4.1 Overview of Network layer
- datagram
transport layer에서는 segment였던 것이 network layer에서는 datagram이라고 부른다. 그래서 보내는 쪽이 segment를 datagram으로 encaptulation하고, 받는 쪽에서 segment로 바꾸어줘서 transport layer로 전달한다.
Network layer의 두가지 기능
1. Forwarding (포워딩): 패킷이 라우터의 input에 도달하면 라우터는 패킷을 적절한 output으로 이동시켜야 한다. (포워딩은 data plane에 구현된 가장 보편적이고 중요한 기능)
2. Routing (라우팅): 송신자가 수신자에게 패킷을 전송할 때 네트워크 계층은 패킷 경로를 결정 해야 한다. 경로를 계산하는 알고리즘을 '라우팅 알고리즘' 이라한다. (패킷 전송 라우팅은 네트워크 계층의 control plane에서 실행된다.)
data plane, control plane
1. data plane
local 라우터마다 있는 기능이다. 어떤 datagram이 라우터의 input으로 들어왔을 때 어떻게 forwarding해줄 것인가(forwarding function) 이런 것을 data plane이라고 보면 된다. 즉 header에 있는 값(data)이 들어와서, 이 data마다 라우터에서 내보내주게 되는 것이 data plane이다.
2. control plane
network-wide logic이다. 모든 라우터가 공통으로 돌릴 수 있는 부분들이다. 예를 들어 routing protocol같이 어떤 라우터든 공통으로 돌아갈 수 있는 것이 control plane이다. 그래서 datagram을 보낼 path를 결정하는 routing에 대한 것이 control plane이다.
4.2 What's inside a router

routing processor는 control plane영역, software이다. 시간은 millisecond가 걸린다.
그 아래는 data plane영역, hardware이다. 시간은 nanosecond가 걸린다.
그렇다면 bottleneck(흔히 병목현상) 은 routing processor가 된다. 여기서 input과 output의 forwarding은 nanosecond로 빠르지만, 그 중간에서 processing하는 routing processor가 millisecond로 느리기 때문에 input port에 queueing delay가 생기게 된다.
Router 구조
1. input port
2. high-seed switching fabric (스위칭 구조)
3. output port
4. routing processor (5장 학습)
1. Input port

physical layer(line termination) -> link layer -> queue -> switch fabric 순이다.
queue에 datagram이 들어가 있는 동안, 맨 첫번째 datagram부터 IP header를 읽어서 어디로 보내야 할지를 찾는다. (검색 기능을 수행한다). 그리고 Forwarding을 한다.
빨간 상자에서 forwarding table을 참조하여 도착된 패킷이 switch fabric를 통해 전달되는 라우터 output port를 결정한다.

Input port에서 datagram이 들어오는 것이 switch fabric로 보내는 것보다 빠르면input port에서 queueing이 생기게 된다. 심지어 input buffer가 overflow일 경우 손실나버린다.
Head-of-the-Line(HOL) blocking이란 queue 맨 앞에 있는 것이 line의 head부분인데, 이 head가 나가지 못하면 뒤에거까지 못 나감을 말한다.
forwarding 하는 방법에는 두가지가 있다.
1. Destination-based forwarding : IP 주소만 보고 판단

첫번째 칸은 11001000 … 00000000 부터 11001000 … 11111111까지는 link interface 0번으로 보내라는 것.
두번째 세번째 네번째도 마찬가지이다.
Routing 알고리즘으로 범위가 설정되고, 어떤 주소에 대해서 어떤 interface를 통해 나가야 빨리 나가는지 학습해 나간다. 즉, router protocol을 통해 학습하는 것이다.
이것은 전세계 수많은 IP들을 전부 다 해준다. 학습해가면서 업데이트한다. IP주소의 범위는 대략적으로 국가적으로 나누어져 있다. 하지만 routing 알고리즘은 오버헤드가 상당히 크다.
Longest prefix matching
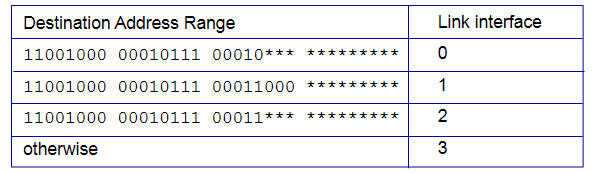
범위를 어떤식으로 나누게 되냐면, 첫번째 IP를 보자. 앞에서부터 8bit, 8bit, 5bit, 나머지 *으로 되어있다. *은 무엇이 오든 상관없다. 앞의 8,8,5bit만 보고 일치하면 0번 link로 보내는 것이다. 아래들도 마찬가지이다.
이때 Longest prefix matching을 사용하는데, 앞에서부터 쭉 봐서 제일 길게 matching이 되는 entry를 찾아서 이 entry에 해당하는 link로 datagram을 보내라고 알려준다.

첫번째 주소는 0번 link에 해당한다.
두번째 주소는 1번 link에 해당한다. 1,2번 링크가 일치하지만 1번 link entry가 2번 link entry보다 길게 matching 되기 때문이다.
2. generalized forwarding : IP 헤드 정보를 보고 output 판단
header field 값들의 집합을 가지고 forwarding하는 방식이다.
