon.com을 가진 책임 서버의 IP 주소를 보낸다.
- 클라이언트는 amazon.com의 책임 서버 중에서 하나로 접속한다.
- 서버는 호스트 네임 www.amazon.com의 IP주소를 보낸다.
루트, TLD, 책임 DNS 서버들은 위의 그림처럼 모두 DNS들의 계층구조를 갖는다. 추가적으로 DNS의 다른 중요한 형태는 로컬 DNS 서버인데 로컬 DNS 서버는 서버들의 계층 구조에 엄격하게 속하지는 않지만, DNS 구조의 중심에 있다. ISP들은 로컬 DNS 서버로부터 IP 주소를 호스트에게 제공한다.
DNS caching
DNS 서버가 응답을 받았을 때, 로컬 메모리의 응답에 대한 정보를 저장한다. 요청한 정보가 캐싱되어 있다면, 루트 DNS 서버를 거치지 않고 호스트에게 응답한다.
DNS records
도메인 이름과 IP 주소 간의 매핑 정보를 저장하는 데이터베이스이다. DNS records는 인터넷에서 도메인 이름을 찾을 때 사용한다.
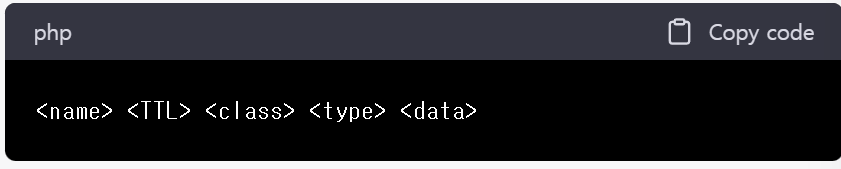
- <name> : 이름을 나타낸다. (일반적으로 도메인 이름)
- <TTL> : 캐시 될 수 있는 시간을 초 단위로 지정한다.
- <class> : 클래스를 나타낸다. (대부분의 경우 IN (인터넷) 클래스 사용)
- <type> : 유형을 나타낸다. A, AAAA, CNAME, NS, MX 등이 있다.
- <data> : 정보를 나타낸다. 유형에 따라 다르게 표현된다.

<name> "example.com."
<TTL> 86400초
<class> IN <type> A
<data> "192.0.2.1"
type 종류
- A record: 도메인 이름(host name)과 연결된 IP주소를 나타낸다.
- CNAME record: 도메인 이름과 다른 도메인 이름 간의 매핑 정보를 나타낸다.
- MX record: 이메일을 전송할 때 사용되는 메일 서버의 도메인 이름을 나타낸다.
- NS record: 특정 도메인 이름에 대한 DNS 서버의 정보를 제공한다.
2.5 content distribution networks(CDNs)
CDN (Content Distribution Networks)
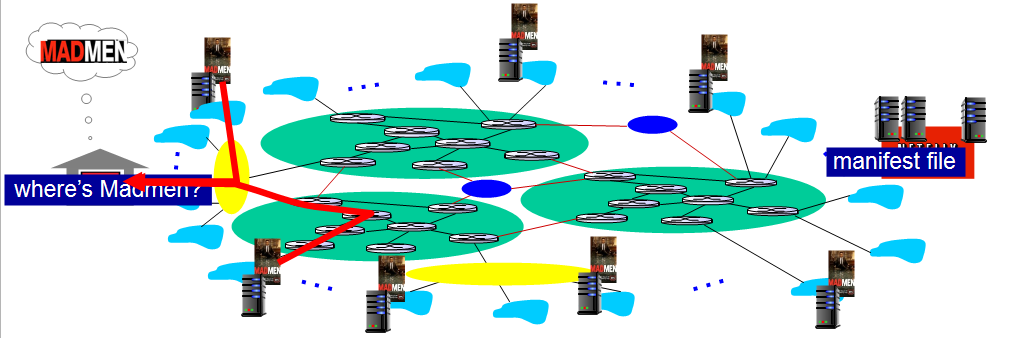
CDN(Content Delivery Network): 인터넷 사용자들에게 콘텐츠를 빠르게 전송하기 위한 분산 시스템이다. 전 세계에 여러 지역에 서버를 설치하고 콘텐츠를 분산 저장하여 지리적으로 떨어져 있는 사용자들에게도 빠른 속도로 콘텐츠를 제공할 수 있다.
Over-The-Top (OTT)
전통적인 방송 및 케이블 TV 네트워크를 우회하여 인터넷을 통해 비디오, 음악, 메시징 등 다양한 콘텐츠를 제공하는 서비스를 말한다. (Netfilx 등등)
OTT 서비스의 장점은 시청자가 언제 어디서든 원하는 콘텐츠를 시청할 수 있으며, 방송사나 케이블 TV 프로바이더와의 계약 없이도 콘텐츠를 이용할 수 있다는 것이다.
'CS > 컴퓨터 네트워크' 카테고리의 다른 글
| Chapter 6 링크계층 (The Link Layer and LANs) (2) | 2023.06.06 |
|---|---|
| Chapter 5 네트워크 계층 (The Control Plane) (0) | 2023.06.05 |
| Chapter 4 네트워크 계층 (The Data Plane) (1) | 2023.06.03 |
| Chapter 3 전송계층 (Transport Layer) (0) | 2023.04.18 |
| Chapter 1 컴퓨터 네트워크와 인터넷 (0) | 2023.04.04 |




댓글