2. Switching fabric
패킷을 input buffer에서 output buffer로 전달하는 부분이다. switching rate라 하면 input에서 output으로 초당 몇 개의 패킷을 보내는 전송률이다. N개의 input이 있다면 line의 rate가 N배가 된다. 높을수록 성능이 좋다고 말한다.
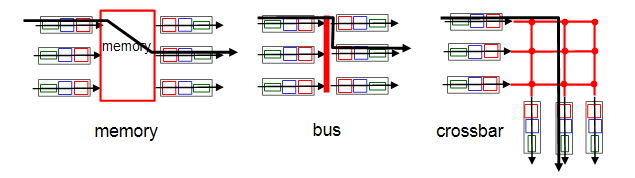
1. memory :가장 오래된 방식
가장 전통적인 방식이다.
input port에 data를 memory에 넣었다가 output port로 보내는 형태이다. bus를 두번 지난다. (input -> memory, memory -> output)
이 방식은 memory의 bandwidth에 의해서 속도가 제한된다. 메모리(software)의 연산은 느리다. 결국 메모리를 사용한 이 방식은 느리다는 뜻이다.
2. bus : line을 공유하여 한번에 하나씩 보내는 방식
bus를 통해 스위치되는 방식이다.
bus contention이 있다. 즉, bus에서는 한번에 하나씩만 데이터가 전송되어야 한다. 결국 switching rate는 bus의 bandwidth에 의해 결정된다.
Cisco에서는 32Gbps의 bus를 붙여놓았다. 그래서 Switching rate가 32Gbps이다. 이 speed로 access network나 enterprise router에서 충분하다고 한다. (Cisco는 현재 전세계 라우터를 독점하고 있는 기업이다.)
3. interconnection network (crossbar) : line을 많이 사용하여 동시에 여러 개 보낼 수 있는 방식
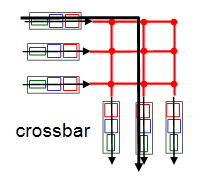
bus의 bandwidth를 극복하기 위해 등장했다. bus가 line 하나였다면 이 방식은 line을 여러 개 교차시켜 놓는다. 그래서 데이터를 동시에 보낼 수 있다. 그러나 line을 많이 두기 떄문에 Hardware적인 구현비용이 더 들어가게 된다.
Cisco는 이런 crossbar를 이용해서 60Gbps까지 끌어올렸다.
3. output port
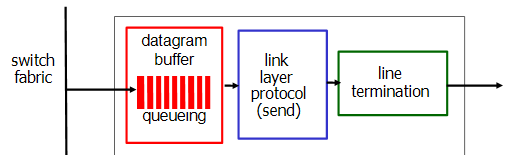
Output port에서도 Input과 마찬가지로 buffering이 된다. transmission하는 속도보다 들어오는 속도가 빠르면 buffering이 된다. 마찬가지로 손실도 날 수 있다.
그렇다면 buffer를 얼마나 주어야 할까? buffer를 많이 쓰면 delay가 엄청 늘어날 수 있다. 차라리 드랍시키는 게 낫다. 이와 같은 문제로 buffer의 크기는 중요하다.
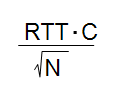
buffer의 크기는 RTT * C(capacity) 로 정한다. 만약 N개의 flow가 있다면 ->
식이 성립한다.
Output port에는 queueing 되어 있는 것들 중에 어떤 것부터 내보내는지에 대한 Scheduling 이슈가 있다.
Scheduling mechanisms
discard policy 3가지
1. tail drop : 마지막으로 도착하는것 드랍
2. priority : 우선순위 낮은 얘를 드랍
3. random : queue가 거의 찼을 때, 새로운 패킷이 온다면 원래 쌓여있던것들 중 랜덤으로 드랍. 실제 사용하는 방식
Scheduling policy 3가지
1. Priority
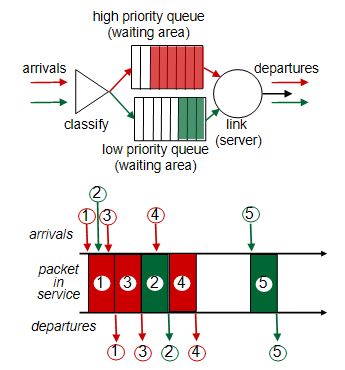
가장 높은 우선순위의 패킷을 먼저 전송하는 기법이다.
-> (빨간색이 초록색보다 우선순위가 높으므로 초록색2번보다 빨간색 3번이 먼저 출발했다.)
2. Round Robin (RR)
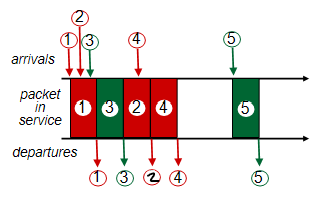
Round Robin 스케줄링은 패킷에 class를 부여하여 구분한다. 큐를 스캔하여 보낼 패킷이 있다면 각각의 클래스 별로 번갈아 패킷을 전송한다.
- 가장 먼저 도착한 1번 패킷을 전송하기 위해 큐에 넣는다.
- 1번 패킷이 전송되길 기다리는 도중 2번 패킷과 3번 패킷이 도착했다.
- 이 때 3번 패킷이 색이 다르므로 먼저 큐에 넣고 2번 패킷을 다음으로 넣는다.
- 1번, 3번, 2번 패킷이 전송된다.
- 4번 패킷이 도착했으므로 4번 패킷을 큐에 넣고 전송한다.
- 5번 패킷이 도착했으므로 5번 패킷을 큐에 넣고 전송한다.
3. Weighted Fair Queuing (WFQ)
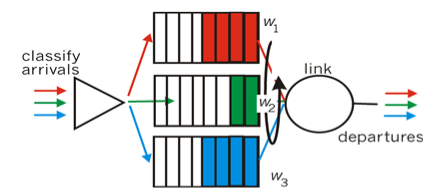
WFQ는 Round Robin을 일반화 한 방식이다. 각 클래스 마다 큐를 설정하여, 각각 클라스를 번갈아 패킷을 보내는 방식은 Round Robin과 비슷하다. 다만 다른점은 큐에 가중치(weight)를 둔다는 점이다.
4.3 IP: Internet Protocol
IP datagram format

- Version (ver): IP datagram의 버전을 나타낸다. 현재 IP 버전은 IPv4와 IPv6가 있으며, 이 필드는 4비트로 표시된다.
- Header Length (head.len): IP datagram의 헤더의 길이를 나타낸다. 이 필드는 4비트로 표시되며, 헤더의 길이는 32비트(4바이트) 워드 단위로 표시된다.
- Type of Service (TOS): IP datagram의 서비스 유형을 나타낸다. 이 필드는 8비트로 표시되며, 패킷의 우선순위, 서비스 품질, 트래픽 제어 등과 같은 서비스 관련 정보를 지정할 수 있다.
- Length: IP datagram의 전체 길이를 나타낸다. 이 필드는 16비트로 표시되며, 헤더와 데이터를 포함한 전체 패킷의 길이를 바이트 단위로 나타낸다.
- 16-bit Identifier: IP datagram을 식별하는 데 사용되는 16비트 식별자이다. 이 필드는 패킷이 조각화되거나 재조립될 때 사용된다.
- Flags (flgs): IP datagram의 조각화와 관련된 플래그를 나타낸다. 이 필드는 3비트로 구성되며, 패킷 조각화 및 재조립을 제어하는데 사용된다.
- Fragment Offset: IP datagram 조각의 오프셋을 나타낸다. 이 필드는 13비트로 표시되며, 패킷이 조각화되고 재조립될 때 조각의 순서를 결정하는 데 사용된다.
- Time to Live (TTL): IP datagram이 네트워크에서 수명이 지나기 전에 존재할 수 있는 최대 라우터 수를 나타낸다. 이 필드는 8비트로 표시되며, 라우팅 루프와 같은 문제를 방지하기 위해 사용된다.
- Upper Layer: IP datagram에 포함된 상위 계층 프로토콜을 나타낸다. 이 필드는 8비트로 표시되며, IP 패킷의 데이터를 어떤 프로토콜이 처리하는지를 지정한다. 예를 들어, 값이 6인 경우 TCP를 나타낸다.
- Header Checksum: IP datagram 헤더의 오류 검사를 위한 체크섬 값을 포함한다. 이 필드는 16비트로 표시되며, 헤더의 데이터 무결성을 확인하는 데 사용된다.
- 32-bit Source IP Address: IP datagram의 출발지 IP 주소를 나타낸다. 이 필드는 32비트로 표시되며, 송신자의 IP 주소를 식별한다.
- 32-bit Destination IP Address: IP datagram의 목적지 IP 주소를 나타낸다. 이 필드는 32비트로 표시되며, 수신자의 IP 주소를 식별한다.
- Options: IP datagram에 추가적인 옵션 정보를 포함할 수 있는 영역이다. 이 필드는 선택적으로 사용되며, 일반적으로 헤더의 길이가 유동적으로 변경될 수 있도록 한다.
- Data: IP datagram에 포함된 실제 데이터를 나타낸다. 이 필드는 헤더 이후의 나머지 부분을 차지하며, 전송하고자 하는 실제 데이터가 포한한다.
TCP header는 20bytes이고, IP header도 20bytes이다. TCP IP는 합쳐서 최소 40bytes가 된다. 여기에 data payload가 붙는다. 용량이 크다.
IOT에서는 TCP IP를 잘 사용하지 않는다. IOT는 센서들이 데이터를 전달하는데 몇bit 밖에 안된다. 이 몇bit를 전달하기 위해 TCP IP 40bytes를 붙이는 건 배보다 배꼽이 큰 격이다. 오버헤드가 크다.
TCP checksum vs IPv4 checksum
- 계산 차이: TCP 체크섬은 header와 data를 모두 포함하여 계산한다. 반면에 IPv4 체크섬은 IP header 만을 대상으로 계산됩니다.
- 목적 차이: TCP 체크섬은 TCP header와 data의 오류를 감지하기 위해 사용된다. 즉, TCP header와 data가 수정되었는지 여부를 확인한다. 반면, IPv4 체크섬은 IP header의 오류를 감지한다. IP header가 변경되거나 손상되었는지 여부를 확인하는 데 사용한다.
IPv4 cheaksum이 header만 계산하는 이유는 엄청난 양의 패킷이 오기 때문에 checksum을 계산하여 다시 보내는것 자체가 부담이기에 data라도 미포함하여 부담을 조금 줄이기 위해서이다.
IP fragmentation, reassembly
network link들은 MTU(Maximum transfer size)를 가지고 있다. 각 link들의 type이 다르고 MTU가 다른 경우가 있어, 경우에 따라서 IP datagram을 쪼갤 수 있게 만들었다.
fragmentation
한 개의 datagram을 여러 개의 datagram으로 쪼개는 것. 만약 한 개의 datagram을 3개로 쪼갠다면, 3개의 header와 3개의 payload가 된다. 이 때 header부분은 동일한 부분도 있지만 flagmentation에 관한 부분은 다르다.
reassembly
쪼개진 datagram을 합치는 것. end host에서 쪼개진 data를 합쳐서 처리할 수도 있다.
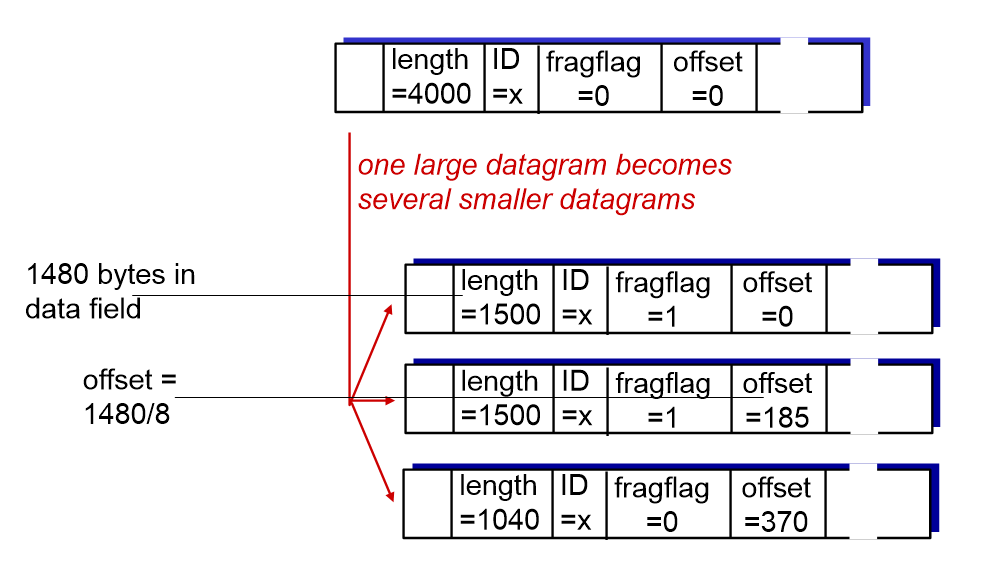
4000bytes의 datagram이 있고 link의 MTU가 1500bytes 라고 하자. 각각의 영역들을 살펴보자.
1. length : MTU가 1500byte이니 1500byte만큼 잘리게 되었다. 그런데 3개의 datagram의 length의 합이 1500+1500+1040=4040으로 4000bytes보다 40byte가 더 많다. 이것은 1개의 datagram(1개의 header)에서 3개의 datagram(3개의 header)가 되었으니 2개의 header가 추가된 셈이다. 하나의 header는 20byte이므로 2*20 = 40byte만큼 추가되었다.
2. ID : 모두 같은 flow에 있으니 ID는 같다.
3. fragflag : 1은 쪼갰다는 의미. 쪼개진 datagram에서 0은 이 datagrma이 쪼개진 것 중 마지막 datagram이라는 뜻이다.
4. offset : 0, 185, 370 bytes에서 정보가 시작된다는 뜻이다. offset은 payload/8이다. 1480(header 20byte제외)/8 = 185 으로 offset을 표시했다. 세번째는 +185해서 370부터 시작한다.
IPv4 addressing
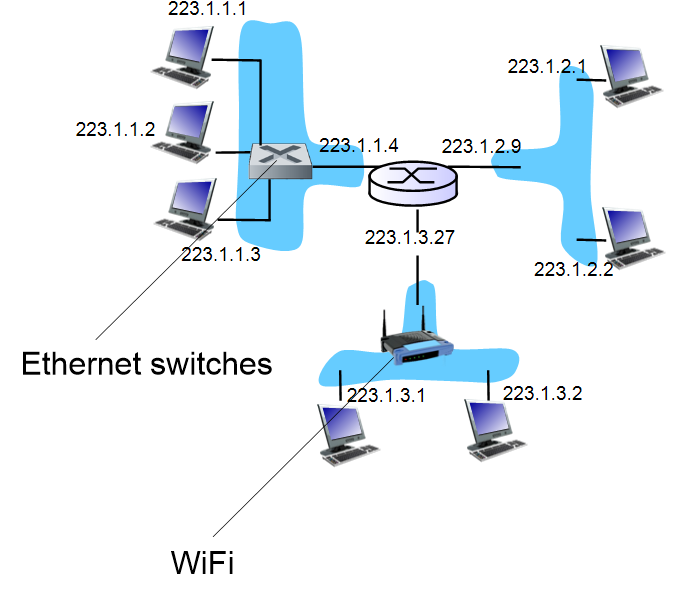
IP 주소 체계는 어떻게 되어있을까. IPv4는 32bit로, IPv6는 128bit로 이루어져 있다. host 또는 router interface는 전부 IP주소를 하나씩 갖고 있다. 예를 들어 IPv4의 IP주소 중, 233.1.1.1은 11011111 00000001 00000001 00000001 가 된다.
1. sub network : 위 그림의 파란색 영역. 이 sub network에서는 IP주소가 동일한 부분이 있다. 위에서는 223.1.1 이 하나의 sub network이고 223.1.2가 또 하나의 sub network이다.
2. Ethernet switch : 라우터와 다르다. ethernet switch는 sub network 내에 들어가는 것이다. 라우터는 이 sub network들을 연결시켜줄 때 사용한다.
3. WiFi : sub network 내에 Wifi로 연결되기도 한다.
WiFi와 ethernet switch는 Layer2이다. L2 스위치라고 불린다. 라우터는 L3이다.
Subnet과 host의 구분
위쪽 그림에서 왼쪽 subnet은 223.1.1까지 같다. 32bit중 24bit가 같고, 8bit가 다르다. 이 24bit는 subnet part로 subnet을 구별하고 나머지 8bit는 host part로 이것으로 host를 구별한다. 총 2^8(256)개의 host를 구분할 수 있는 것이다.
Subnet을 알려주기 위해 IP주소는 233.1.1.0/24 이렇게 표시한다. 즉 앞에서부터 24bit가 subnet을 의미한다는 것을 말해주는 것이다. 그리고 나머지 8bit가 host라는 것을 말해준다.

255.255.255 까지 subnetpart 0은 hostpart
CIDR (Classless InterDomain Routing)

subnet은 어떤식으로 IP address를 만들어 network를 형성할까?
CIDR은 IP주소의 법칙이다. IP주소를 만드는 체계에서 한가지 포인트는 Classless이다.
address format은 a.b.c.d/x 이다. x는 subnet의 주소개수를 표현한 것이다. 위 예시를 보면 23bit까지가 subnet part이다.
=> x구하기 시험문제 출제가능
ex) 255.0.0.0 => 8
255.128.0.0 => 9
255.192.0.0 => 10
DHCP (Dynamic Host Configuration Protocol)
IPv4의 사용가능한 ip주소가 줄어들었지만 DHCP를 이용하여 ip주소를 효율적으로 사용할 수 있다.
IP주소는 어떤식으로 부여 받을까?
IP주소는 제한적이여서 보통 집에서 사용하는 IP는 유동적으로 받게 된다. 이 유동주소를 할당하는 방법이 DHCP이다. plug-and-play 라고 말하는데, 컴퓨터를 꽂으면 주소를 가져온다는 뜻이다.
IP주소 부족하니까 network에 접속할 때 IP주소를 한 개 주는 방식이다. network의 모든 client는 항상 IP주소가 필요하지 않다. 이 때는 회수하고 다른 사용자에게 부여한다. (moblie 유저는 DHCP를 쓰지 않는다) , (DHCP는 응용계층 프로토콜이며 하위는 UDP)
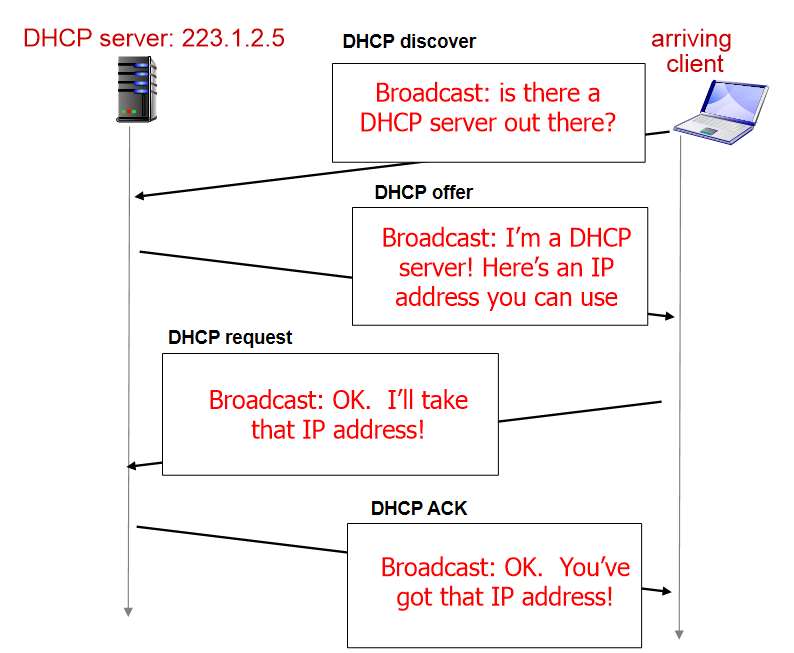
1. client가 "server 전체에" DHCP server가 있는지 물어봄. (이 때 destnation IP는 255.255.255.255.x로 보내는데, 이것은 물려있는 모든 network에 보내는 것)
2. DHCP가 msg 받고 내가 DHCP server이고, 너가 사용할 수 있는 IP주소가 하나 있다고 msg를 보낸다. 이 때도 dest IP는 255.255.255.255.x이다. 그리고 사용할 수 있는 IP주소를 적어준다.
3. client가 물려있는 server 전체에 OK. 내가 쓸게. 이 정보를 보낸다.
4. DHCP가 최종적으로 ACK를 보낸다.
이 과정의 모든 msg의 dest IP는 255.255.255.255.x이다.
DHCP는 보통 먼저 요청한 client에게 주소를 제공한다. 이 때 주소는 first-hop router의 주소를 준다. DNS server에 대한 IP주소, network mask도 알려준다. 이러한 정보들을 알아야 network에 접속할 수 있기 떄문이다.
ICANN (Internet Corporation for Assigned Names and Numbers)
글로벌 기구인 ICANN에서 IP 주소, DNS를 관리한다.
ex) 학교에서 IP주소를 산다면 Class B가 될것이다. Class A는 Host가 너무 많아 노는 경우가 발생하고 Class C는 Host가 너무 적다.
NAT (Network Address Translation)
배경: 사용 중인 IPv4는 32bit로 표현할 수 있는 IP주소의 개수가 2^32개인데, 이것으로 전세계의 모든 host를 커버하지 못한다. 4~5년 전에 ICANN은 IP주소가 고갈되었다고 발표하였다.
그래서 IP주소체계를 바꿔서 IP주소를 64bit로 표현하는 IPv6로 사용하자고 하였다. 그런데 이것은 20년 전부터 존재했으나 잘 되지 않고 있다. 2010년 되기 전에도 한창 중국이 커지면서 IP주소 부족 문제가 심각해졌다. 중국에서 IPv6로 가자는 주장이 강했다. 인터넷을 주도하고 있는 나라가 미국인데, 미국은 IP주소를 이미 충분히 가지고 있었기 때문에 급하지 않았다. IP주소의 상당부분을 미국이 가지고 있다. 여기에 NAT이라고 하는 기술이 도입되면서 IP주소 부족문제가 어느정도 해결되어서 IPv6에 대한 절실함이 줄어들었다.
우리나라에서도 NAT이라는 기술을 많이 쓴다. LTE를 사용하는데도 IP가 필요하다. 우리나라의 LTE가입자가 2천만명 될텐데 IP주소를 어떻게 감당할까? 통신사에서 보유하고 있는 IP를 이용하여 NAT를 사용한다.
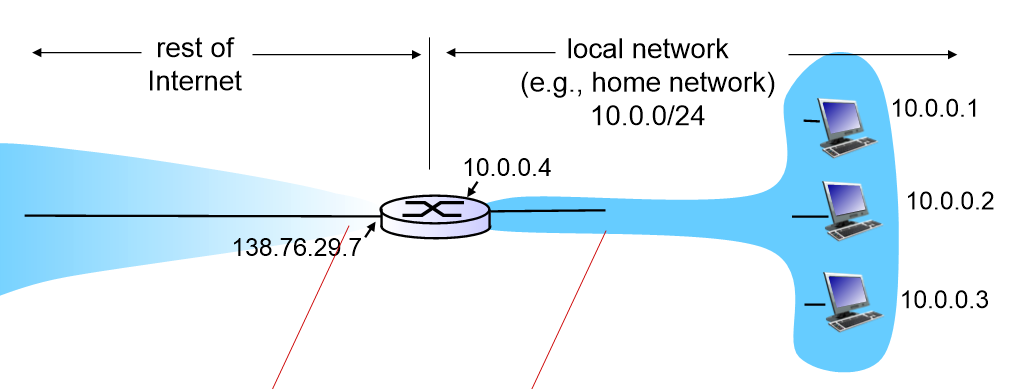
만약 138.76.29.7이라는 IP주소가 있고, 이 IP를 필요로 하는 사람은 3명이라고 하자. local network(내부망)에서 임의의 IP주소(10.0.0.1, 10.0.0.2, 10.0.0.3)를 부여한다. 실제 네트워크의 IP주소와 겹치면 안되니 내부망에서만 사용한다. 실제 네트워크로 나갈때는 138.76.29.7로 다시 변환해서 나간다. 내부망의 host들은 transport layer의 port number로 구분될 수 있다.
정리하자면, 바깥 네트워크에서는 내부망에서 무슨일이 일어나도 신경 안 쓴다. 단지 바깥 네트워크는 IP주소와 port number를 보고 주고받을 뿐이다. 그리고 내부망에서는 각 호스트들은 임의 IP를 부여받고, 이 임의IP와 port number로 host들을 구분하는 것이다. (port number와 임의 IP를 기록해놓은 table은 라우터가 가지고 있다. 이 table을 이용해 port number를 보고 임의IP에 해당하는 host를 찾아갈 수 있는 것이다.)
우리나라의 LTE, 5G 모두 NAT방식을 사용하고 있다.
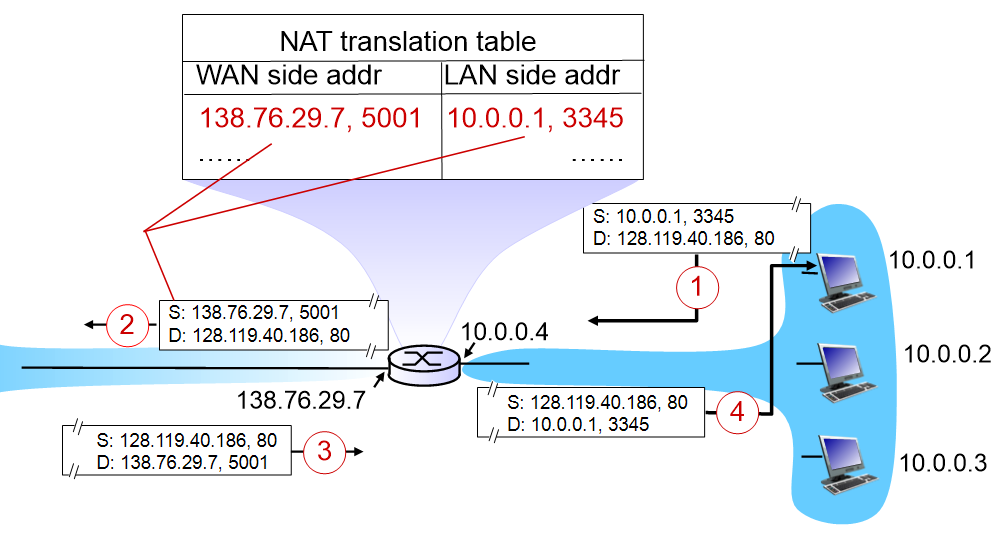
바깥으로 나갈때는 138.76.29.7을 사용하고, 내부망에서는 임의 IP를 부여받은 상황.
1. 10.0.0.1 host가 datagram을 보낸다. 이때 des IP는 128.119.40.186이고, port number는 80이다.
2. NAT router가 이를 변환해준다. des IP는 그대로 두고, source IP는 임의IP에서 원래 IP로 바꾸고, 임의로 할당하게 되는 port number로 변환한다. 그리고 이것을 table에 업데이트한다.
3. 이 datagram을 받은 server는 다시 source IP주소로 datagram을 보낸다.
4. NAT router에서는 des IP주소와 port number를 table과 비교해 다시 변환하여 내부망으로 보내준다.
NAT에 대한 논쟁
- 라우터에서 Layer 3 processing을 해야하니 오버헤드가 생길 수 있다.
- IPv6를 사용하면 완전히 해결 되는데, NAT은 어찌보면 꼼수를 사용한 것이다.
- IP주소가 중간에 바꿔치기 되었기 때문에 인터넷의 철학 중 end-to-end argument를 어긴 것이다.
- P2P가 동작을 하지 않는다. NAT 라우터가 어떻게 설정되었느냐에 따라 달라질 수 있지만, 일반적으로 P2P가 동작을 안한다. P2P는 동등한 관계로 동작하는데 내부망을 한번 거쳐야 하기 때문에 P2P가 동작하는데 문제가 생긴다.
IPv6
32bit가 부족할 것에 대비해 나온 것이 64bit를 사용하는 IPv6이다.
더불어 IP버전을 바꾸면서 기존 IPv4의 header에서 필요없는 부분을 떼고, 진짜 사용할 것만 남겨 header format을 깔끔하게 바꾸었다.
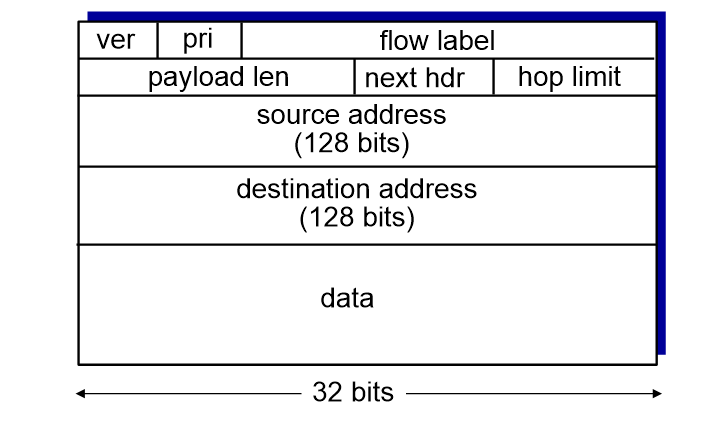
- Version (ver): 버전을 나타낸다. 4비트로 표시된다.
- Priority (pri): 우선순위를 나타낸다. 이 필드는 4비트로 표시되며, 패킷의 우선순위를 결정하는 Quality of Service(QoS)와 관련된 정보를 제공한다.
- Flow Label: 플로우 레이블을 나타낸다. 이 필드는 20비트로 표시되며, 특정 플로우나 트래픽 스트림을 식별하는 데 사용된다. 특정 플로우의 패킷들은 동일한 플로우 레이블 값을 갖게 된다.
- Payload Length: 페이로드(데이터)의 길이를 나타된다. 이 필드는 16비트로 표시되며, 헤더와 데이터(페이로드)를 포함한 전체 패킷의 길이를 바이트 단위로 나타낸다.
- Next Header: 다음 상위 계층 프로토콜을 나타낸다. 이 필드는 8비트로 표시되며, 패킷의 상위 계층 프로토콜을 식별한다. 예를 들어, 값이 6인 경우 TCP를 나타낸다.
- Hop Limit: 네트워크를 통과할 수 있는 최대 홉(Hop) 수를 나타낸다. 이 필드는 8비트로 표시되며, 홉 수는 패킷이 라우터를 통과할 때마다 감소한다. 홉 리밋 값이 0이 되면 패킷은 폐기된다.
- Source Address: 출발지 IP 주소를 나타낸다. 이 필드는 128비트(16바이트)로 표시되며, 송신자의 IP 주소를 식별한다.
- Destination Address: 목적지 IP 주소를 나타낸다. 이 필드는 128비트로 표시되며, 수신자의 IP 주소를 식별한다.
- Data: 포함된 실제 데이터(페이로드)를 나타낸다. 이 필드는 헤더 이후의 나머지 부분을 차지하며, 전송하고자 하는 실제 데이터가 포함된다. IPv6는 IPv4와 달리 헤더의 길이가 고정되어 있으므로, 데이터의 위치와 크기를 추론할 수 있다.
header의 크기는 40byte로 딱 두배 늘어났는데, 표현할 수 있는 IP주소의 값은 어마어마하게 많아졌다. 안 쓸 이유가 없어보이는데 왜 안 쓸까?
IPv6를 구현하려면 라우터에 기능이 들어가야 한다. 이것은 비용이 많이 들어간다. 그리고 전세계 모든 라우터를 교체하는 건 현실적으로 매우 힘들다.
Tunneling
전세계 모든 라우터를 한번에 IPv6로 바꾸는 것을 불가능하다. IPv4와 IPv6가 공존해야 하는 상황이 올 것이다. 이에 대비하여 "Tunneling"이라는 방법을 고안했다.
(IPv4 datagram 내에다가 IPv6 datagram을 집어넣어서 IPv4 형식으로 처리할 수 있게 하는 방법)
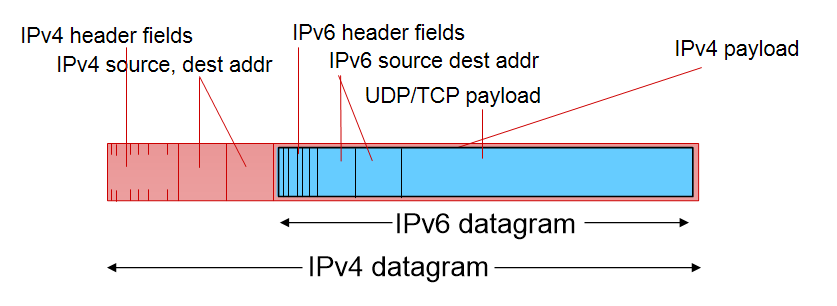
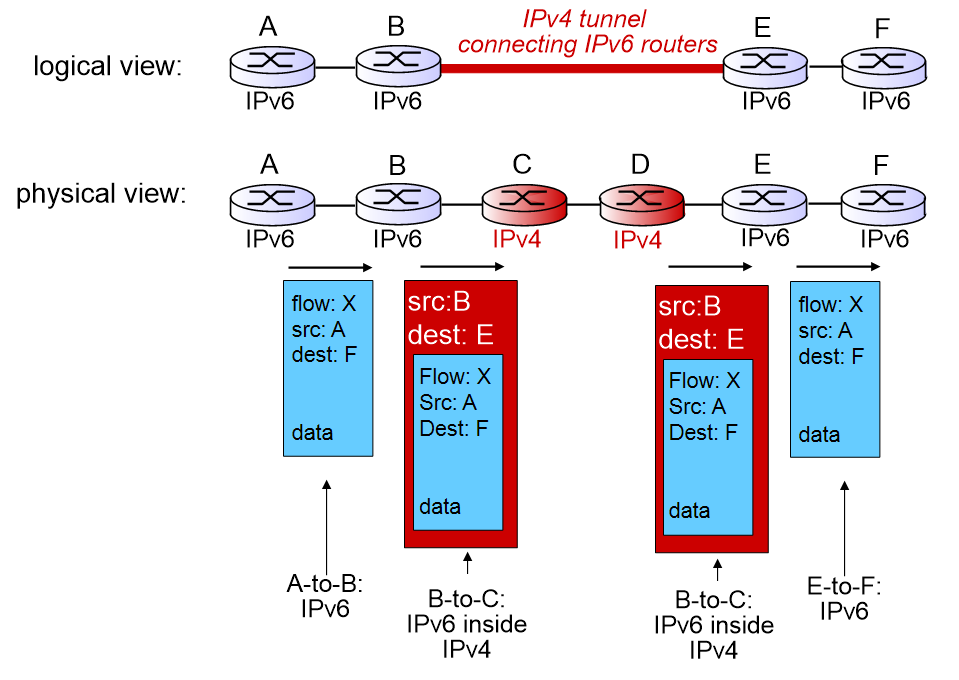
IPv6의 datagram을 보내는데, ABEF는 IPv6를 처리할 수 있고 CD는 처리하지 못하는 상황.
이 때 CD 라우터를 지날 때 IPv4의 header를 붙여서 IPv4인 것처럼 보내서 통과하게 한다.
B에서 C로 보낼 때, IPv6 datagram에 IPv4 header를 집어넣고 source IP는 B로, destination IP는 E로 설정해서 전송한다. 이렇게 C와D 라우터는 정상적으로 처리 후, E로 보낸다. E가 받았을 때는 이것을 읽고 IPv4 header를 떼버린다.
'CS > 컴퓨터 네트워크' 카테고리의 다른 글
| Chapter 6 링크계층 (The Link Layer and LANs) (2) | 2023.06.06 |
|---|---|
| Chapter 5 네트워크 계층 (The Control Plane) (0) | 2023.06.05 |
| Chapter 3 전송계층 (Transport Layer) (0) | 2023.04.18 |
| Chapter 2 어플리케이션 계층 (Application Layer) (0) | 2023.04.10 |
| Chapter 1 컴퓨터 네트워크와 인터넷 (0) | 2023.04.04 |




댓글